-
-
AI / RAG Interface
-
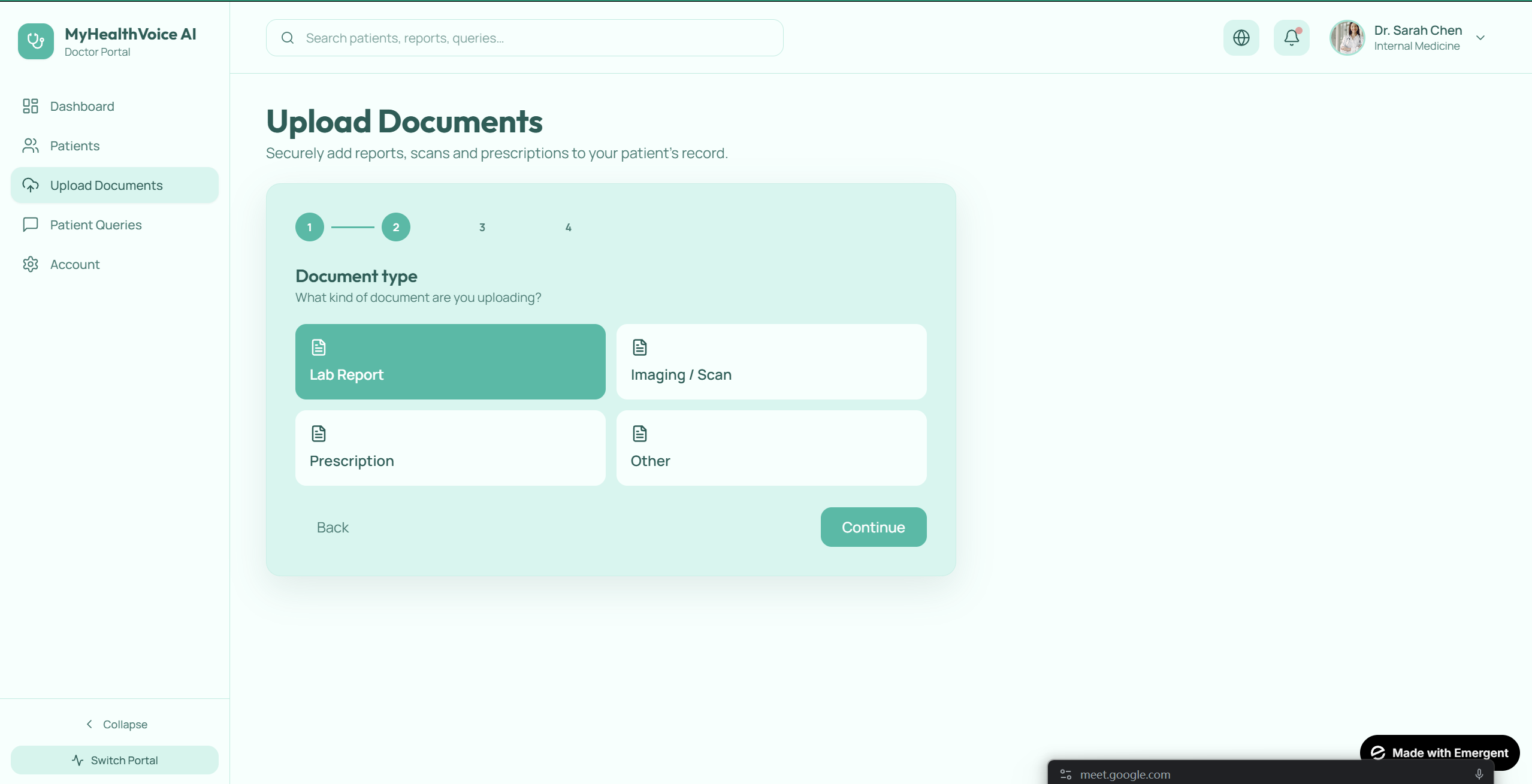
Upload Documents
-
Change Files
-
Follow Up
-
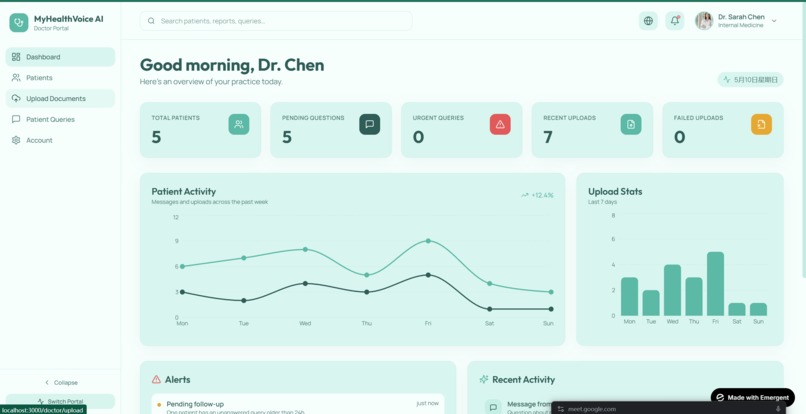
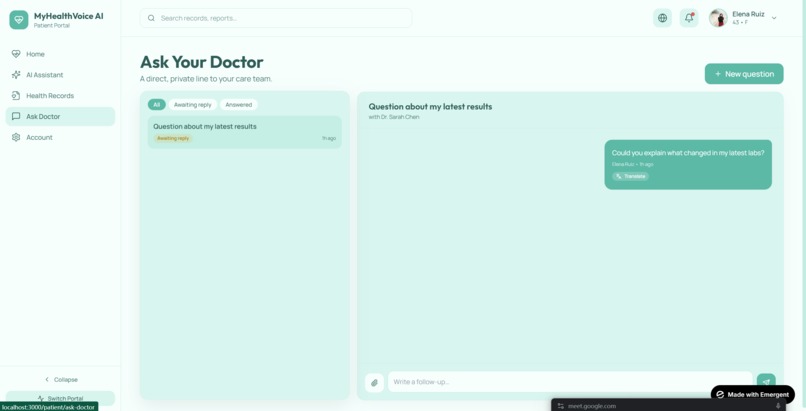
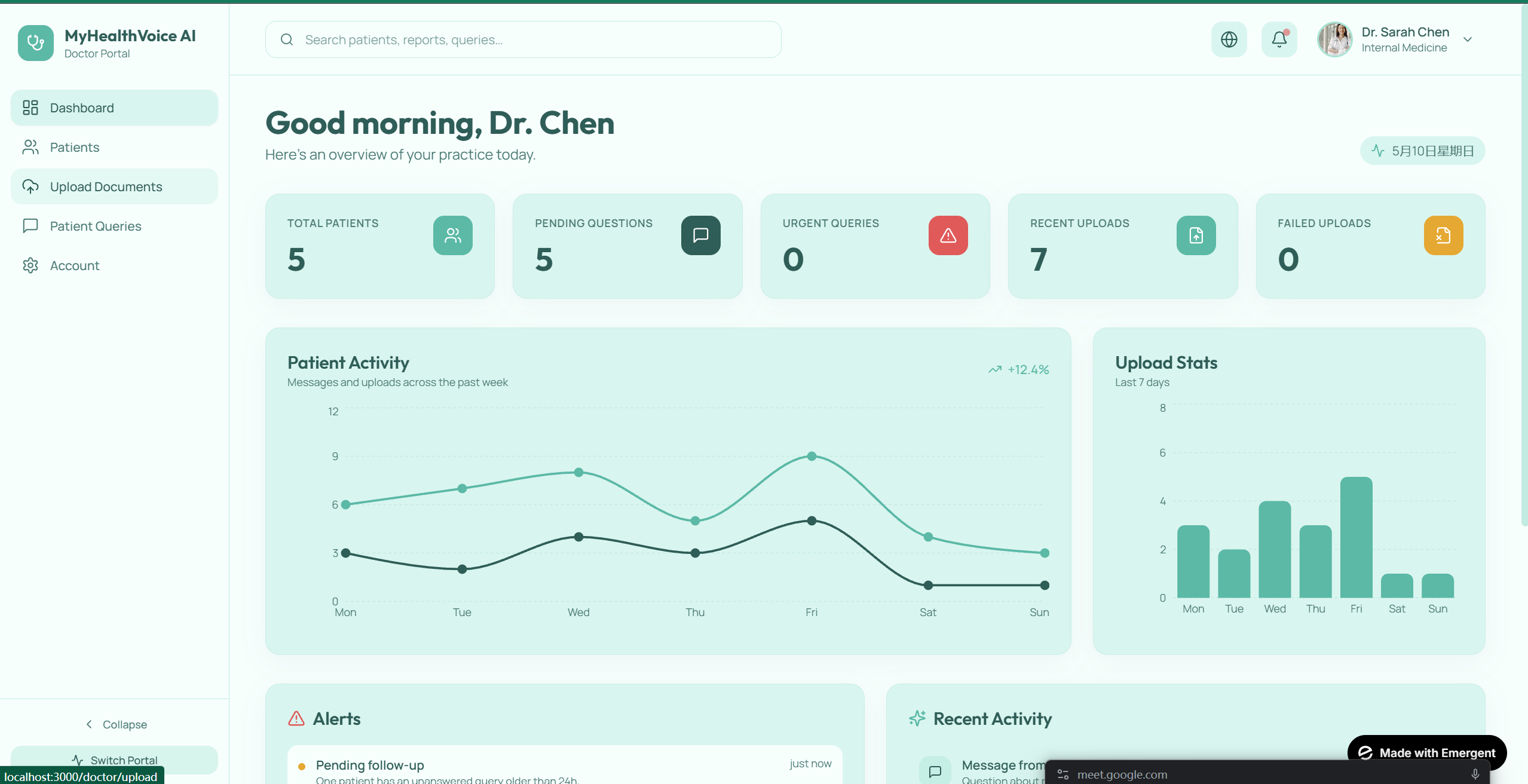
Doctor's View
-
Security Implementations
-
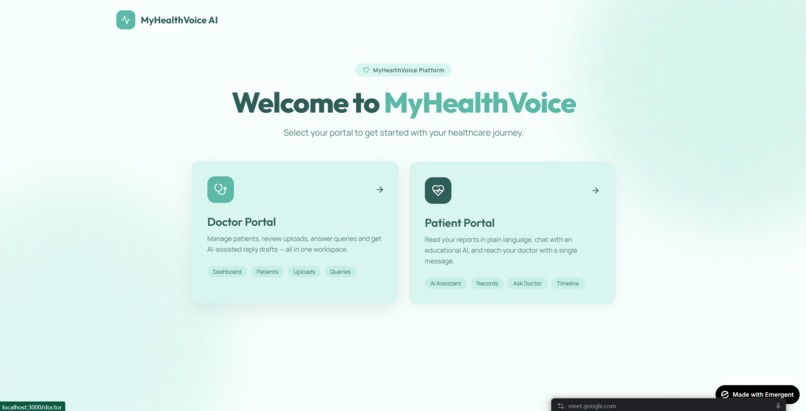
Main Page
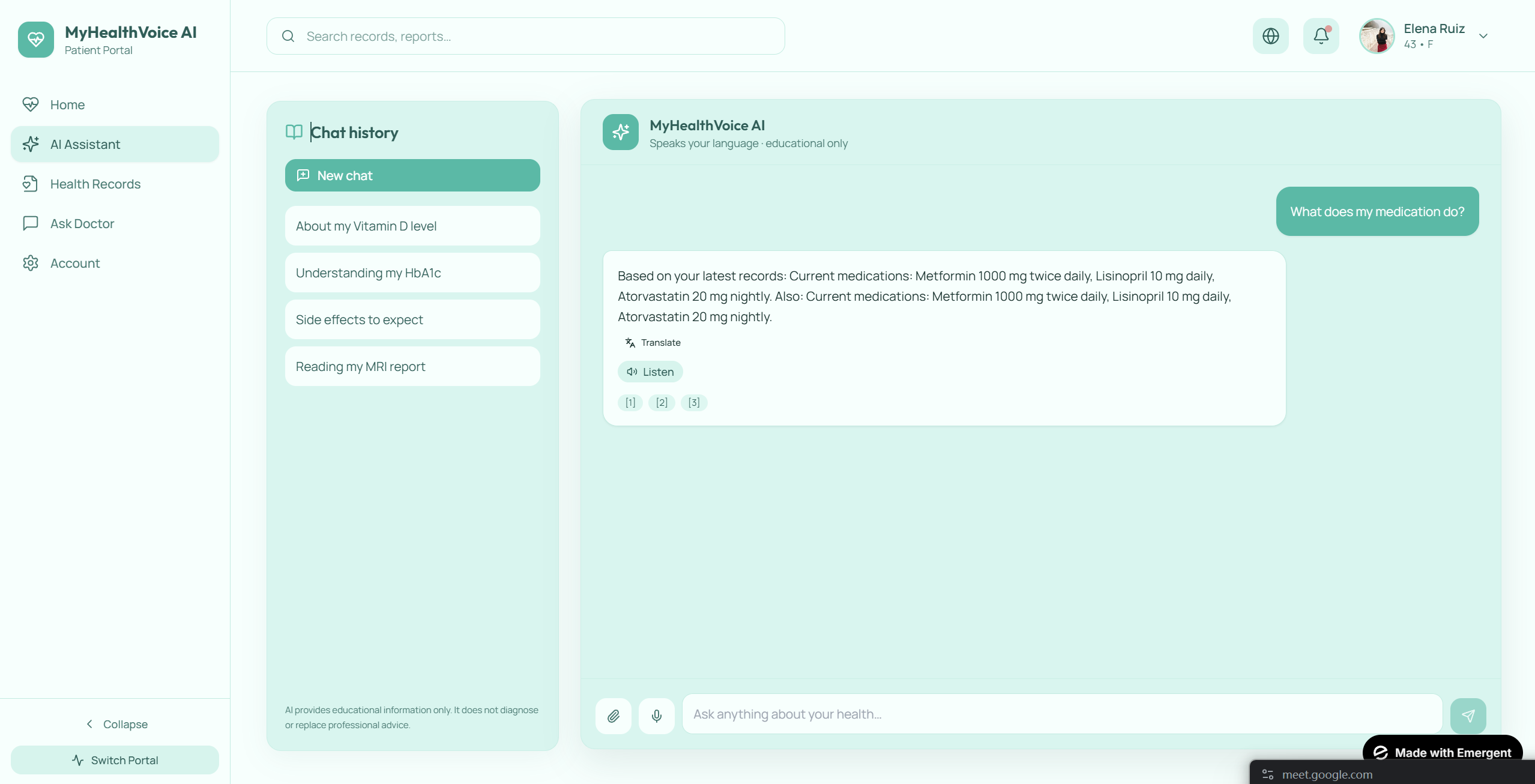
Inspiration
A doctor friend told us something that stuck with us: when she explains a serious diagnosis, she ends up