-
-

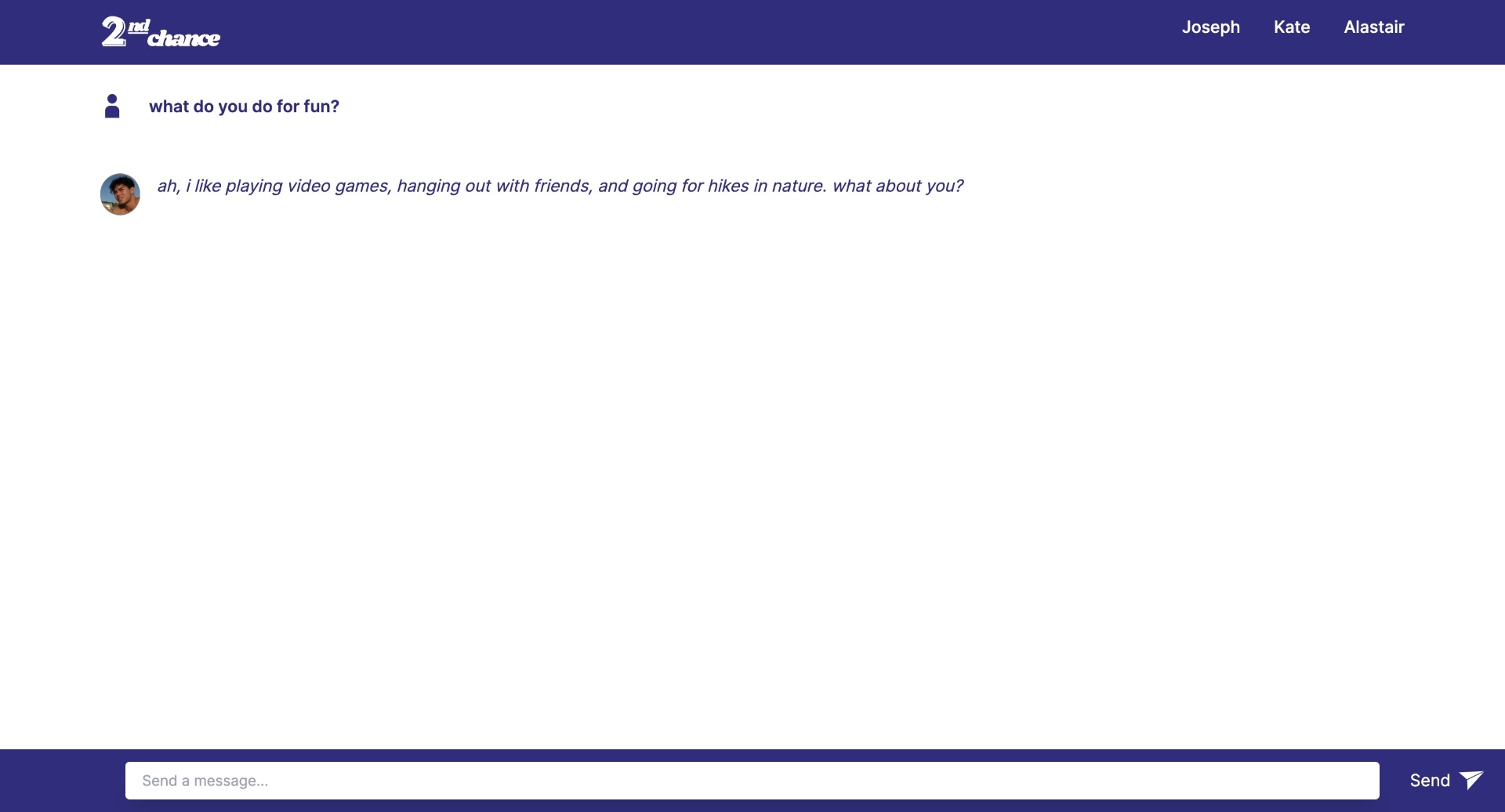
Conversing with Joseph on 2nd Chance text
-
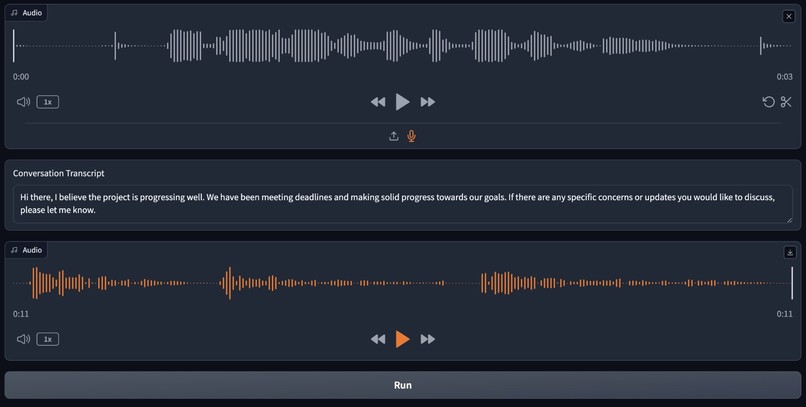
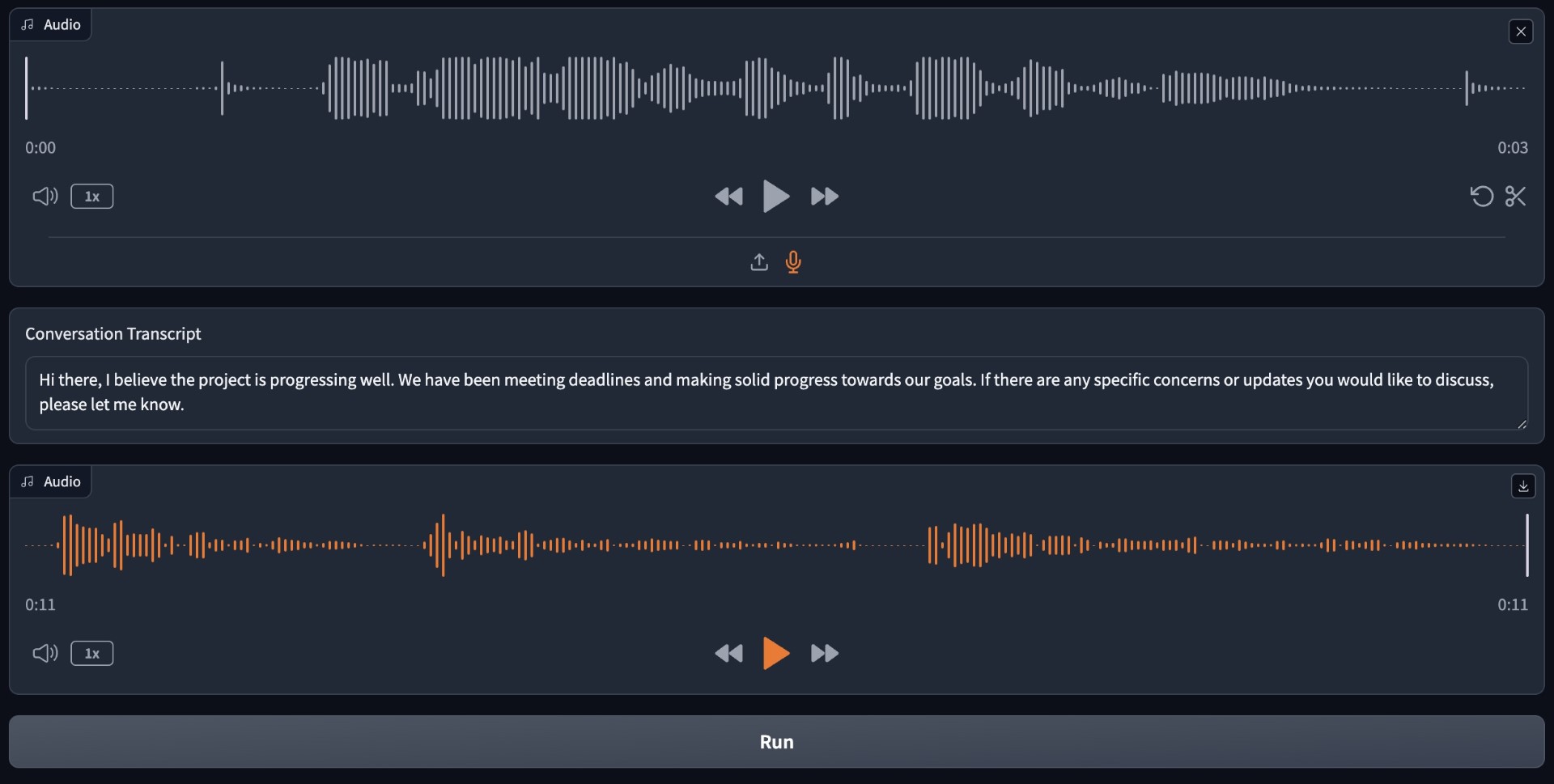
Talking with Kate on 2nd Chance voice
Inspiration
We've all wished that we would've talked more to people in person when we had the chance - whether you need them to answer an urgent question, your schedules are too busy for frequent phone calls, or your loved one has passed on, 2nd Chance was built to let you talk to a loved one in real time. Created with the next generation of senior citizens in mind, we wanted to take advantage of the abundance of video and text records people will have of each other while implementing senior-friendly UI. We were excited to use new APIs and learn vector embedding techniques to accomplish our goal of simulating an individual based on their records.
What it does
2nd Chance first requires a user to submit audio and/or text records of their loved one to get a sense of how they talk. Then, taking either a written or spoken input from the user, the software processes the input and compares it to the records on hand with vector embedding. If the user's input is spoken, it uses OpenAI's Whisper API to transcribe the message into written text. Using ChatGPT to synthesize the existing responses in