-
-
Institution Site(Backend)2
-
Institution Site(Backend)1
-
Institution Site(Backend)3
-
User End1(Mobile App)
-
User End2(Mobile App)
Inspiration
The US social welfare system is robust but incredibly fragmented. Single-parent families often face a daunting "information wall." Government policy documents are hundreds of pages long and written in complex legal jargon. As a result, millions of dollars in aid go unclaimed simply because people don't know if they can apply or where to apply.
However, leveraging generic AI to solve this presents a critical dilemma. Mainstream cloud models lack the niche, fine-grained data required for localized welfare policies, inevitably leading to severe "hallucinations"—a fatal flaw when dealing with financial aid.
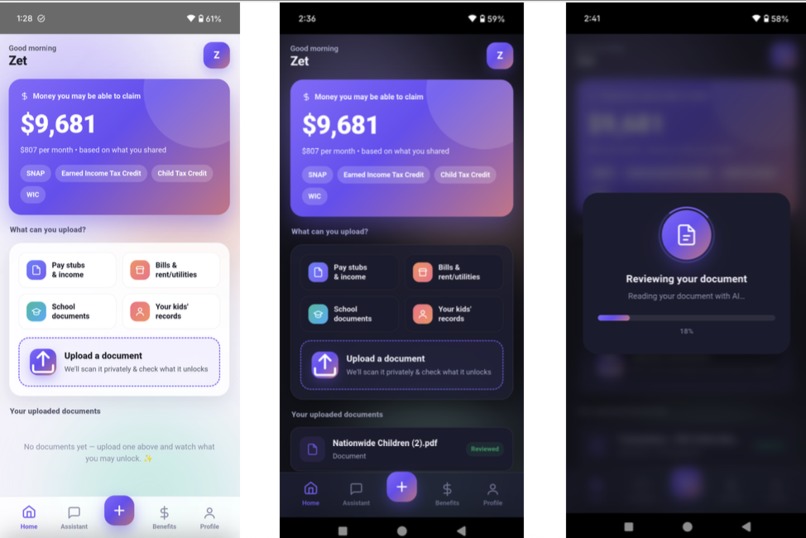
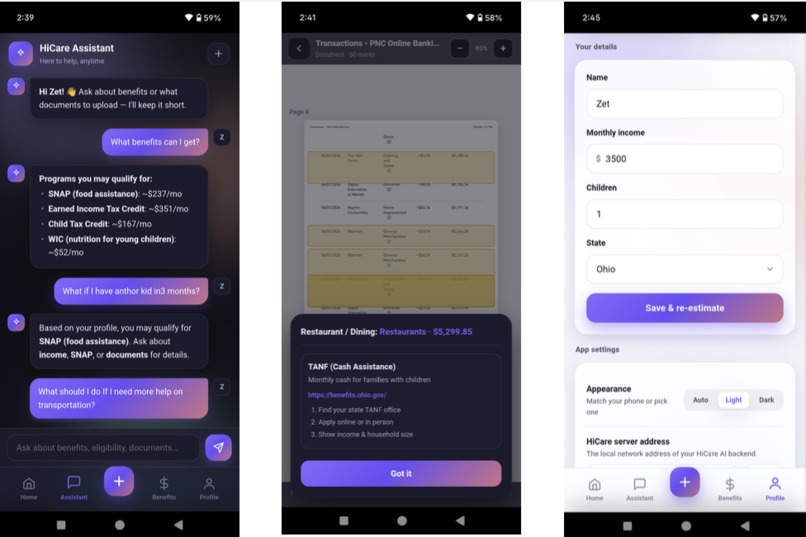
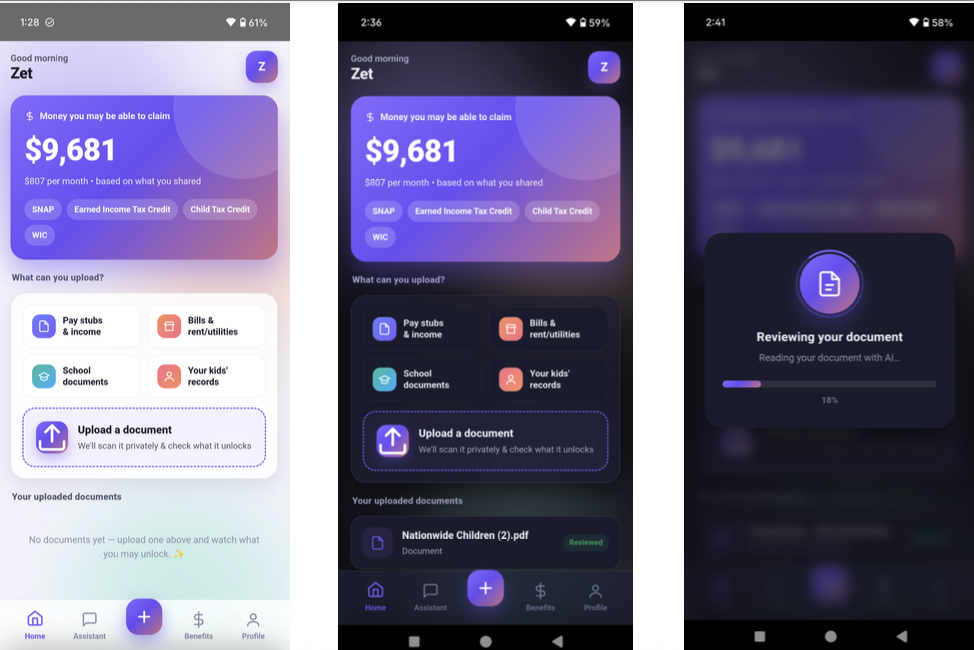
This inspired us to build HiCare AI. Our goal was to engineer a highly accurate, hallucination-free system where anyone can understand their potential benefits at a single glance. Users simply upload a digital bill to our lightweight mobile app. Our backend processes the complex matching and highlights eligible coverages directly on the document's original pixels, transforming bureaucratic text into actionable insights with direct redirects to official portals.
