-
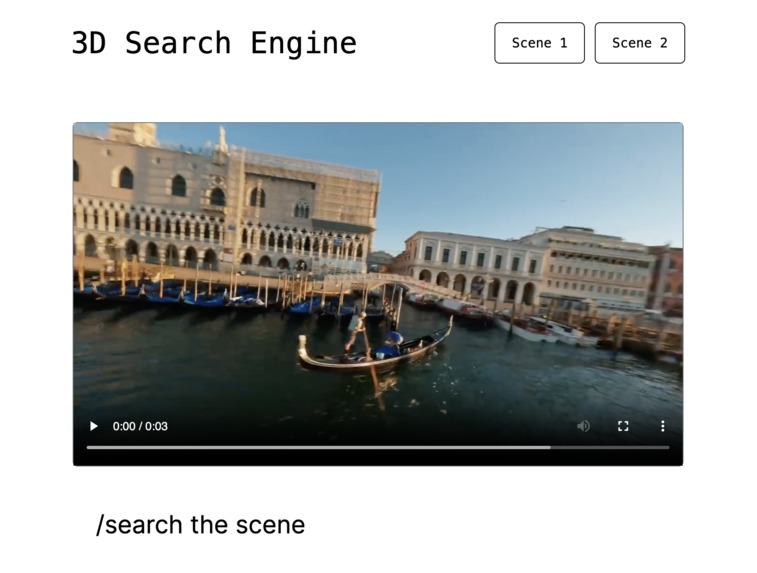
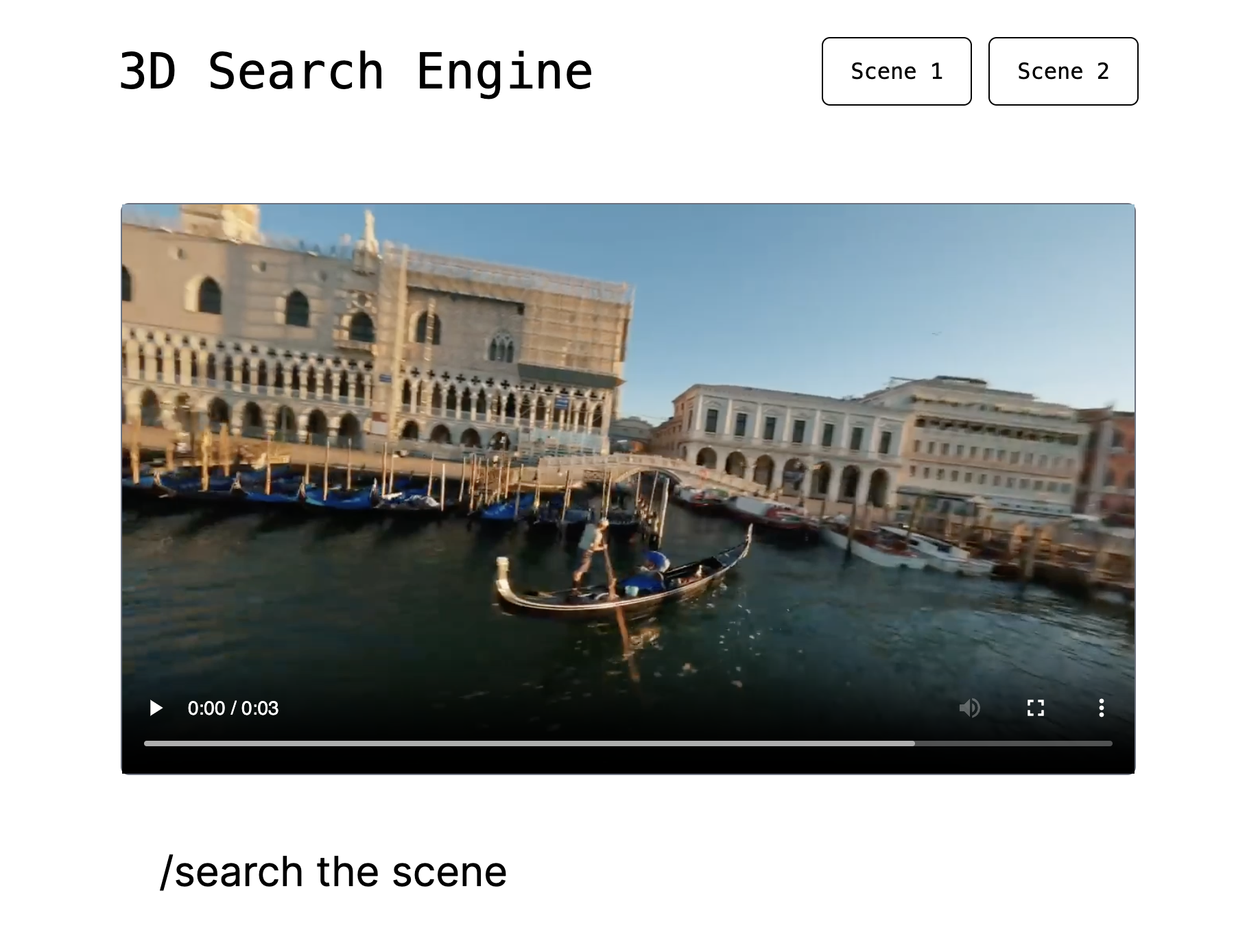
Our interactive UI for semantic search
-