giving the clearer version to the patient's family member, not the patient themselves. The patient is overwhelmed, scared, or doesn't speak English well — so the real explanation goes to the daughter or son in the room, and the patient leaves with vague reassurances.
We dug into the literature. Studies show patients forget or misunderstand 40–80% of what their doctor says during a visit. The numbers get worse for non-English speakers, older adults, people with low literacy, and people receiving difficult diagnoses. Meanwhile, AI medical scribes (Abridge, Vero, Freed, Heidi) are booming — but every one of them is built for the doctor. None of them serve the patient after the visit ends.
That gap is the problem. The patient is the one who has to live with the diagnosis. They deserve the same clarity the doctor would give a trusted family member.
That's what we built.
What it does
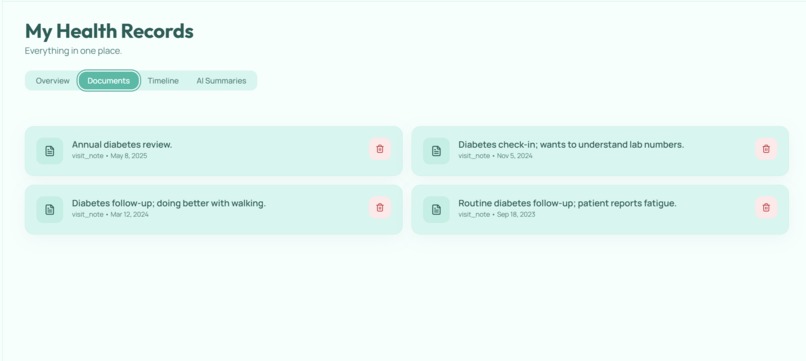
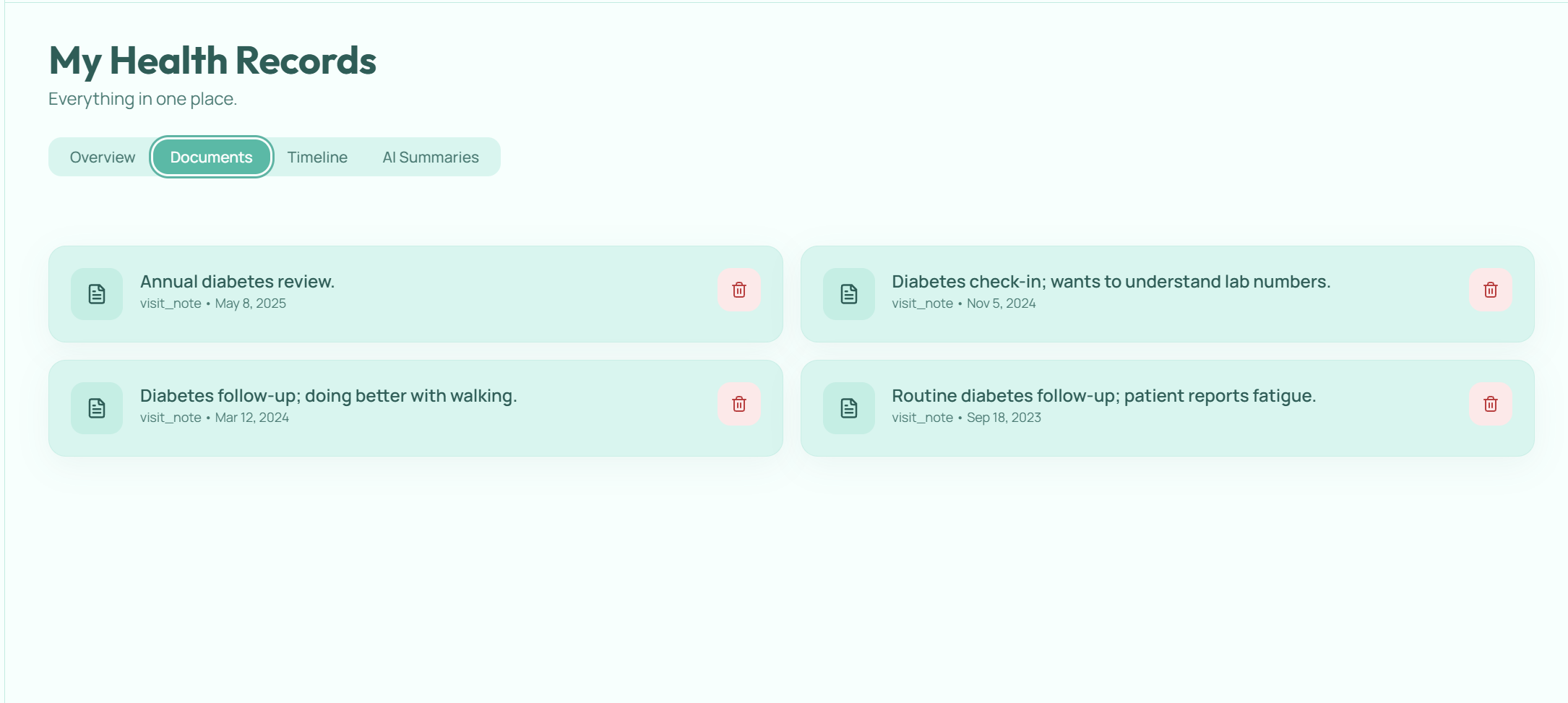
