-
-
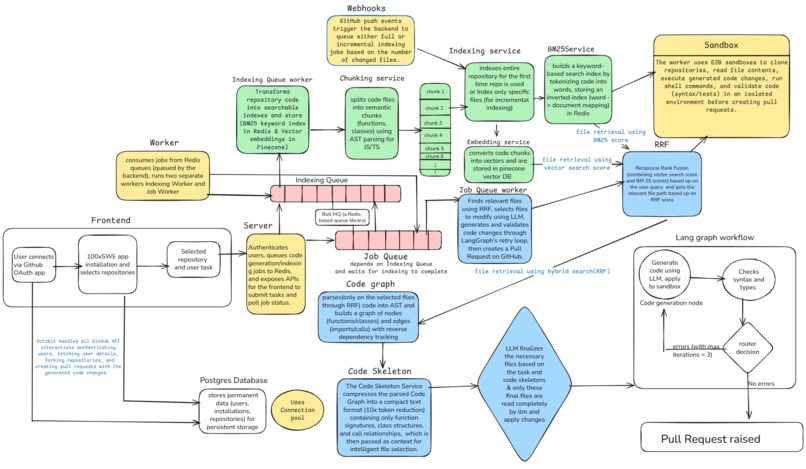
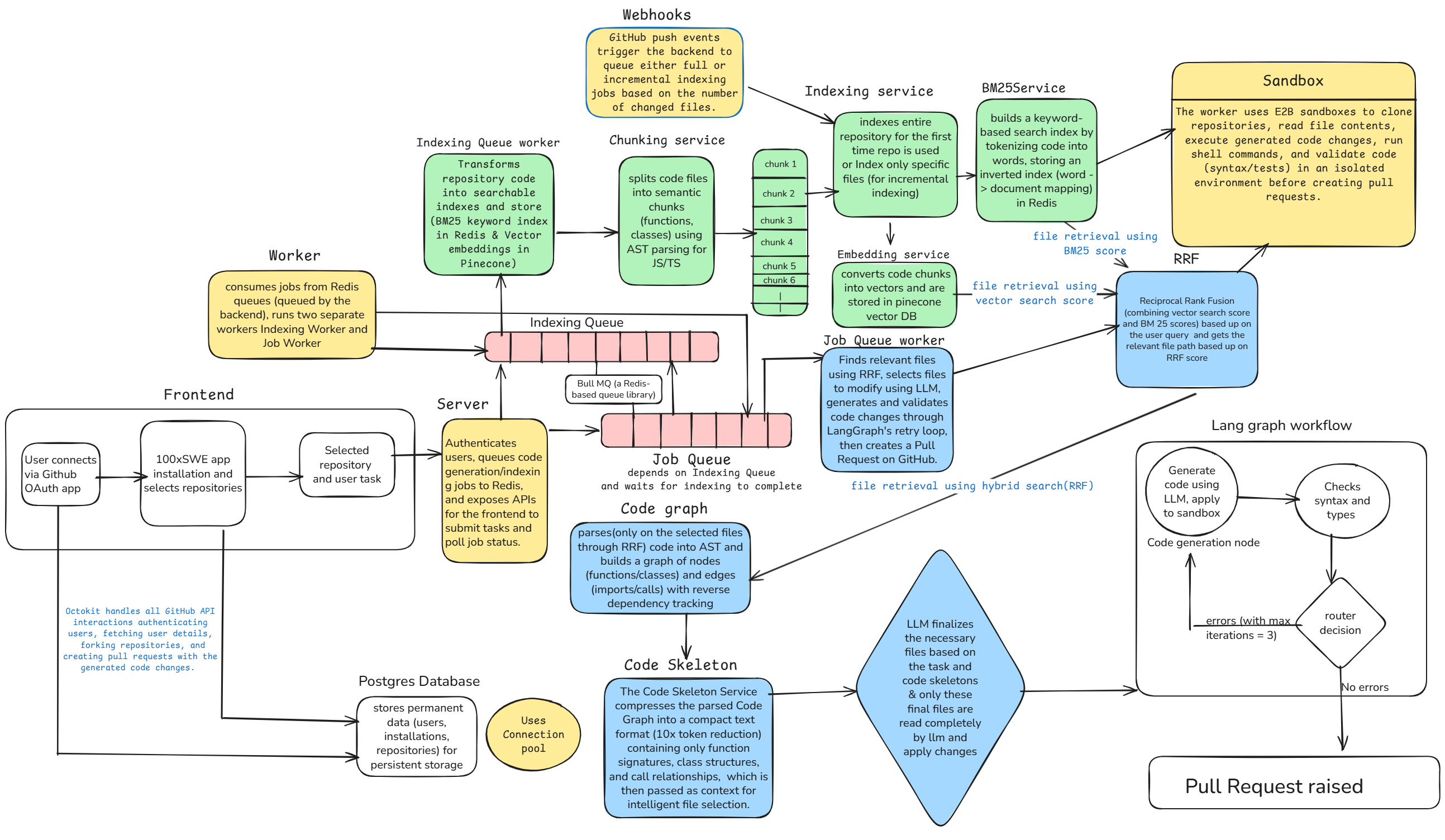
Architecture
Inspiration
This project started with a simple but powerful observation while reading a Milvus blog. The post showed that replacing grep based retrieval with vector search reduced token usage by more than forty percent. :contentReference[oaicite:0]{index=0}
That result pointed to a deeper issue. Most AI coding agents rely on keyword matching, which returns unranked results and forces the model to read everything to figure out relevance. This wastes tokens and lacks any understanding of code structure.
