-
-

COVID-SIM running on parameters fitted with real data through machine learning
-

CovidSIM fitted to data from south korea.
-
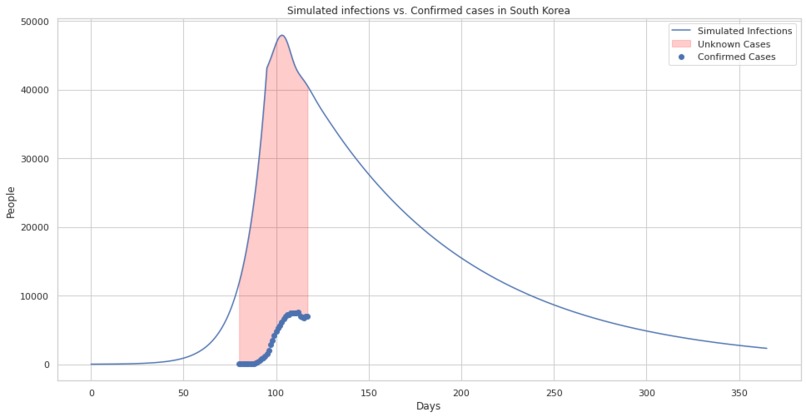
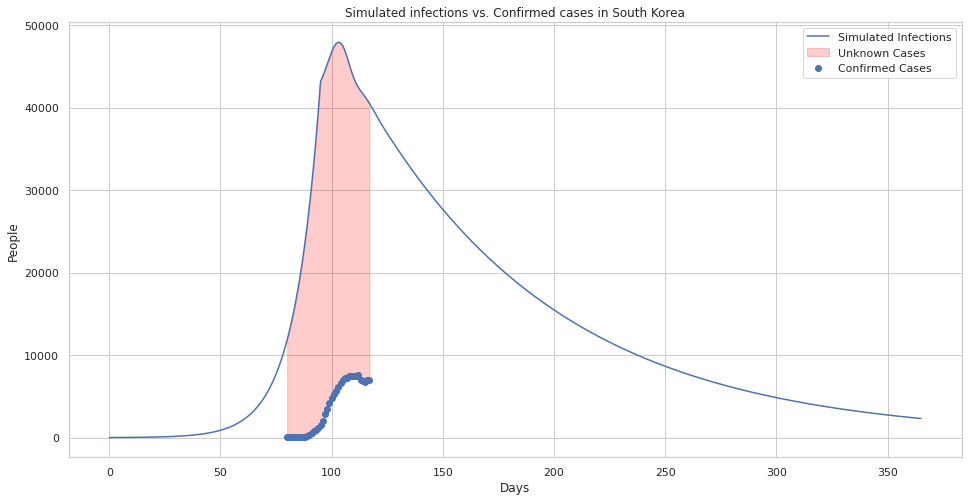
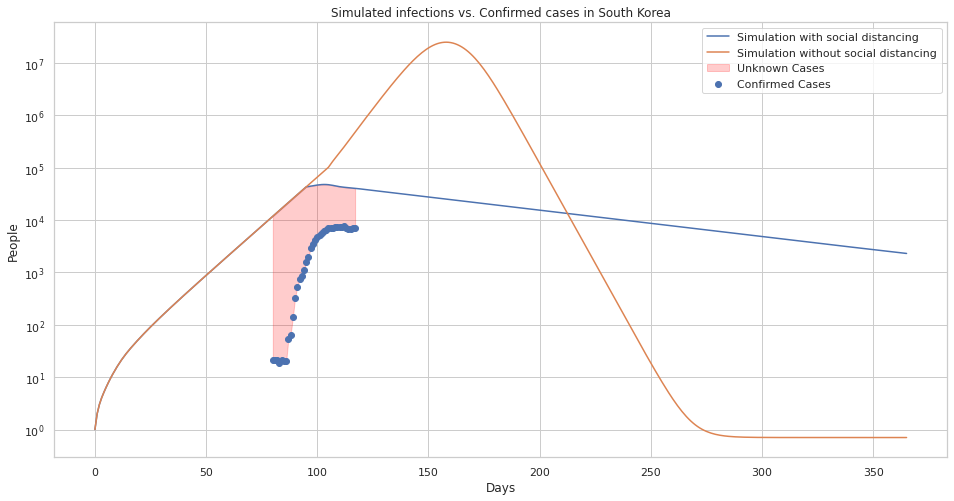
A comparison of confirmed cases in south korea and our simulated infections.
