-
-
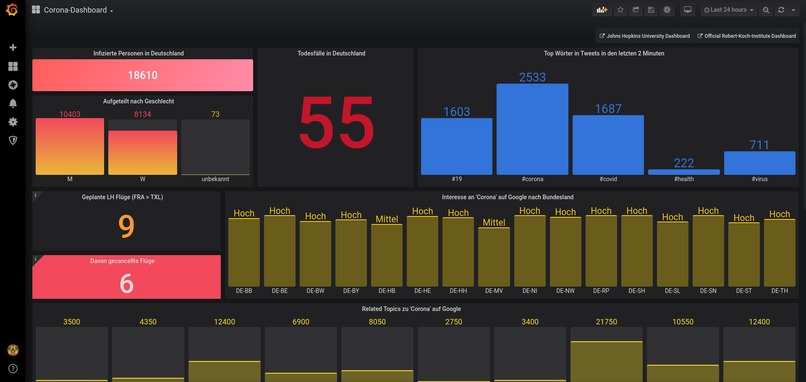
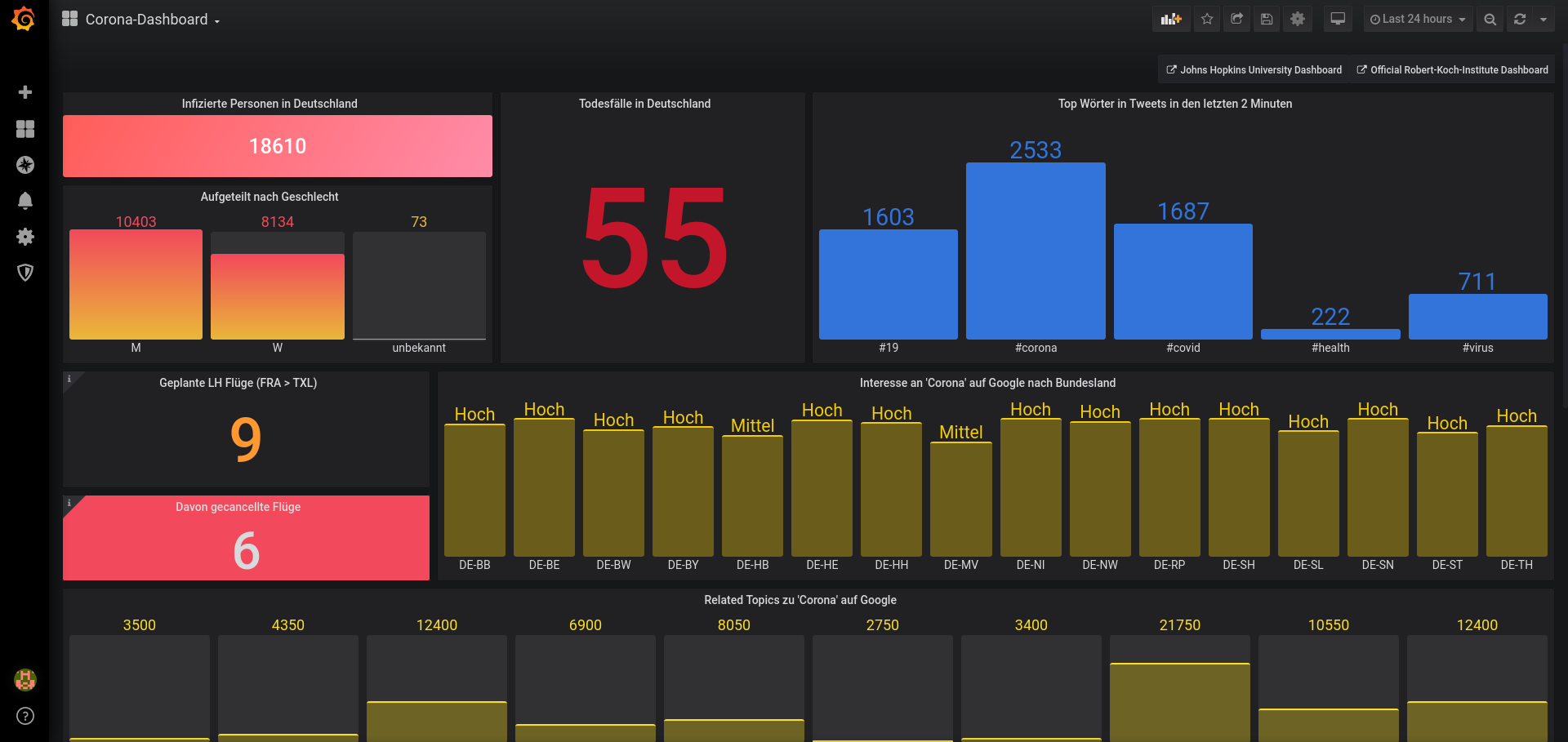
Grafana
-
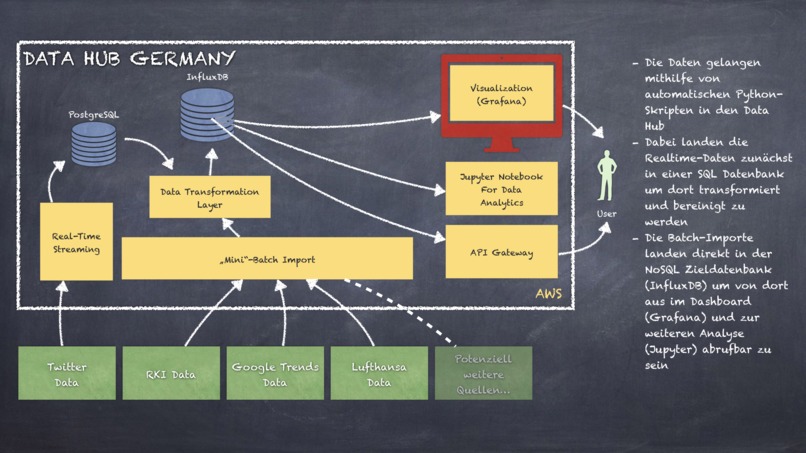
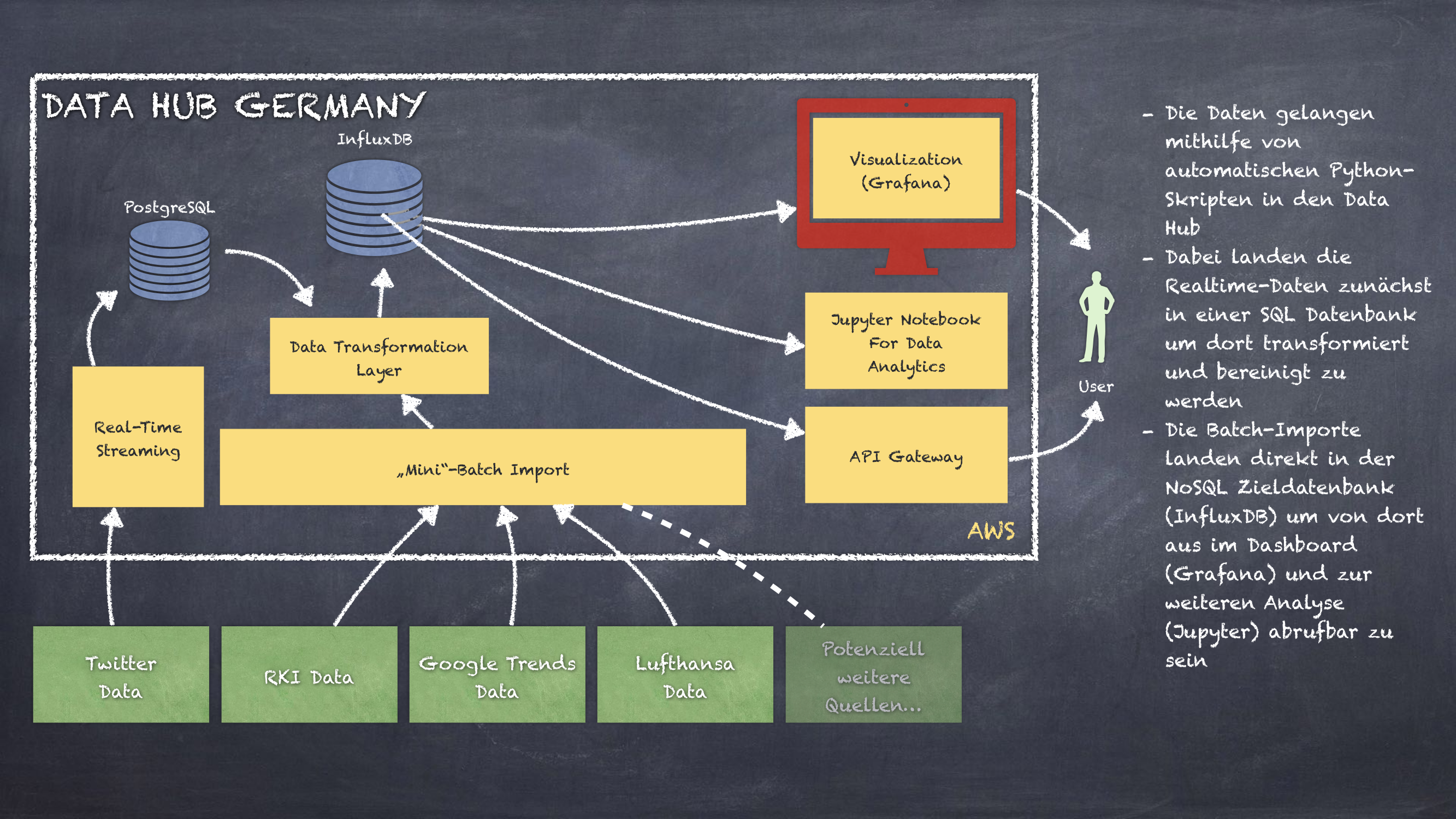
Data Hub
Inspiration
Major inspiration was the current situation with the corona virus - affecting every single one of us. To clear the situation up, we gathered publicly available data that is related to or could be interesting for coronavirus. We wanted to give data scientists the possibility to access that data and work with it seamlessly.
What it does
We started to build a data hub, which collects publicly available data and makes them transparent and accessible for everyone who is searching for a data source or an overview of the current situation.
How we built it
