-
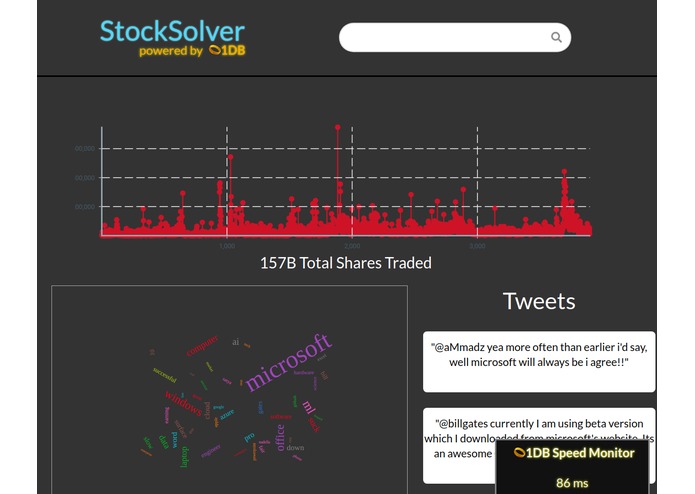
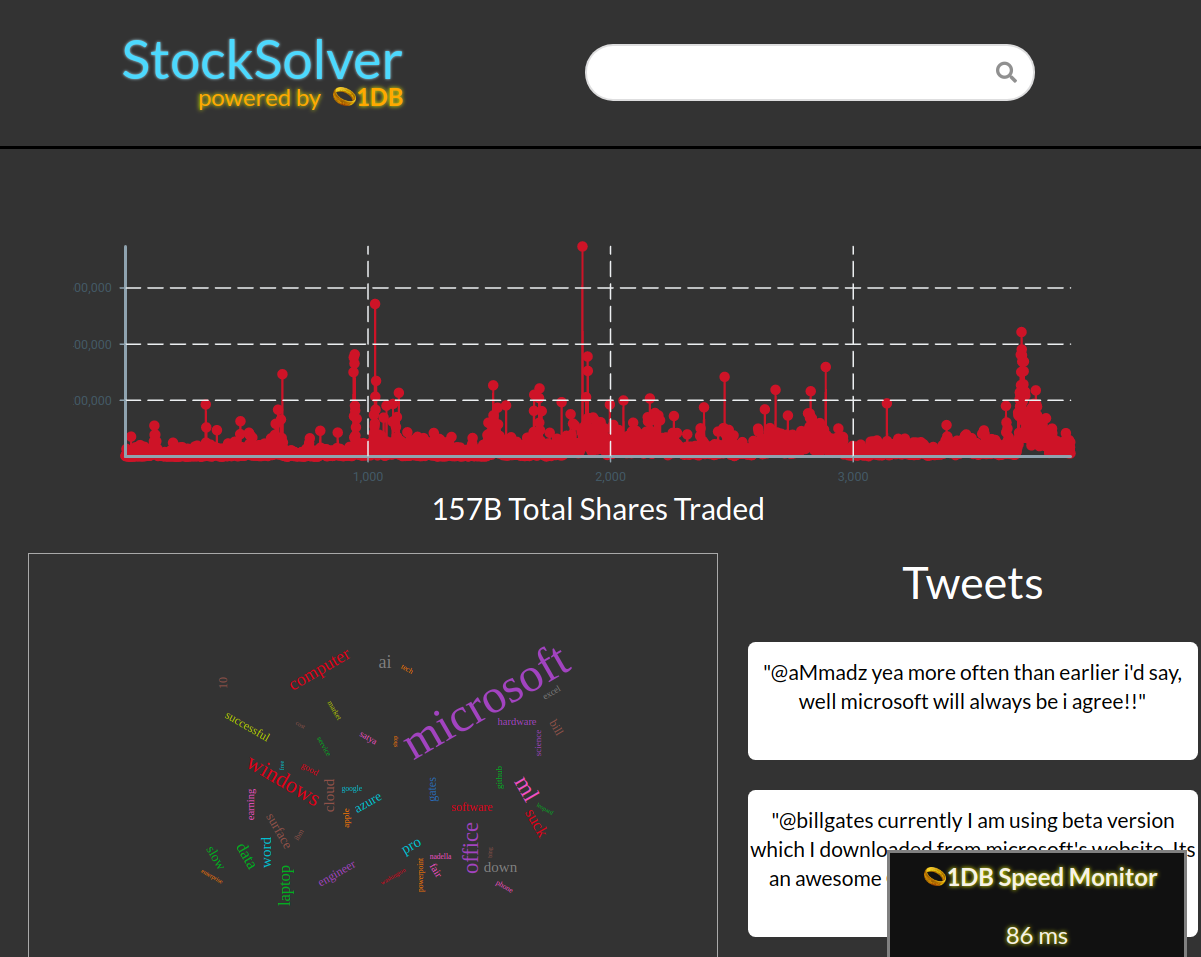
StockSolver powered by 1DB
-
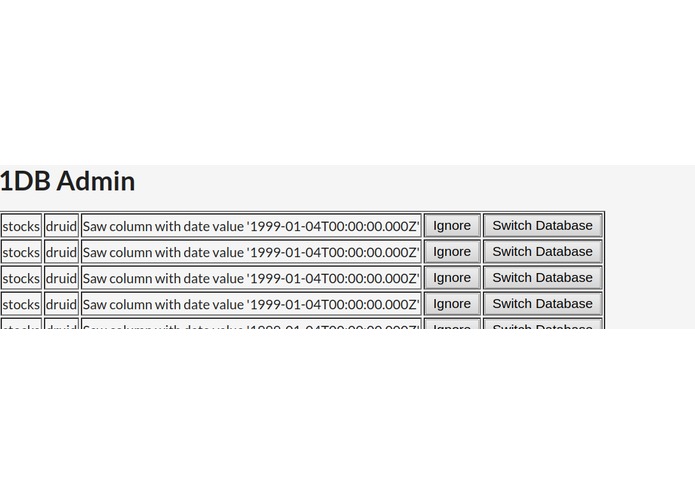
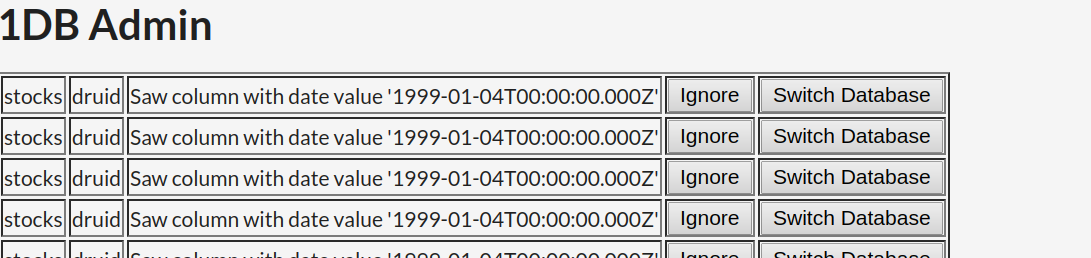
1DB admin page
-

Very high-level design
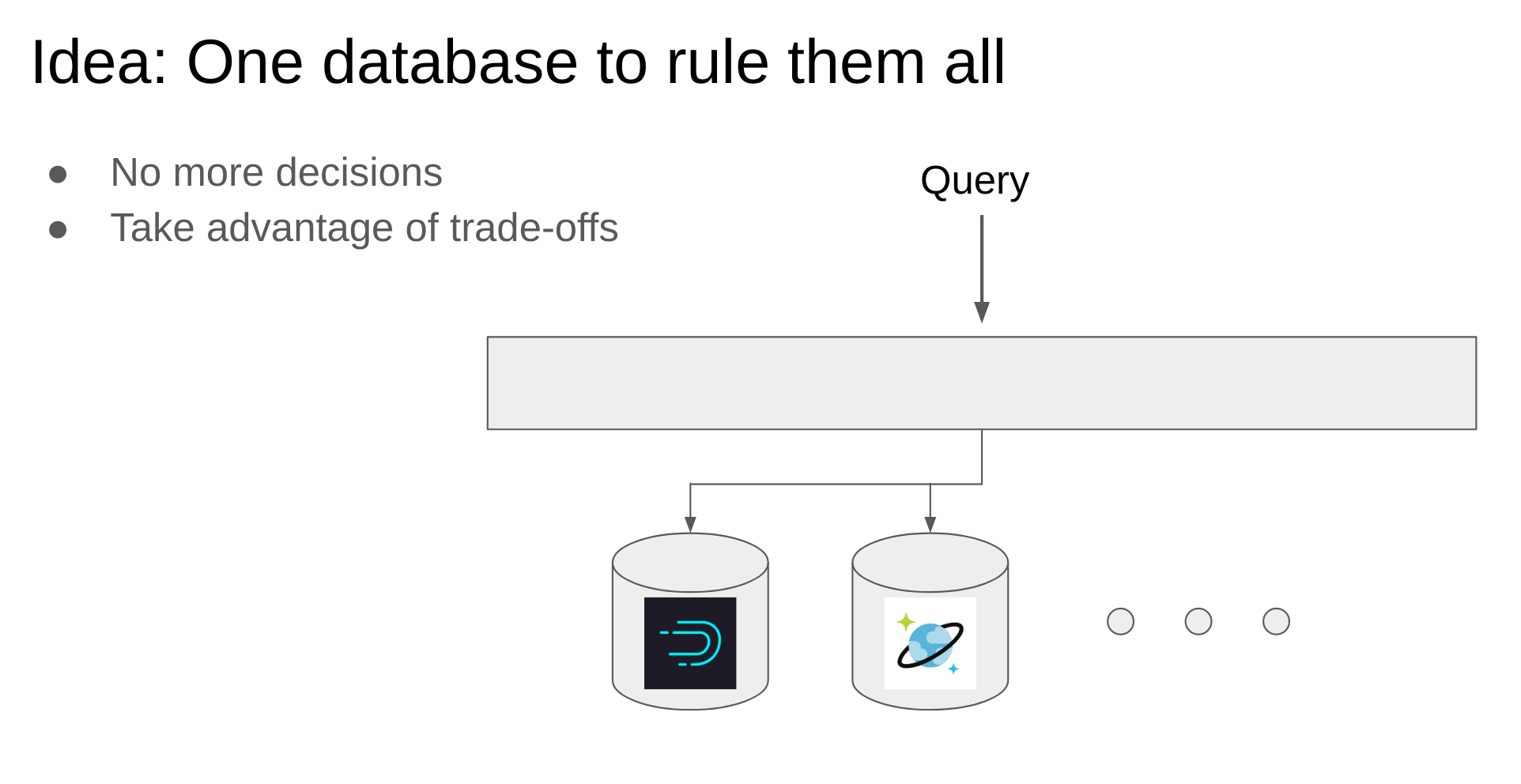
Inspiration
Databases are wonderfully engineered for specific tasks. Every time someone wants to add a different type of data or use their data with different access pattern, they either need to either use a sub-optimal choice of database (one that they already support), or support a totally new database. The former damages performance, while the latter is extremely costly in both complexity and engineering effort. For example, Druid on 100GB of time series data is about 100x faster than MySQL, but it's slower on other types of data.
What it does
We set up a simple database auto-selector that makes the decision of whether to use Druid or MySQL. We set up a metaschema for data -- thus we can accept queries and then direct them to the database