-
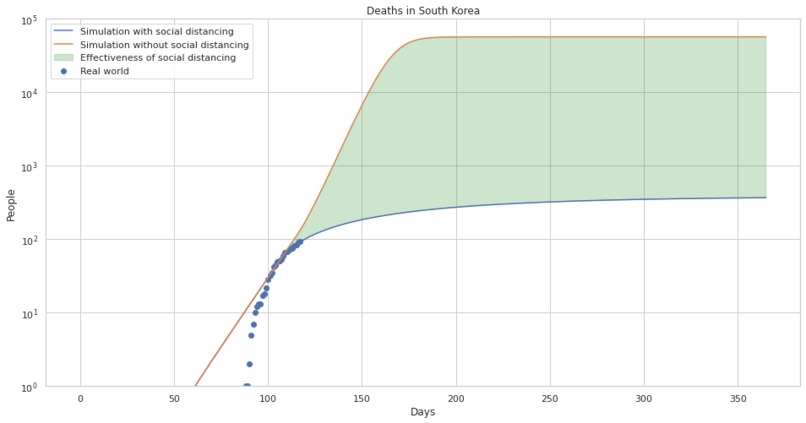
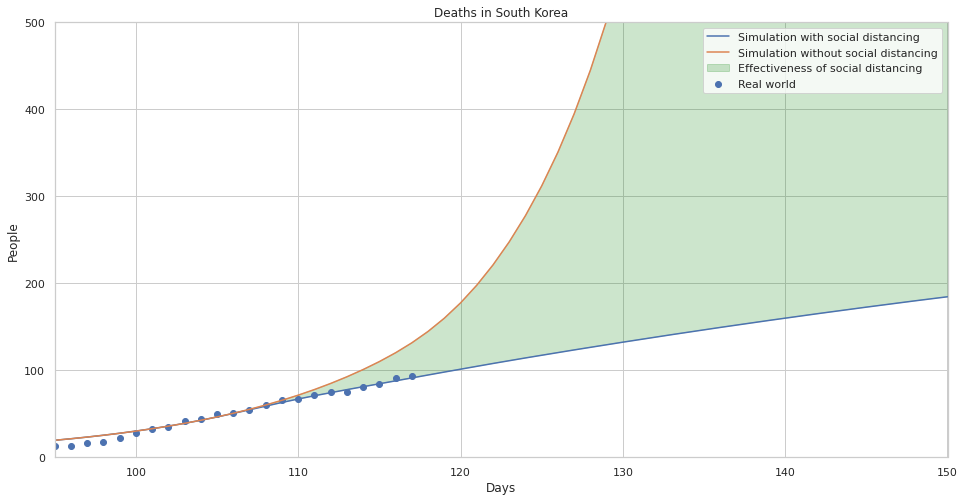
The effectiveness of social distancing in preventing death in south korea.
