-
Our frontpage
-

Sleep time analysis
-
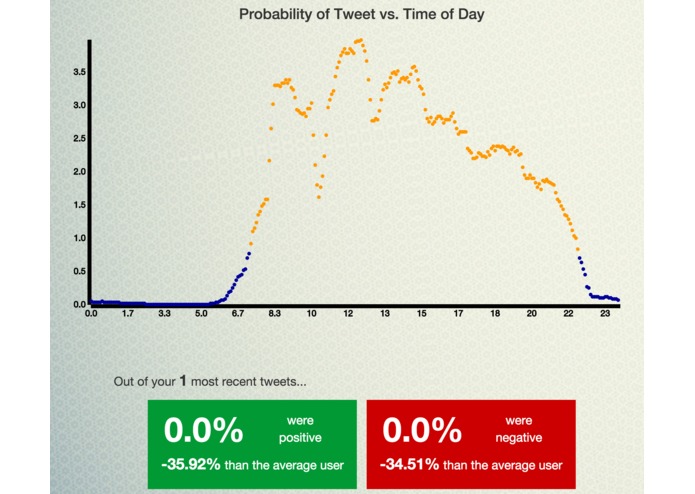
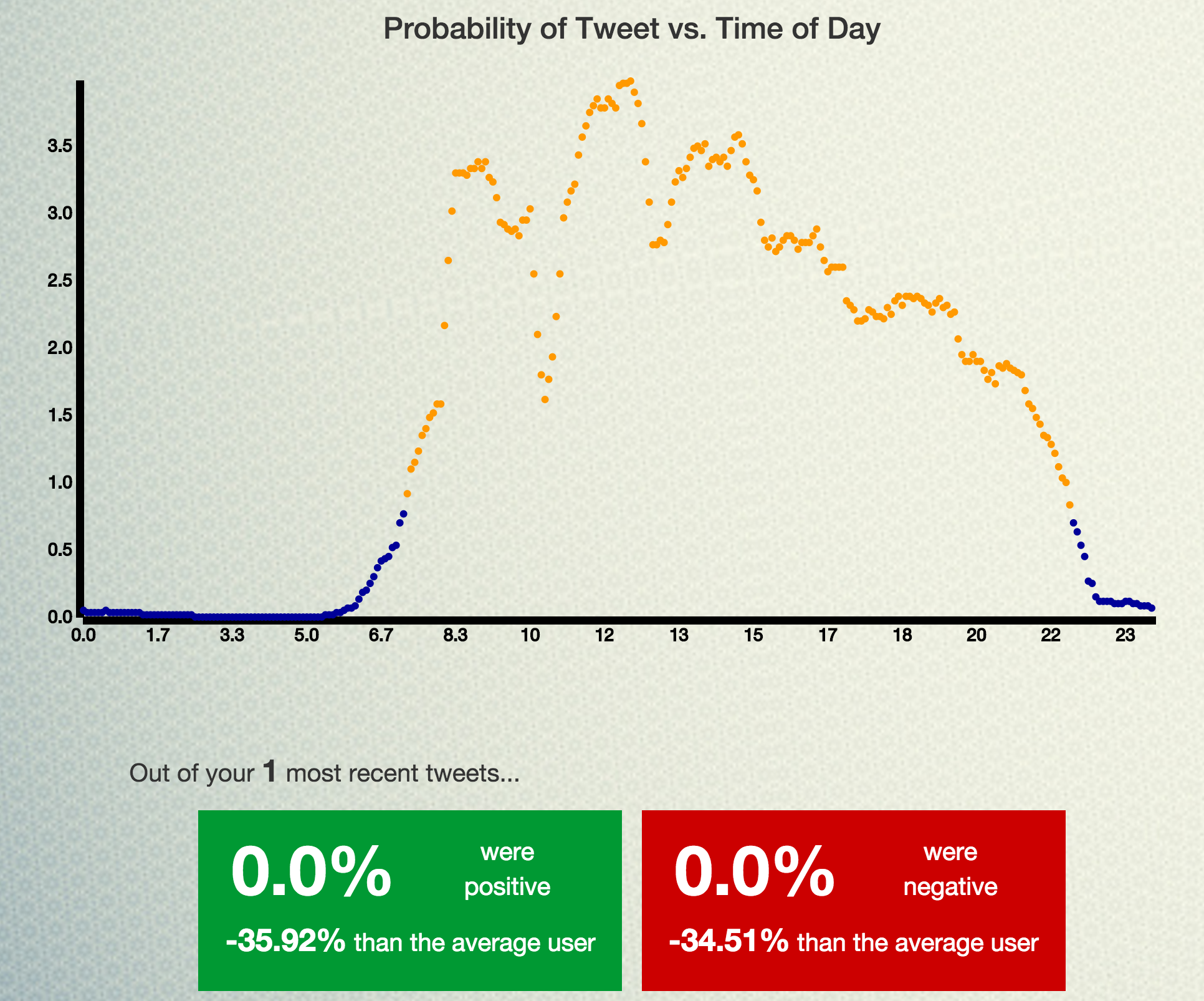
Awake/sleep graph, and sentiment analysis

