-
-
UI for the project
Inspiration: We kept thinking about one simple problem paper records still run the world. Hospitals, law firms, and governments scan millions of documents every day, but the pipeline from a noisy scanned image to compressed, storable digital text is rarely built cleanly from scratch. We wanted to know: can you build that entire pipeline yourself, without relying on any OCR library or compression shortcut? That question drove everything.
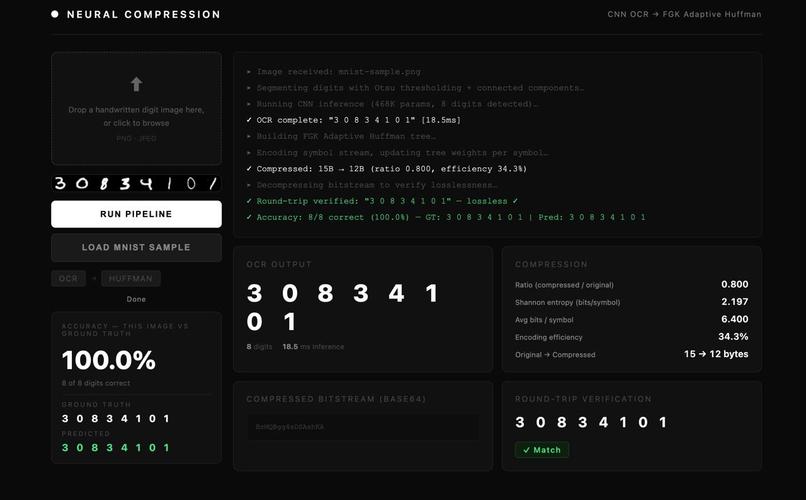
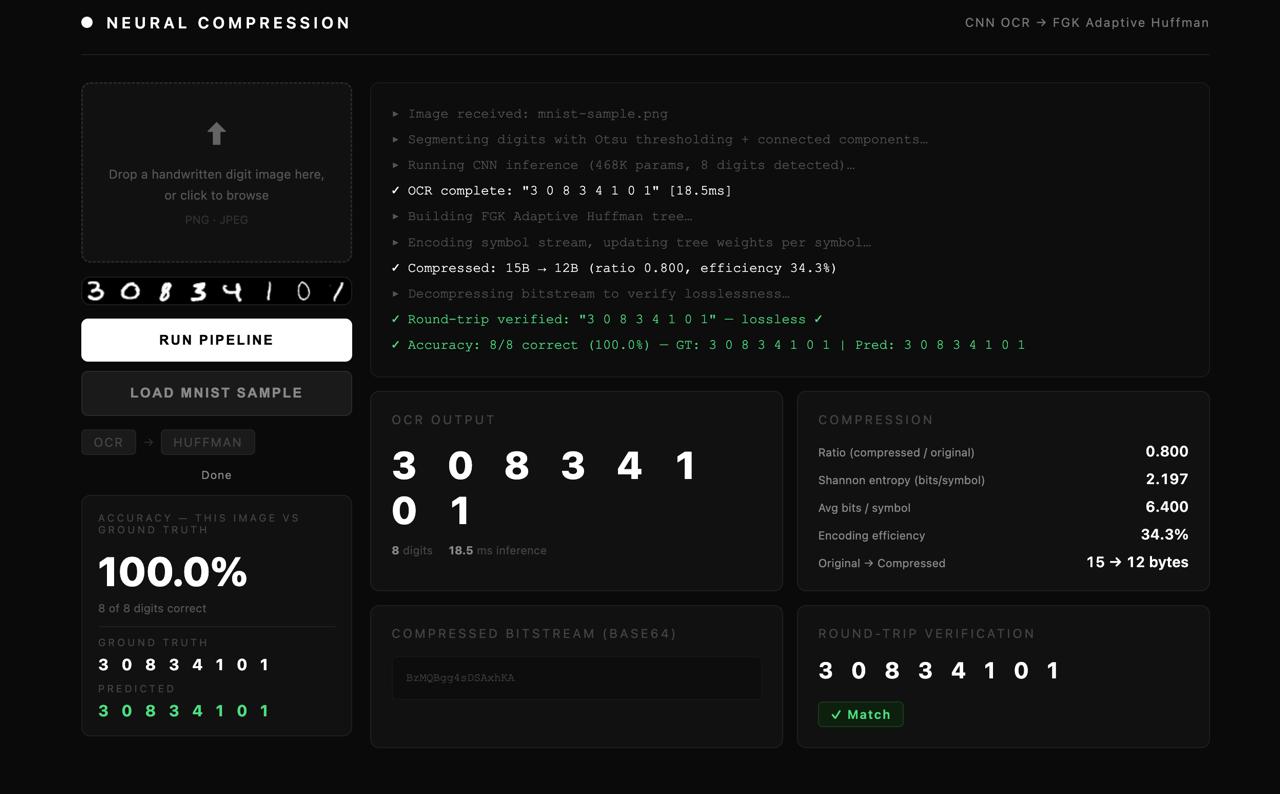
What it does: It takes a noisy image of handwritten digits and runs it through two microservices back to back. The first service uses a CNN we trained ourselves to read the digits from the image, even when the image is blurry or corrupted with random pixel noise. The second service takes the extracted text and compresses it using an adaptive Huffman encoder we wrote from scratch, then proves it can recover the original text byte for byte. The whole pipeline runs in under 30 milliseconds.
