
💡 Inspiration
In the SwanChain community, many simple and repetitive questions are constantly asked by users. This creates a significant burden on community maintainers, wasting their time and energy. We wanted to build a smart assistant that could automate answering common questions, allowing community members to focus on more meaningful discussions and development.
By leveraging GraphRAG and Meta Llama3, we aimed to create an AI-powered Telegram bot that efficiently retrieves and generates accurate answers based on official documentation. This would reduce redundancy, improve response speed, and enhance user experience in the SwanChain community. 🚀
🚀 What It Does
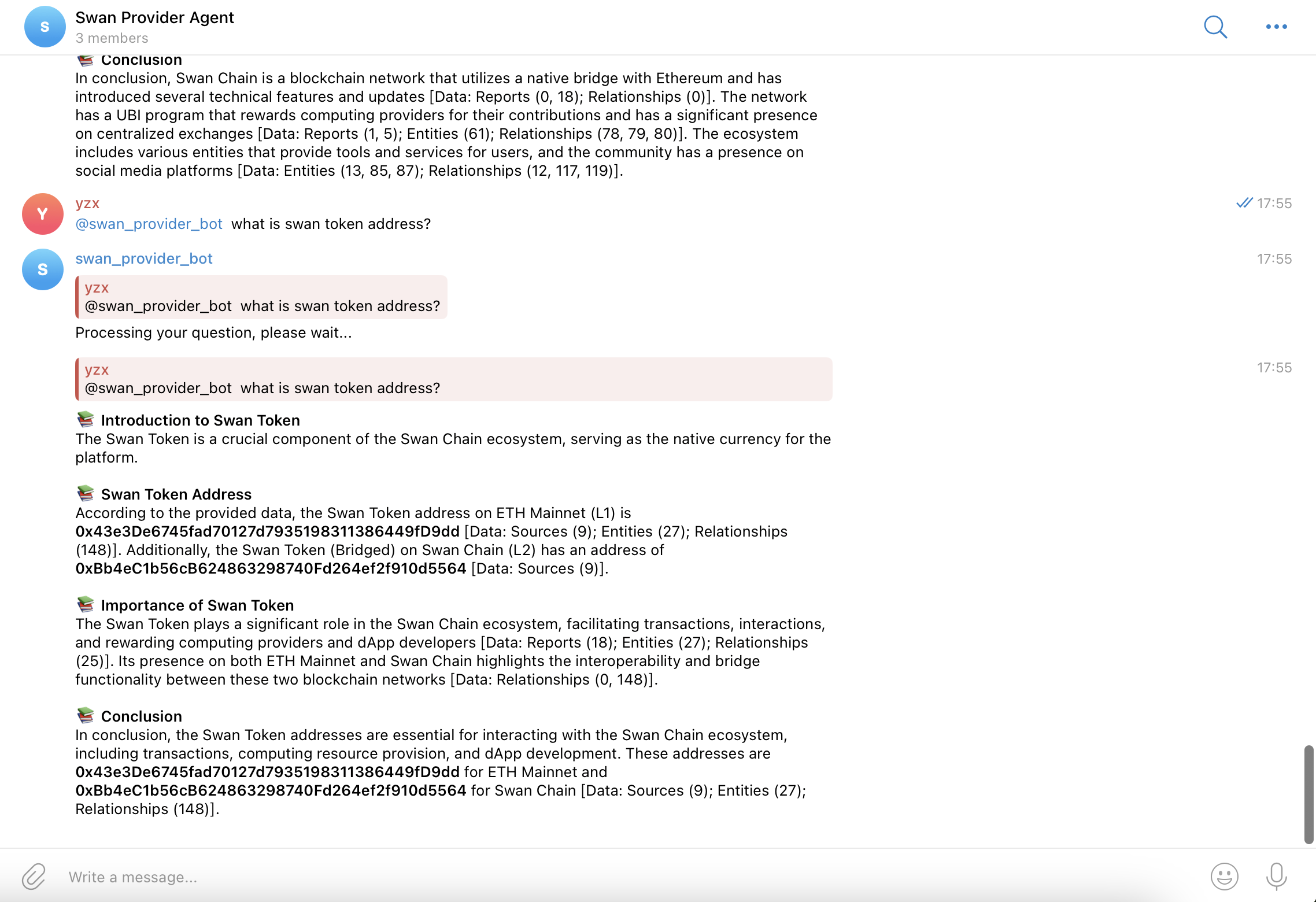
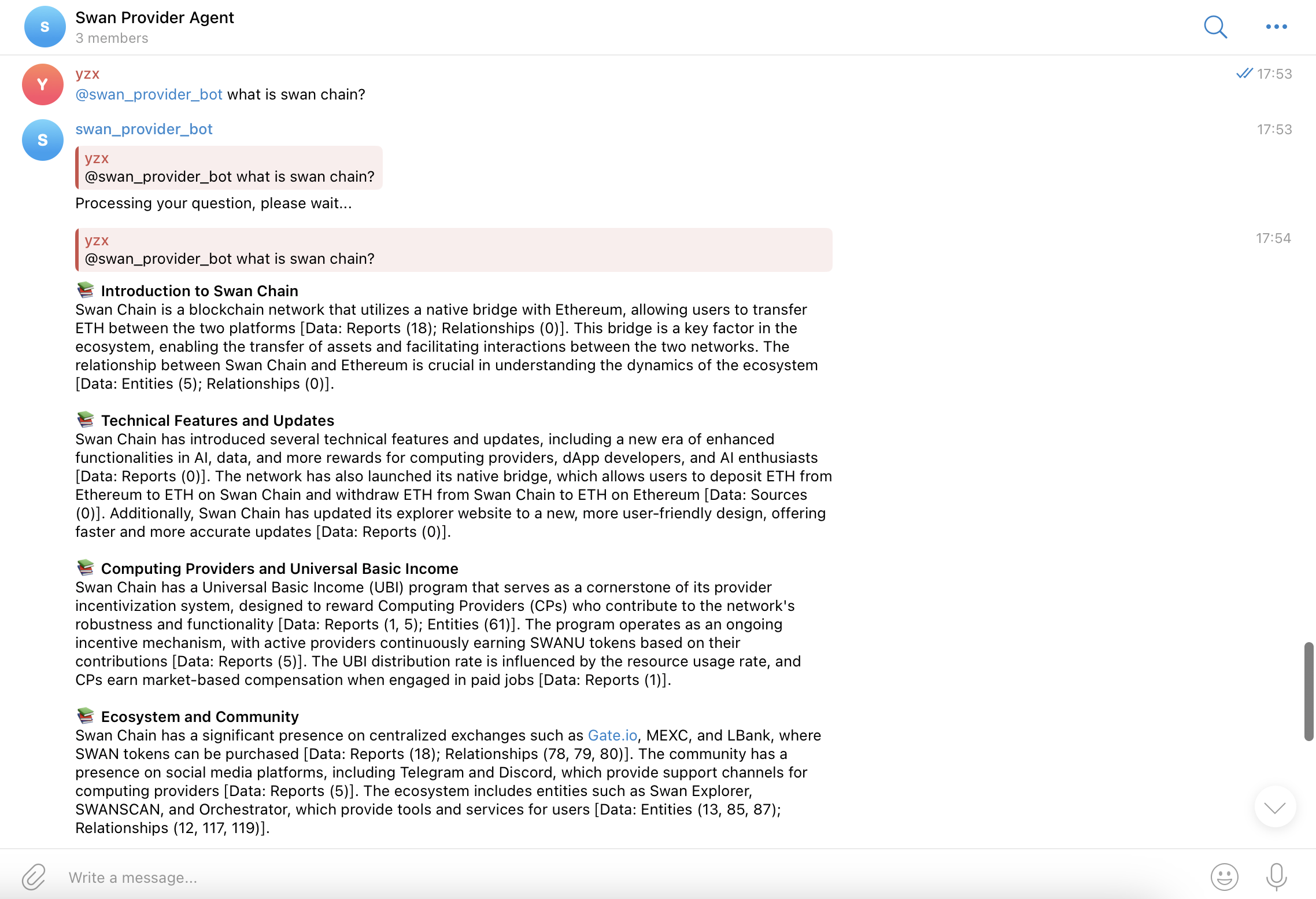
Swan Provider Agent is a Telegram bot that allows users to ask questions about SwanChain and receive AI-generated answers based on the official documentation.
Key Features
Cloning & Updating Documentation
- The bot keeps a local copy of the SwanChain GitBook by cloning or updating the repository.
- The bot keeps a local copy of the SwanChain GitBook by cloning or updating the repository.
GraphRAG Indexing & Dynamic Updates
- Converts Markdown files to text and builds a structured knowledge graph using GraphRAG.
- Supports dynamic index updates: When new documentation is added, the bot automatically updates the index incrementally, avoiding full reindexing.
- Converts Markdown files to text and builds a structured knowledge graph using GraphRAG.
Query Processing & Context Retrieval
- When a user asks a question, the bot queries the pre-built GraphRAG index to fetch relevant documentation context.
LLM-Powered Answer Generation
- The retrieved context is combined with the user’s question and sent to Meta Llama3, which generates an intelligent response.
- The retrieved context is combined with the user’s question and sent to Meta Llama3, which generates an intelligent response.
Seamless Telegram Integration
- Users can chat with the bot directly in Telegram, making it an easy-to-use AI-powered knowledge assistant.
- Users can chat with the bot directly in Telegram, making it an easy-to-use AI-powered knowledge assistant.
With dynamic index updates, the bot remains up-to-date with the latest SwanChain documentation, ensuring that users always receive accurate and current information. 🚀
🛠 How We Built It
GraphRAG for Indexing
- Used GraphRAG to process Markdown files and create an efficient, reusable knowledge index.