This made me question whether we could design a system that understands code semantically, prioritizes relevance, and reasons about dependencies instead of blindly scanning files.
What it does
100xSWE is an AI coding agent designed to automate pull requests efficiently by focusing on high quality context retrieval.
It retrieves relevant parts of a codebase using a hybrid search approach that combines semantic search and keyword matching. It then builds a structured understanding of the code using AST parsing and dependency graphs.
Instead of sending entire files to the model, it provides compressed representations of the codebase and lets the model selectively expand only what it needs. The system generates code changes, validates them using type and syntax checks, and automatically creates pull requests once the output passes validation.
How we built it
The system is built as a pipeline where each stage solves a specific problem.
We implemented a hybrid retrieval system combining vector embeddings for semantic understanding and BM25 for precise keyword matching. These results are merged using Reciprocal Rank Fusion to produce a unified ranking
$$ RRF(d) = \sum_{i=1}^{n} \frac{1}{k + rank_i(d)} $$
We used AST parsing to chunk code into meaningful units such as functions and classes, preserving structure during embedding.
A dependency graph was constructed to capture relationships between files through imports and function calls.
For context construction, we generated structured summaries containing function signatures, called functions, and imports. The model uses these summaries to decide which files to read in full.
The agent pipeline was built using LangGraph, enabling retrieval, reasoning, generation, validation, and retry loops. If validation fails, error messages are fed back into the system for iterative improvement.
To make the system production ready, we added incremental indexing using git diffs, parallel index updates, job queue handling, Redis caching with sliding TTL, and sandboxed execution.
Challenges we ran into
One of the biggest challenges was chunking code correctly. Naive approaches like fixed size splitting broke code semantics and resulted in poor embeddings. Moving to AST based chunking required more effort but was necessary.
Another challenge was combining semantic search and keyword search. Their scoring systems are fundamentally different, which made direct comparison impossible. This required adopting rank based fusion techniques.
Managing context size was also difficult. Sending too much information degraded model performance, while sending too little reduced accuracy.
Finally, building a system that works in real world conditions required solving issues like stale embeddings, concurrent requests, and efficient index reuse.
Accomplishments that we're proud of
We built a system that significantly improves how coding agents retrieve and use context.
The hybrid retrieval approach ensures both semantic understanding and precise matching. AST based chunking preserves code structure, leading to better embeddings. The dependency graph enables safer and more informed code changes.
The context compression strategy reduces token usage while improving accuracy. The validation loop makes the system more reliable by iteratively refining outputs based on real errors.
Overall, the system moves beyond naive retrieval and demonstrates a more structured and efficient way to build AI coding agents.
What we learned
The most important lesson was that retrieval is the foundation of any AI coding system. If the model receives poor context, even the best models fail.
We also learned that combining different techniques often works better than relying on a single approach. Semantic search and keyword search complement each other when used together.
Understanding code structure is critical. Treating code as plain text leads to poor results, while leveraging AST and dependency graphs unlocks much better performance.
Another key takeaway was that building production systems requires thinking beyond core algorithms and focusing on scalability, caching, and reliability.
What's next for 100xSWE
We plan to extend the system in several directions.
First, adding a fallback keyword search mechanism to handle edge cases where hybrid retrieval does not surface the right results.
Second, expanding support beyond JavaScript by integrating multi language AST parsing using tools like tree sitter.
Third, introducing a planning step where the agent proposes a solution and incorporates human feedback before generating code.
Finally, improving validation by running repository tests and feeding failures back into the system, making the agent more reliable for real world usage.
Built With
- babel-parser
- based
- bm25
- bullmq
- bun
- cloud
- e2b-code-interpreter
- express.js
- github-webhooks
- google-gemini-api
- langchain
- langgraph
- next.js
- octokit-(github-api)
- openai-api
- pinecone
- react
- redis
- tailwind-css
- typescript
- worker

Log in or sign up for Devpost to join the conversation.