containing the relevant data. Our core technical contributions are a tool that assigns data to the appropriate database based on the input data and a high-level schema for incoming data.
We demonstrated our approach by building a web app, StockSolver, that shows these trade-offs and the advantages of using 1DB for database selection. It has both time-series data and text data. Using our metaschema we and 1DB can easily mix-and-match data between Druid and MongoDB. 1DB finds that the time-series data should be stored on Druid, while MongoDB should store the text data. We show the results of making these decisions in our demo!
How we built it
We created a web app for NASDAQ financial data. We used react and node.js to build our website. We set up MongoDB on Microsoft's Cosmos DB and Druid on the Google Cloud Platform.
Challenges we ran into
It was challenging just to set up each of these databases and load large amounts of data onto them. It was even more challenging to try to load data and build queries that the database was not necessarily made for in order to make clear comparisons between the performance of the databases in differ use-cases. Building the queries to back the metaschema was also quite challenging.
Accomplishments that we're proud of
Building an end-to-end system from databases to 1DB to our data visualizations.
What we learned
We collectively had relatively little database experience and thus we learned how to better work with different databases.
What's next for 1DB: One Database to rule them all
We would like to support more databases and to experiment with using more complex heuristics to select among databases. An extension that follows naturally from our work is to have 1DB track query usage statistics and over time, make the decision to select among supported databases. The extra level of indirection makes these switches natural and can be potentially automated.
Built With
- azure
- cosmos-db
- druid
- node.js
- react
- typescript
- victory

Log in or sign up for Devpost to join the conversation.