We worked completely virtual using modern collaboration tools like Slack Chat & Call as well as GitLab. We started with a big brainstorming group and ended up in a small team of two who were constantly in contact - eventhough we didn't know each other before. We built the infrastructure on AWS instances. A PostgreSQL database is used to store the twitter stream and we built a data transformation layer to pass those data and other data sources into an InfluxDB database (NoSQL). To output our data, we connected Grafana to our InfluxDB and configured a dashboard. For users who want to work with the data we installed a jupyter instance and put up an API Gateway to get all the measurement data.
Challenges we ran into
We had a lot of technical issues in the beginning, because we started the whole project from scratch and could not build on existing projects. But we finally solved almost all challenges (of course there is always something which could be improved with more time).
Accomplishments that we're proud of
We were dealing with technologies, that were completely new to us, and were able to solve problems in team and in the end built something completely new.
What we learned
- Focus is very important
- team work is key
- patience
What's next for 1_038_a_daten_data_hub
In future we would like to accompany the further development of the concept by adding more and more data sources as well as enhance the capabilities our API.
Built With
- amazon-web-services
- googletrends
- grafana
- influxdb
- jupyter
- nosql
- pandas
- postgresql
- pyspark
- python
- tweepy
- ubuntu








Log in or sign up for Devpost to join the conversation.