-
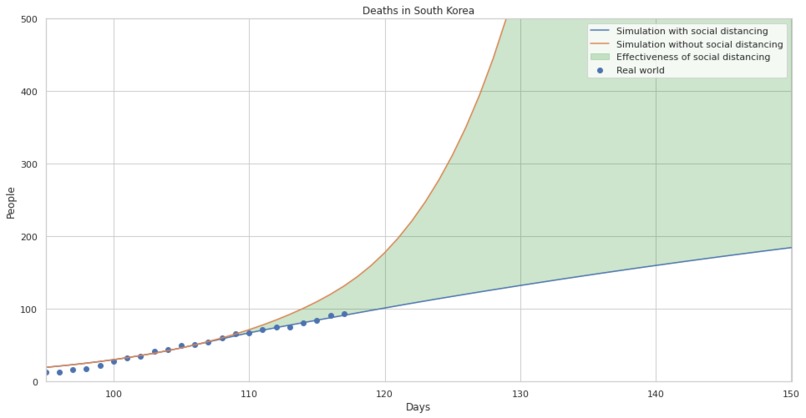
The effectiveness of social distancing in preventing death in south korea, zoomed to today.
-
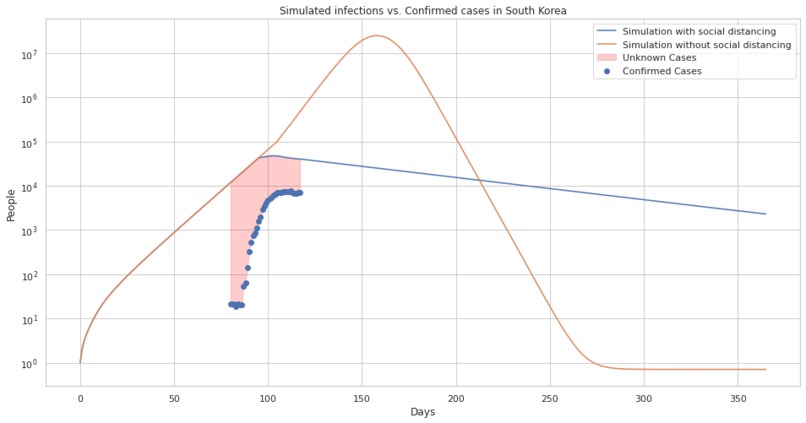
The effectiveness of social distancing in flattening the curve in south korea.
-
