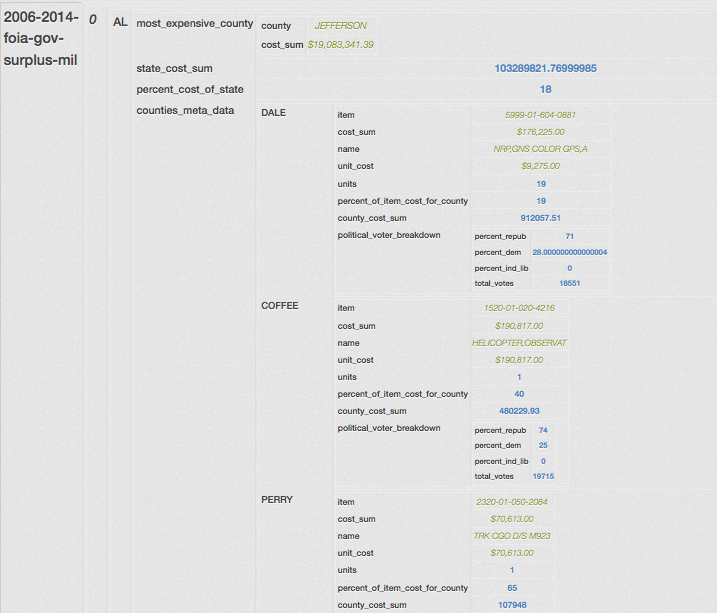
I just wanted to play around with NYT data dump from the FOIA request and try to see who benifits most from such a program, by trying to correlate it with other data sets and mining information from the internet.
Target users are probably people who can deal with JSON files.

Log in or sign up for Devpost to join the conversation.