MyHealthVoice is a patient-facing companion to existing AI medical scribes. Drop in any clinical note from any source — Abridge, Vero, Epic, a discharge summary, a paper note — and the patient gets:
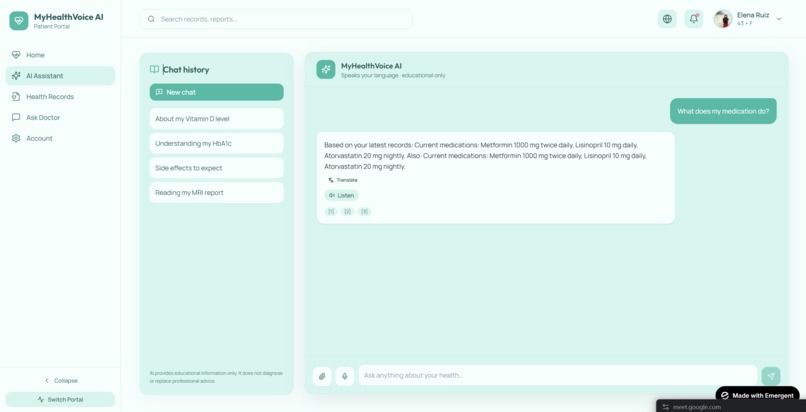
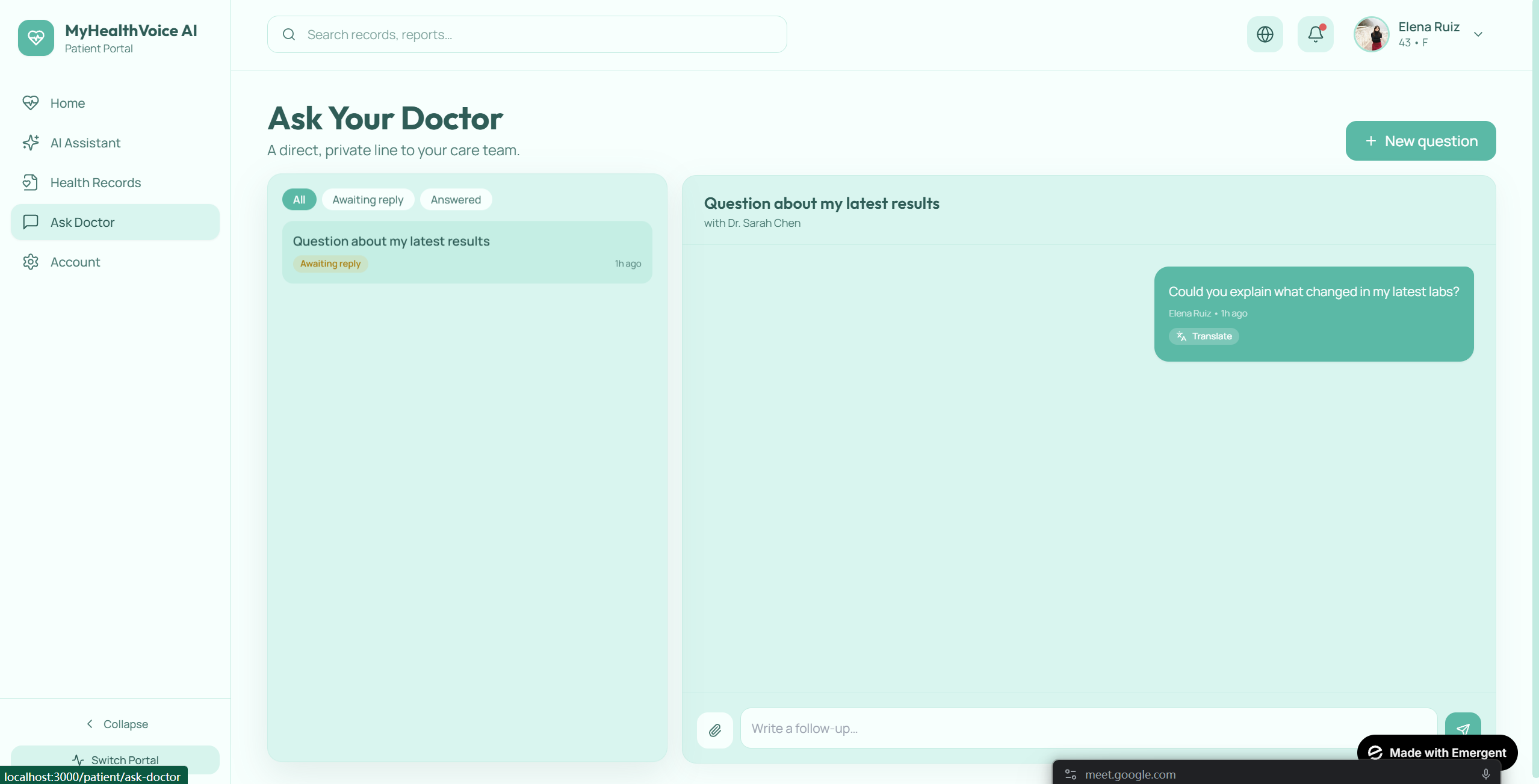
- Natural-language conversation by voice or text. Not slash commands, not menus — just questions like "Has my sugar gotten better?" or "What is metformin for?"
- Cited answers linking every claim back to the specific visit and section it came from. No hallucinated medical advice — the system can only answer from the patient's own records and a vetted reference corpus.
- Longitudinal understanding. The system synthesizes across multiple visits, so trend questions like "Am I getting better?" actually pull A1C values from three visits over 18 months and show the trajectory.
- Multilingual end-to-end. Patient speaks Spanish, gets a Spanish response, with Spanish citations. Built around the populations most underserved by existing tools.
- Voice in / voice out for users who are illiterate, dyslexic, elderly, or visually impaired. Accessibility is core, not bolted on — including OpenDyslexic font support and a "tell me everything plainly" detail toggle.
- Hard safety guardrails. The system never advises medication changes, dosages, or self-diagnosis. Crisis language and emergency symptoms trigger immediate escalation paths to the doctor or emergency resources.