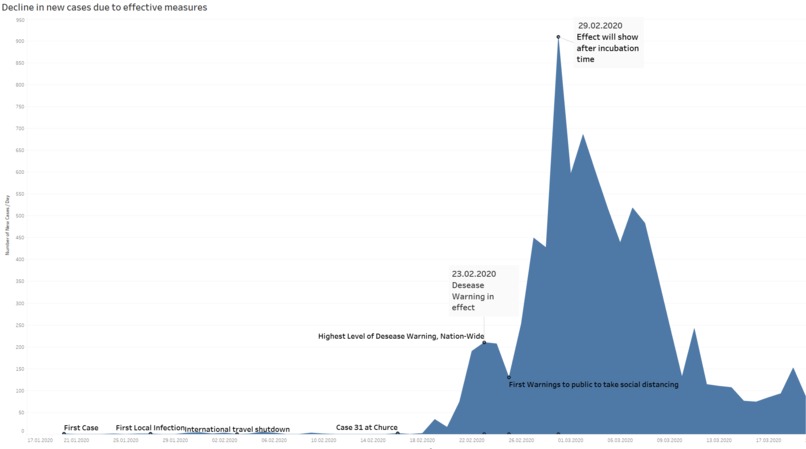
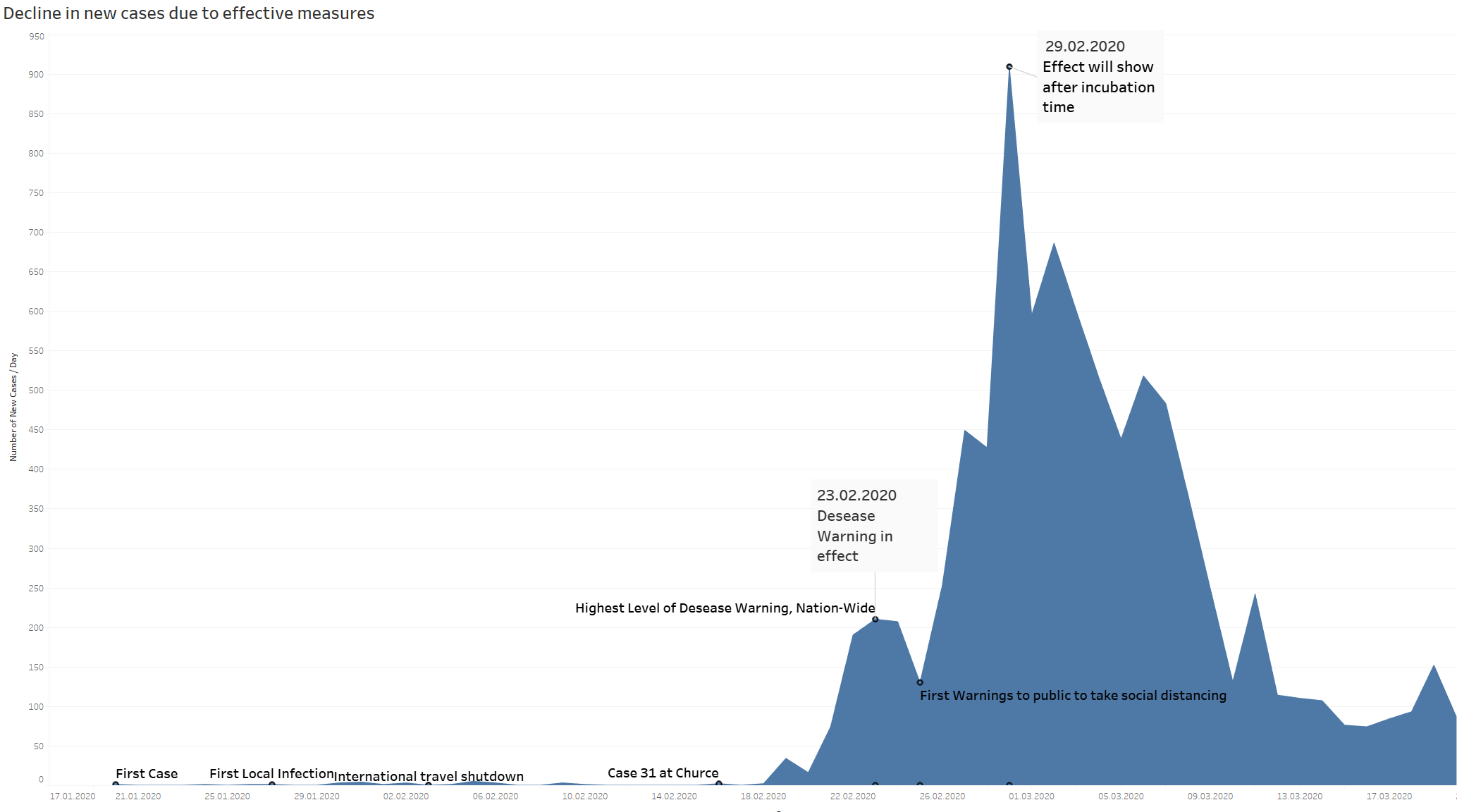
Effective detection, communication an spread prevention in south korea.
-
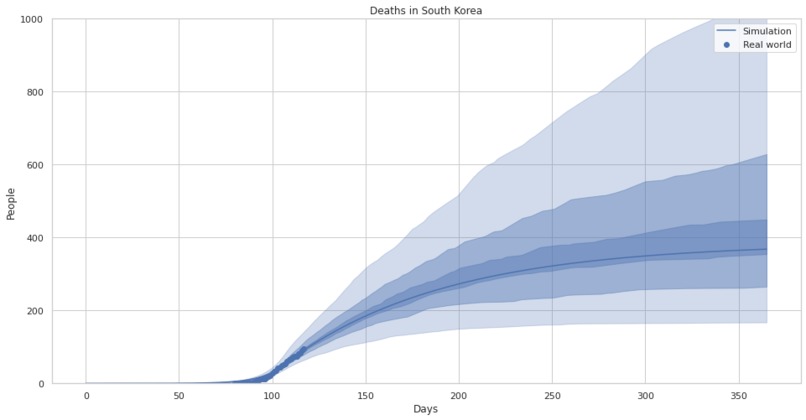
CovidSIM fitted to data from south korea with uncertainty estimates.