- Implemented dynamic index updates, allowing incremental changes without full reindexing.
- Used GraphRAG to process Markdown files and create an efficient, reusable knowledge index.
Markdown Preprocessing & Cleanup
- Converted Markdown files to plain text for better indexing.
- Removed unnecessary HTML tags, ensuring clean and structured data.
- Filtered out irrelevant content, keeping only meaningful documentation.
- Converted Markdown files to plain text for better indexing.
LLM Integration (Meta Llama3)
- Combined user queries with retrieved context to enhance LLM-based answer generation.
- Combined user queries with retrieved context to enhance LLM-based answer generation.
Asynchronous Processing
- Implemented asyncio for parallel task execution, ensuring fast response times.
- Implemented asyncio for parallel task execution, ensuring fast response times.
Telegram Bot Development
- Used
python-telegram-botto create a conversational interface.
- Used
API & Infrastructure
- Built an API using FastAPI to handle document uploads, queries, and indexing.
- Built an API using FastAPI to handle document uploads, queries, and indexing.
By cleaning and optimizing the documentation data, we improved retrieval accuracy and made the bot more efficient and reliable. 🚀
⚠️ Challenges We Ran Into
LLM Response Quality Degradation
- As the number of indexed files increased, we noticed a rapid decline in response quality.
- The model sometimes retrieved less relevant context or struggled with longer, more complex queries.
- We had to optimize retrieval strategies and improve context selection to maintain accuracy.
- As the number of indexed files increased, we noticed a rapid decline in response quality.
Efficient Index Updating
- Implementing dynamic index updates without rebuilding the entire knowledge base was challenging.
- We optimized incremental indexing to ensure new documents were processed without affecting performance.
- Implementing dynamic index updates without rebuilding the entire knowledge base was challenging.
Markdown Preprocessing
- Cleaning Markdown files and removing unnecessary HTML tags while preserving essential formatting was tricky.
- Some files had inconsistent structures, requiring additional parsing and filtering logic.
- Cleaning Markdown files and removing unnecessary HTML tags while preserving essential formatting was tricky.
Asynchronous Processing & API Rate Limits
- Handling multiple concurrent queries while respecting API rate limits was a challenge.
- We implemented retry mechanisms and rate control to balance performance and stability.
- Handling multiple concurrent queries while respecting API rate limits was a challenge.
Through continuous optimization and testing, we improved response quality, indexing efficiency, and overall bot performance. 🚀
🏆 Accomplishments That We're Proud Of
- 🚀 Dynamic Index Updates – Successfully implemented incremental indexing, keeping responses up to date without full reindexing.
- 📖 Improved Documentation Processing – Cleaned Markdown files, removing unnecessary HTML for better indexing and retrieval.
- ⚡ Optimized Query Processing – Enhanced GraphRAG strategies to maintain high response quality as data grows.
- 🤖 Fully Integrated Telegram Bot – Provides real-time AI-powered answers, improving community support.
- 🔄 Scalable & Asynchronous Processing – Handles multiple requests efficiently, ensuring stability and speed.
This project enhances knowledge access and streamlines community interactions with AI. 🚀
📚 What We Learned
- 🔍 Data Processing is Key – Cleaning and structuring data effectively is crucial for accurate retrieval and high-quality responses.
- 📈 Indexing Efficiency – Incremental indexing can significantly improve performance while keeping the system up to date.
- ⚖️ Balancing Quality & Scale – As the system scales, maintaining response quality becomes challenging, but optimizing retrieval and context selection helps manage it.
- 🤖 Asynchronous Design – Using async processing enables the bot to handle multiple requests efficiently without overwhelming the system.
- 💬 Real-Time Feedback – Community interaction and feedback are essential for improving the system and ensuring it meets users' needs.
These insights have been invaluable in making the bot efficient, responsive, and scalable. 🚀
🔮 What's Next for Swan Provider Agent
- 📂 Expand Document Processing – Support more document types, such as DOC, PPT, PDF, for broader content coverage.
- ⚙️ Explore Advanced Indexing Tools – Experiment with more efficient and flexible indexing tools, like LightRAG and KAG, to improve performance and scalability.
- ⚡ Improve LLM Response Quality – Enhance the query processing pipeline to ensure more accurate and relevant answers.
- 🌐 Add Multi-Language Support – Extend the bot to handle multiple languages, making it accessible to a global audience.
- 💬 Enhance User Interaction – Implement multi-step queries, contextual follow-ups, and other features for a more dynamic user experience.
- 🚀 Scale and Optimize – Continue optimizing the bot to handle a larger user base and more concurrent queries efficiently.
The aim is to make Swan Provider Agent more flexible, intelligent, and user-friendly, ensuring it remains a valuable resource for the SwanChain community. 🚀
Built With
- fastapi
- graphrag
- llama
- nebulablock
- python
- python-telegram-bot
- telegramify-markdown
- vector-databases



Log in or sign up for Devpost to join the conversation.