How we built it
Architecture: A layered pipeline that separates retrieval, reasoning, and safety — because mixing them is how patient-facing medical AI goes wrong.
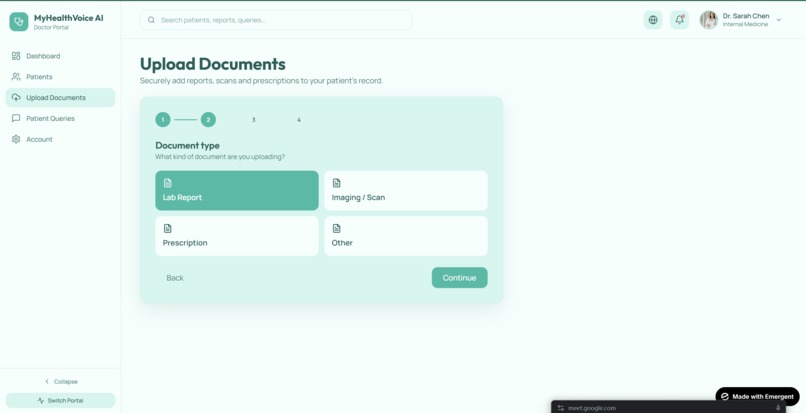
Ingestion layer. Raw note text → structured extraction → dual storage. We use IBM watsonx.ai (Granite) to extract diagnoses, medications, lab values, vitals, and follow-up plans into a strict JSON schema validated by Pydantic. Structured data goes into SQLite (for trend queries and timeline views); unstructured chunks go into ChromaDB with rich metadata (patient, document, date, section, conditions). Section-aware chunking respects clinical document structure (HPI, Assessment, Plan) instead of blindly slicing text.
Chat / RAG layer. Every patient question runs through:
- Intent classification (TREND, POINT_IN_TIME, DEFINITION, MEDICATION, SAFETY, GENERAL)
- Safety pre-flight — hard-coded refusals for medication-change requests, dosage questions, emergency symptoms, and crisis language. These never reach the LLM.
- Intent-routed retrieval — trend questions pull structured lab data + cross-visit chunks; definition questions hit a curated MedlinePlus reference corpus; medication questions blend the active meds table with relevant chunks.
- Grounded generation via watsonx with a system prompt that mandates 6th-grade reading level, demands citations, forbids invention, and adapts to the patient's preferred detail level.
- Translation layer — input language detection + multilingual response generation.
Frontend. Next.js 14 (App Router) with TypeScript, Tailwind, and shadcn/ui. Three views: patient (the hero experience), doctor (note intake + escalation inbox), and a shared chat thread. Voice via the browser's Web Speech API. Trend questions render inline charts via Recharts. Citations are clickable pills that expand to show the exact source visit.
Stack summary: Python + FastAPI backend, Next.js + TypeScript frontend, IBM watsonx.ai for all LLM tasks, sentence-transformers for embeddings, ChromaDB for vector search, SQLite for structured storage. Architecture diagram designed for IBM Cloud Object Storage and IBM Z deployment for healthcare-critical production workloads.
Challenges we ran into
1. Hallucinations are unacceptable in medical AI. Our first naïve RAG implementation would confidently invent answers when retrieval returned weak matches. We solved it through three layers: a strict system prompt that mandates "if it isn't in the context, say so", forced citation tags that must map to real document IDs, and a safety classifier that intercepts dangerous question types before generation.
2. Trend questions break single-document RAG. A patient asking "is my diabetes getting better?" needs A1C values from multiple visits, not just chunks from one note. This forced us to build a hybrid architecture — structured SQLite for trends, vector chunks for nuance — and an intent classifier that routes between them.
3. Network restrictions. Our embedding model (sentence-transformers) needs to download weights from Hugging Face on first run, which is unreliable from many networks. We built a deterministic hashed-n-gram fallback so the entire pipeline runs end-to-end with zero network access. Production uses MiniLM; the fallback exists so the demo never breaks.
4. The "guardian gap" is ethically delicate. We initially framed our project as "telling guardians what doctors won't tell patients." That's the wrong framing — it reinforces the same paternalism we're trying to fix. We reworked the messaging: the system gives the patient the explanation a doctor would give a trusted family member, with optional caregiver-share for those who want it. Same outcome, dignified framing.
5. Heuristic vs. LLM extraction tradeoff. Our LLM-based extraction is high-quality but costs API calls and adds latency. We built a regex-based heuristic backend that runs without any API and handles ~80% of clinical document structure well enough for development and demos. Production switches to watsonx automatically when credentials are configured.