-
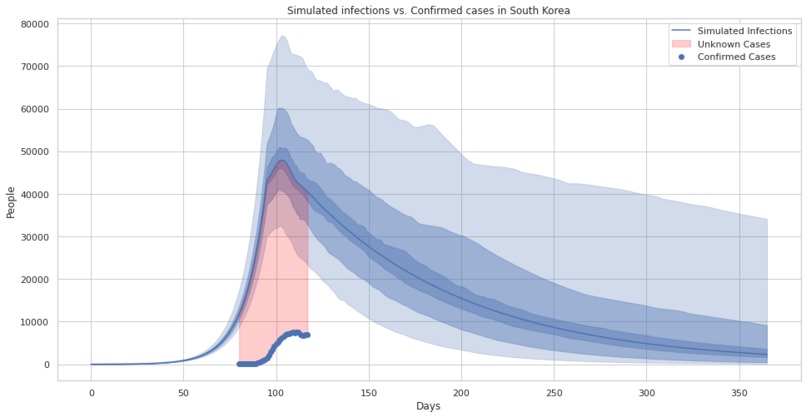
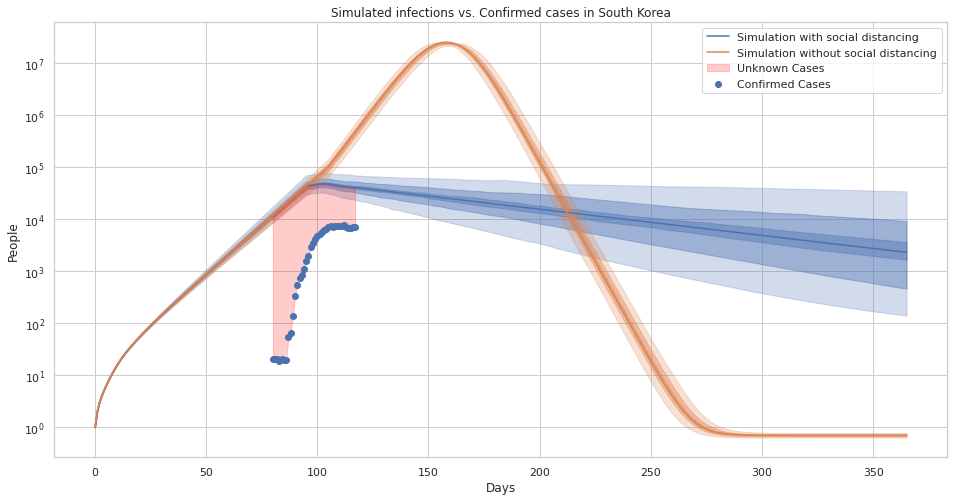
A comparison of confirmed cases in south korea and our simulated infections with uncertainty estimates.