the records, the software predicts a response to the user's entry. If the user's entry was spoken, we reproduce their loved one's voice using ElevenLab's API so they can speak their response back to the user.
How we built it
The frontend and backend of our web application was built with Next.js and Convex, respectively. We specifically took advantage of Convex’s Vector Search, Server Functions, and Database features. Our AI simulation was powered by OpenAI’s Chat-GPT model and Vector Embeddings (for Vector Search) were provided by OpenAI’s embedding model. We use Gradio for our speech-to-speech interface, Whisper for audio transcription, and ElevenLabs for voice cloning. Finally, we used Tailwind CSS and Flowbite for overall styling.
Challenges we ran into
Our decision to use Next.js and Convex caused some difficulty when we attempted to integrate our speech-to-speech software. We were required to implement that software in separate Python files, but then we lost access to our Vector Search software (through Convex). In the end, both speech-to-speech and text-to-text software were integrated onto the web application with Vector Search.
Accomplishments that we're proud of
We're proud of being able to produce an audio response in the voice of the user's loved one by using ElevenLab's API. It was exciting to get to implement a variety of APIs we hadn't used before to improve our functionality. Another accomplishment was getting the vector embedding to work to help generate responses specific to the user. We’re primarily proud of getting to help people from multiple backgrounds in their day to day lives.
What we learned
We learned about implementing APIs using their documentations, as well as seeing how many APIs are out there and the value of open source code. We also learned that we should plan out all the technologies we want to use so that we can ensure they can be integrated properly. Lastly, we saw how much we could code we could learn and put together in the span of 36 hours.
What's next for 2nd Chance
We want to continue to improve the integration of the AI speech-to-speech technology with the front-end design of our website to increase usability and design. We also want to ensure that our user’s text logs and/or audio recordings that they submit as reference points are well encrypted to protect their privacy. It would be nice to also increase functionality for non-English speakers to make our technology more accessible for diverse populations.
Built With
- convex
- gpt
- next.js
- openai
- python
- react
- typescript





Log in or sign up for Devpost to join the conversation.