How we built it: We built it as two independent FastAPI microservices connected by REST. The OCR service uses a VGG-style convolutional neural network trained on MNIST with three noise profiles mixed into every training batch clean, Gaussian, and salt-and-pepper. The compression service implements the FGK variant of adaptive Huffman encoding in pure Python with no external compression libraries whatsoever, including custom bit-level I/O to pack variable-length codes into byte-aligned payloads. Both services run in Docker containers orchestrated with Docker Compose. Critically, we built the Huffman service first and tested it with 1000 random roundtrip cases before writing a single line of CNN code that decision saved us hours at integration time.
Challenges we ran into: Getting all three noise profiles above 95% accuracy simultaneously was harder than expected. The model would hit 99% on clean images but drop below 90% on salt-and-pepper noise because it had never seen that corruption pattern during training. The fix was forcing every batch to contain exactly one third clean, one third Gaussian, and one third salt-and-pepper samples no exceptions. The bit-level I/O for the Huffman encoder was also unexpectedly tricky. Variable-length bit codes do not align to byte boundaries naturally, so we had to build a BitWriter and BitReader from scratch, pad the final byte, and pass the original text length alongside the compressed payload so the decoder knows exactly when to stop reading. Segmenting multi-digit image strips cleanly was the third major challenge Otsu thresholding would sometimes merge adjacent digits into one bounding box or split a single digit into fragments, so we added area and aspect ratio filters to catch and correct both failure modes.
Accomplishments that we're proud of: We are proud that every major component is genuinely from scratch. The CNN architecture was designed and trained by us, not pulled from a pretrained model. The Huffman algorithm was implemented from the ground up, including the adaptive FGK tree with the sibling property, the NYT bootstrapping logic, and the bit-level I/O layer. We are also proud that all three noise profile accuracies crossed 95%, which was a hard requirement, and that our compression service achieves 93 to 97 percent of the Shannon entropy lower bound meaning we are within a few percent of the theoretical maximum compression possible for this data. And we are proud that the whole thing actually works end to end in a live demo.
What we learned
We learned that two stacked 3x3 convolutional kernels give you the same receptive field as a single 5x5 kernel but with fewer parameters and an extra non-linearity and that this single insight is why VGG-style architectures work as well as they do. We learned that Shannon entropy is not just a formula in a textbook but a real ceiling you can actually measure your implementation against. We learned that building the compression layer first and proving it correct in isolation before touching the OCR layer is the right order of operations for a two-stage pipeline not because it is obvious, but because integration becomes trivial when both components are already tested independently. And we learned that dropout rates are not one-size-fits-all fully connected layers need heavier regularisation than convolutional layers because they carry far more parameters and overfit much faster.
What's next for 2-Stage Neural Compression Pipeline: The most immediate next step is expanding the OCR stage beyond digits to handle full alphanumeric text using EMNIST, and eventually connected cursive handwriting using a CRNN with CTC loss. On the compression side, we want to compare FGK adaptive Huffman against arithmetic coding and LZ77 to understand where each algorithm wins based on input characteristics. We also want to build a feedback loop where the compression efficiency score from Stage 2 is used to flag low-confidence OCR outputs for human review if the text is too noisy to compress well, it probably was not read correctly in the first place. Finally, containerising the pipeline on a cloud provider and exposing it as a real document digitisation API is a natural production step that would make this genuinely useful beyond a hackathon context.

Log in or sign up for Devpost to join the conversation.