-
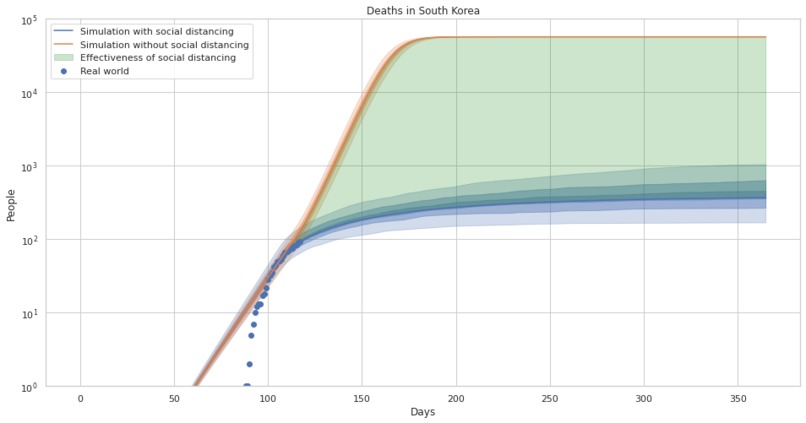
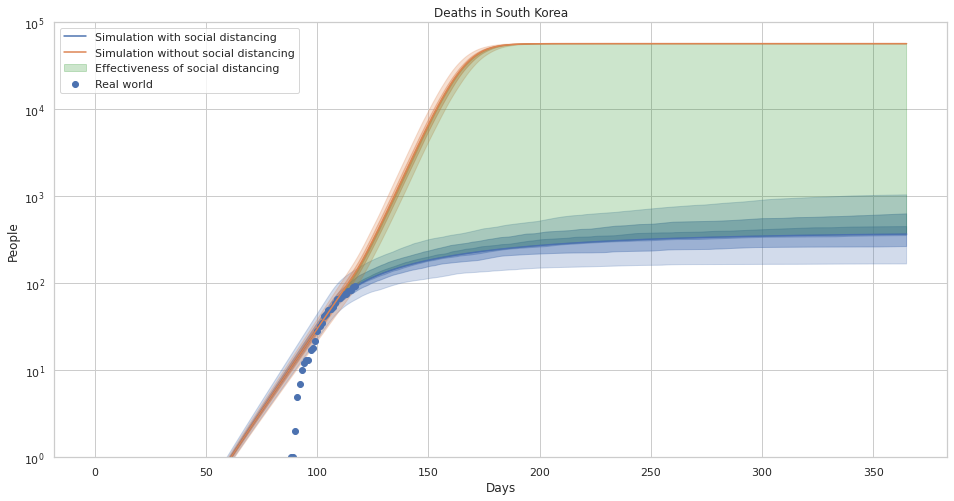
The effectiveness of social distancing in preventing death in south korea with uncertainty estimates.
-

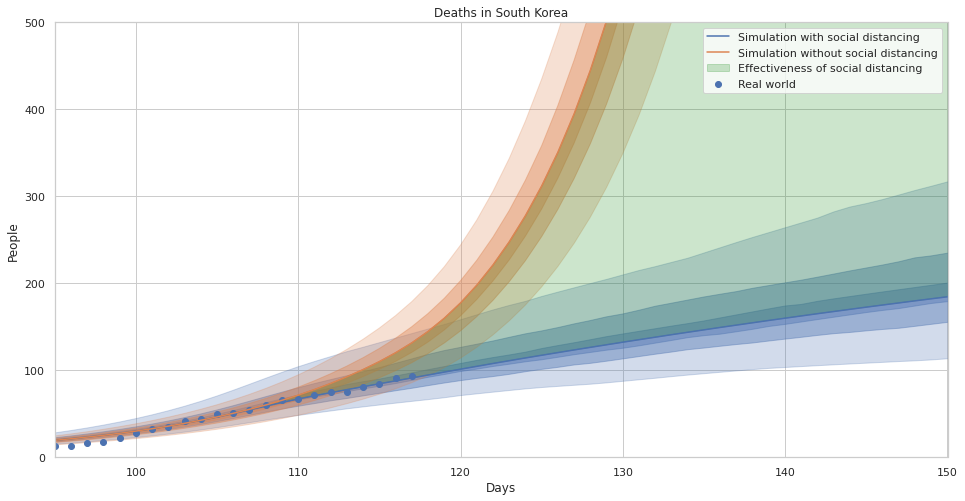
The effectiveness of social distancing in preventing death in south korea, zoomed to today with uncertainty estimates.
-

The effectiveness of social distancing in flattening the curve in south korea with uncertainty estimates.