Zero-shot search term 'Candle'

Inspiration
Fueled by recent advances in 3D reconstruction, we are seeing a new paradigm emerge where we are able to construct unified representations of our reality--digital twins of sort. Being able to understand our reality is vital to decision making. In high pressure changing environments, being able to analyze and process a lot of semantic information quickly and efficiently could be the difference between life and death. This inspired us to envision what the future of 3D understanding could look like in next generation intelligence, and how we could leverage foundational models to build general purpose reasoning engines at the tactical edge.
What it does
3D Search lets you perform semantic search in 3D spaces.
Precisely, we first allow users to input a sequence of 2D images of a scene, and consequently reconstruct the 3D geometry of that space. Secondly, it manages to embed semantic meaning onto the 3D geometry allowing us to perform a semantic search through that space.
How we built it
We built it by leveraging a handful of machine learning models and research papers including NeRF, Gaussian Splatting, CLIP, LERF, LangSplat, Level of Gaussians, and more.
At a technical level this is what goes on under the hood: We use the training images extracted from source videos to construct a simple point cloud using structure-from-motion (SfM) and to extract the camera extrinsics and intrinsic parameters. From this initialization, we then perform a ray-casting strategy to project the individual pixels from each source image onto the 3D space. We then train a simple 8-layer MLP to essentially memorize what the color and density values of space are at the particular 3D points we have in the training dataset. This lets us train a radiance field which can allow us to perform novel view synthesis and look at the scene from different angles. Now we can do this with color successfully (done by NeRF, GaussianSplatting, other papers).
How can we embed semantics into it though? We can leverage CLIP which serves as a joint embedding space between language and images. We can use the CLIP features to supervise a semantic field and then perform queries by doing a vector similarity search on the learned feature field. This is essentially the same pipeline used in vector databases for text semantic search just using a joint embedding space between language and vision which allows us to perform this search on images. Consequently, by leveraging the volumetric reconstruction techniques of NeRF we are able to lift this 2D semantic search onto 3D and greatly improve the accuracy. Why is it better in 3D than 2D? From first principles it is clear that allowing a new dimension / degree of freedom provides great boost in flexibility and expressivity. More precisely, it improves the variance and reduces the bias of the training data and consequent training process.
Challenges we ran into
We had a hard time finding footage of the battlefield that was un-edited. You can find a lot on youtube but it all tends to be trimmed to less than 5 seconds long, suffers from compression, and has watermarks. Hence, we opted for testing our method on our own captures at Shack15
Accomplishments that we're proud of
We are proud that we even got it running in the timeframe of the hackathon, and are quite surprised with the precision and accuracy of our method.
What's next for 3D Search
We will attempt to scale up to city-level data and perform a semantic query across all of san francisco. Moreover, you can gain certain insights from querying the search engine and analyzing the results but the ideal thing would be for the engine to tell you what to look for itself, surfacing important things worth taking a look at.
Built With
- amazon-web-services
- clip
- gaussiansplatting
- lerf
- nerf
- python

Log in or sign up for Devpost to join the conversation.