Inspiration
We put out a lot of information about ourselves out there every single day. Included in that, is a bunch of metadata about when we are online, and when we aren't. We can leverage this data and, with the assumption that, on average, people are offline when they are asleep, we can infer when a given user goes to sleep, and wakes up. This may sound creepy, but we use this information to provide a user with a sleep report: how much they sleep and how that affects their mood.
What it does
Our web app takes in a twitter username and calculates what's called a "Poisson Probability Distribution", that is, the probability that the person is tweeting at any given point throughout the day. It then uses this distribution to figure out the times that the person is most likely to be awake or asleep. This is reported to the user in the form of an average wakeup and bedtime, as well as number of hours slept.
We also compare each user's information with a continuously-updated firebase, so we can report numbers like "You sleep 8h/day, that's 17% more than the average user of 140 M.D."
Lastly, we query Datumbox's Twitter Sentiment Analysis API with the 30-ish most recent tweets from the user, to get data in the form of number of positive, negative and neutral tweets. This data is also reported as percentages of positive/negative tweets and comparisons to the average user.
How we built it
We had a lot of fun thinking about how the math would work out. We built our initial experiments in python, so converting everything to a flask web app was a natural fit. We also used firebase to maintain the state of the average user.
Challenges we ran into
One of the most interesting solutions we came up (and perhaps one of the most intuitive in retrospect) was how to convert a probability distribution of tweeting into a wakeup/bedtime, with some level of confidence. We realized that we could try fitting a binary function (one that's either off or on, sleeping or awake) to the distribution we had. That was a simple matter of minimizing the variance between the two functions. Furthermore, we could normalize that variance with the theoretical max variance for that distribution, and that gave us a way to measure how certain we were of our correctness.
The other interesting math part about the project was building the probability distribution itself. To create it, we had to generate multiple poisson distributions, one for every five minutes of the day. Each of those was built by pooling the number of tweets in its "neighborhood" (+ or - 60 min), and dividing that by the number of minutes. This simple process gave us much more insight into out data than simply plotting numberoftweets vs. minuteofday.
Accomplishments that we're proud of
We're very proud of how accurate our predictions seem to be. We know of a few shortcomings of our methodology ("what if the person just doesn't tweet when they're in class?"), but our predictions were within reasonable estimation for our own twitter accounts.
What we learned
We learned a lot about math and probability. We also learned a lot about how to make inferences from data. This was the first hackathon for one member of the group. There was much learning!!! Everything from Git/GitHub, Flask, HTML, Python, Ubuntu/Bash led to a really exciting learning experience. It could be a bit daunting at times, but we climbed the mountain!
What's next for 140 M.D.
One thing we want to improve in the current stack is on the limitations of the Datumbox API. It only allows us to make 1000 API calls/day, which isn't enough for analyzing the sentiment of multiple tweets per user, for multiple users. The amount of calls is also another bottleneck for the performance of our website. Lastly, we the Datumbox API only provides us with positive/negative/neutral sentiment classification. We believe more insight could be gathered about the relationship between sleep and emotion, if we had more intricate emotion classification (anger/sadness/happiness/etc).




Log in or sign up for Devpost to join the conversation.