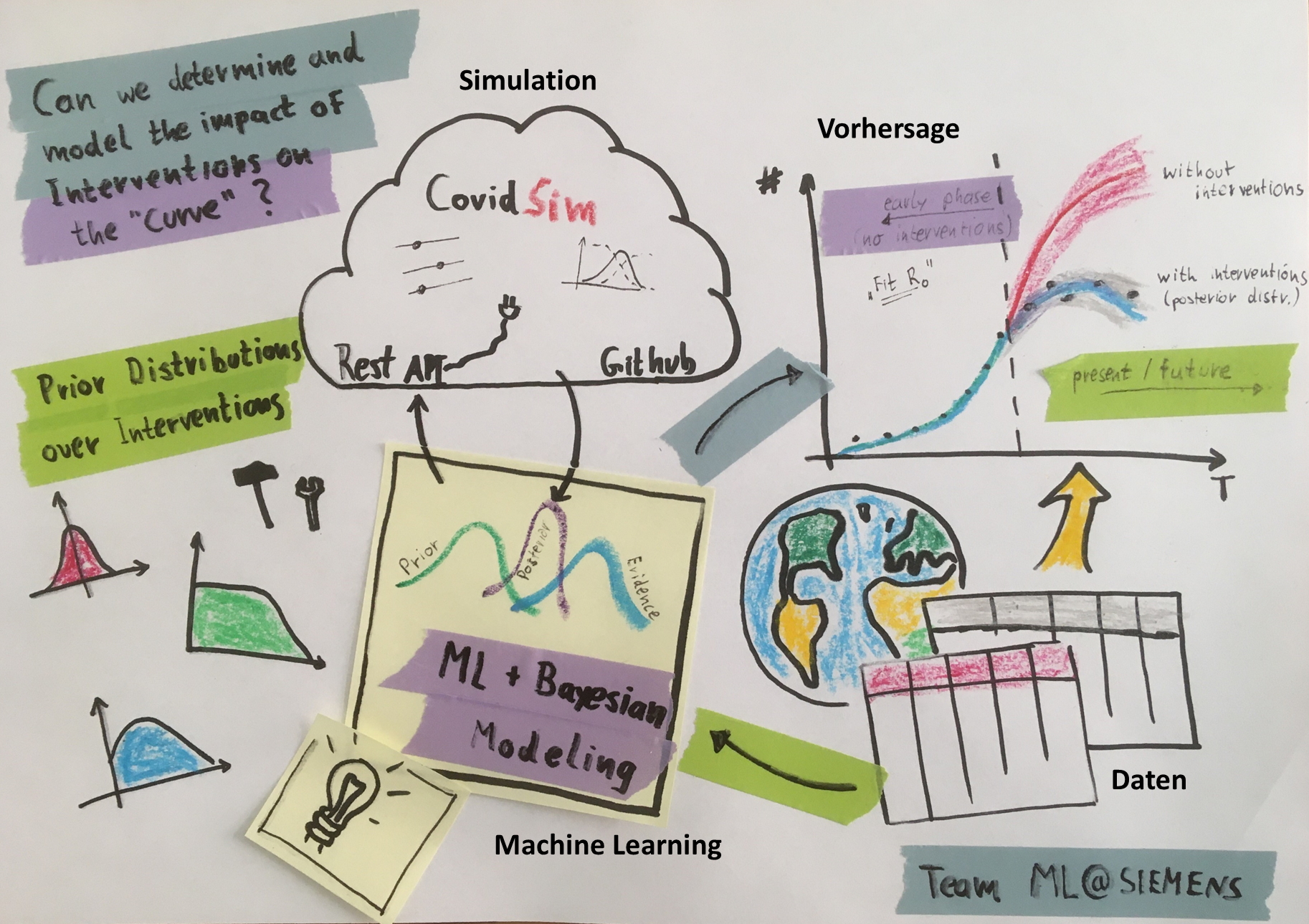




Inspiration
As we have learnt by example, applying interventions like quarantine or social distancing can save peoples' lives and account for a tremendous difference in the evolution of the infection "curve". However, today, there is little to no profound data available to validate existing mathematical models for the spread of COVID-19. For the same reason, there is also a huge lack in quantitative understanding which interventions are the most powerful in fighting the distribution of the disease.