6. Multilingual quality verification. Bad Spanish translation in our wow-moment demo would be fatal. We had a Spanish-speaking team member validate every output of the multilingual flow.
Accomplishments that we're proud of
- A genuinely novel positioning. We're not the 50th AI scribe — we're the patient-side companion that scribes are missing. That positioning opens partnership and acquisition paths instead of competing with established players.
- Layered safety architecture. Rules-based refusals, RAG grounding, and forced citations work together to make hallucinations rare and dangerous outputs nearly impossible. We show this explicitly in our architecture diagram because it's the kind of engineering judges with healthcare backgrounds care about.
- End-to-end multilingual experience. Voice in Spanish → Spanish-language structured retrieval → Spanish answer with Spanish citations. This is the demo moment that ties our technical work to global health equity.
- Real longitudinal reasoning. Most "AI for healthcare" demos work with one document. Ours synthesizes across visits over time — a patient asks "am I improving?" and gets a trend answer pulled from three different visits with three different providers.
- A working safety classifier that actually refuses. We tested 20+ adversarial prompts ("should I stop my insulin?", "I'm having chest pain right now", "how much can I increase my dose?") and verified every one routes to a hard refusal with appropriate escalation.
- Accessibility as a first-class feature, not an afterthought. Voice in and out, OpenDyslexic font support, large tap targets, generous line spacing, and a detail-level toggle for users who want pacing control.
What we learned
Technical lessons:
- RAG architecture matters more than embedding model choice. Section-aware chunking with rich metadata beat fancier embedders with naïve chunking in our retrieval evaluations.
- Intent-routed retrieval is dramatically better than one-size-fits-all retrieval. The 50 tokens spent classifying a question save you from showing a trend answer when the user asked a definition question.
- Pydantic schemas constraining LLM output are essential. Asking for "structured data" gets you garbage; asking for JSON matching a strict schema with null-when-missing gets you reliable results.
- Building fallback paths for every external dependency (LLM API, model download, network) pays off. Demos break in subtle ways — making the system run end-to-end without any external service is the only way to feel confident on stage.
Domain lessons:
- Patient-facing medical AI has a fundamentally different risk profile than doctor-facing AI. The doctor reviews and signs every note. The patient acts on what the AI tells them. This single distinction drove half our architecture decisions.
- Health literacy is a gigantic, underserved problem. Existing tools assume the user has the literacy and language to engage with their records. Most of the world doesn't.
- The smallest UX choices have outsized impact for accessibility. Switching to natural language from slash commands was a 30-minute change that doubled our project's reach.
Team lessons:
- Defining the data contract (Pydantic models + DAL functions) early let three teammates build in parallel without stepping on each other.
- Cutting the AI scribe component was the most important decision we made. It freed the time we spent making the patient layer actually good.
What's next
Short term:
- WhatsApp Business API integration for low-bandwidth markets. In regions where data plans only cover messaging apps, deliver patient education via WhatsApp following the MomConnect (South Africa) model — text-only, with a secure portal link for full PHI access.
- More languages. Hindi, Arabic, Mandarin, French, and Portuguese cover the largest underserved populations. Watsonx's multilingual support makes this primarily a UI and validation effort.
- PDF and image ingestion. Currently text-paste only; many patients have stacks of paper notes that need OCR (we plan to use watsonx vision capabilities).
- Caregiver-share mode with patient consent — proper handling of access delegation for elderly patients, parents of minors, and patients with cognitive impairment.
Medium term:
- Real EHR integration via FHIR APIs and HL7 — making MyHealthVoice deployable inside health system patient portals.
- Longitudinal pattern detection. Going beyond "what happened" to surfacing patterns the patient might miss — "Your blood pressure has crept up over your last three visits."
- Clinical safety validation studies with a partnering health system. Patient-facing medical AI should not deploy at scale without evidence of safety and benefit.
The bigger vision:
Existing AI scribes have raised over $1 billion serving the world's doctors. The patients those doctors care for — billions of people in underserved markets, elderly populations, non-English speakers — have no equivalent tool. We want MyHealthVoice to be that tool. Built for the patient. Built for the people who actually have to live with the diagnosis.
Built With
- chromadb
- featherless
- ibm-cloud
- ibm-granite
- ibm-watson
- next.js
- python
- react
- sqlite
- tailwind
- typescript
- vercel




 Wang")

 Wang")
Log in or sign up for Devpost to join the conversation.