What it does
Our goal is to combine real world data and epidemiological simulations to gain new insights about COVID-19 and the effectiveness of measures taken by different countries. Since we know there is a huge number of unknown cases due to incomplete testing, we cannot trust the reported case data. Instead use hospitalization, ICU and death toll data to parameterize an epidemiological simulation to explain the real world observations. The results of the simulation allow us to gain new insights such as
- an estimate of the number of unknown cases or
- an estimate of the effectiveness of measures such as social distancing, shutdown of schools, tracing positive test cases
for specific counties. We applied our approach to data from South Korea.
How we built it
In the hackathon we focused on three major areas: Machine Learning combining the COVID19 simulator, data integration and validation and data visualization.
Path to Machine Learning
We forked the COVID19 simulator to make actual model independent of browser-side Javascript. By adding a Node.js standalone wrapper for the simulator we exposed it's functionality via a REST API. We developed a Python client able to communicate with the simulator. We used this client with our implementation of particle swarm optimization to identify simulation parameters which explain real world observations. Our optimization approach combined general epidemiological insights COVID-19 (e.g. incubation period) with known country-specific parameters (e.g. measures taken) and unknown parameters (e.g. R0, measure effectiveness) we derive from data. The result of optimization is a full set of parameters which describes the COVID-19 progression in a country.
Data
In order to start a comprehensive picture around data relevant to better understand COVID-19 development, country specific aspects such as population structure, measures, and time series related to COVID-19. We combined sources from multiple websites. We used and aggregated available csv files where possible and curated other information from text (e.g. events from wikipedia).
Data Visualization
Data visualization was done in Python (Pyplot) and Tableau.
Challenges we ran into
- The global and German data situation is poor, inconsistent and sparse - indicating a lack of awareness for data in many relevant fields and organizations generating data
- Enabling existing epidemiological models for machine learning
- As data scientists, we had loads of fun getting into the domain of epidemiological and understanding of the related data
- Epidemiological sources are in part not public - big thanks to Martin Eichner
- Machine learners don't like Javascript :)
Accomplishments that we are proud of
- Be part of #wirvsvirus
- Awesome team spirit
- Commitment of all people in and around
- The potential we see for pushing data and machine learning to support COVID-19 crisis management
- Being able to contribute to many other hackathon teams by sharing data and data sources
- Great diverse team managing stay home families and awesome self organizing team dynamics
What we learned
- Siemens can contribute and help to setup an ontology for COVID-19 data and related meta data by continuation on the subject & sharing skill, tools and expertise in semantics and machine learning
- Potential for levering data, setting the stage for a data landscape and utilizing the data with data analytics and machine learning seems to be surprisingly promising as little prior work was uncovered during the hackathon
- Many parties seem to rely on very similar models
- Current models seem to leverage very little statistics in and around available data
What's next for 1_038_Wirksame Maßnahmen aus Daten-gestützter Simulation
- Beyond the hackathon we are working on extending our approach to other countries and more complex models
- We would support the government or any other party interested to setup a proper data landscape with skill and tooling
- We want to contribute answers to key questions and new insights despite poor data availability and high uncertainties
- We want to help improve the current simulations for COVID19
- We want to help with data understanding (data cleansing, integration, modelling in and around ontologies)
Built With
- covidsim
- data
- data-mining
- dataintegration
- datamining
- datavisualization
- gitlab
- machine-learning
- machinelarning
- pso
- python
- restapi
- tableau










Log in or sign up for Devpost to join the conversation.