What it does
HiCare is a dual-sided, AI-powered welfare matching platform designed to eliminate the information barrier for low-income families with a zero learning curve.
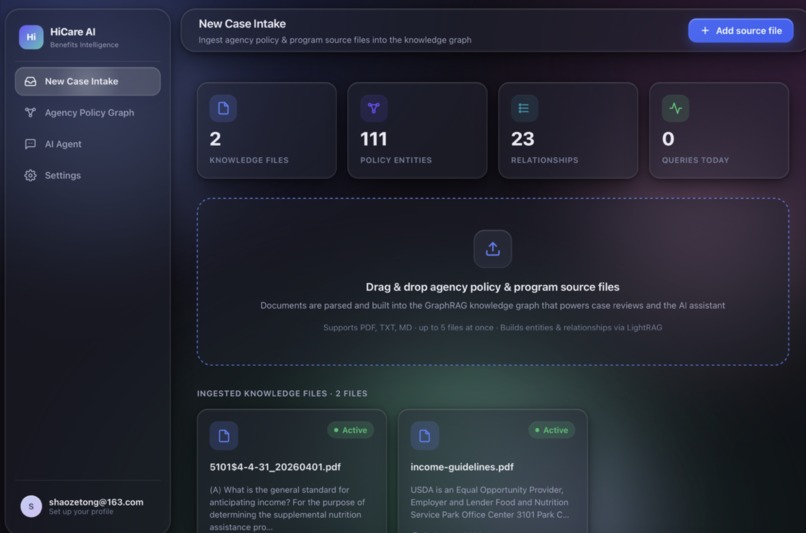
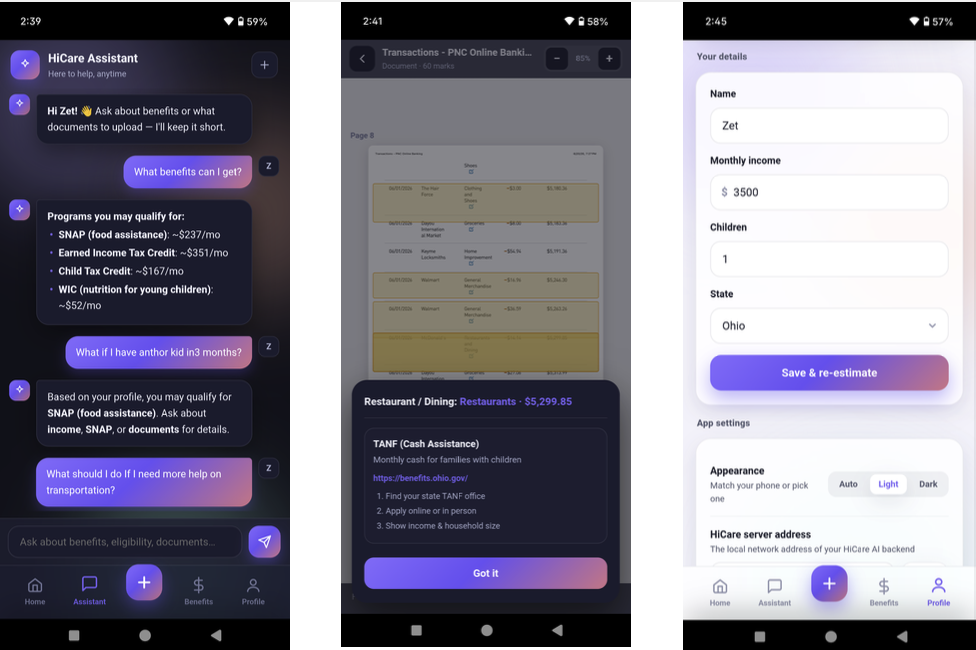
For the User (Lightweight App): Upon opening the app, users input basic demographics (age, state, dependents). Instantly, the app calculates their theoretical maximum annual benefits, providing a tangible financial goal that motivates them to proceed. Next, the user uploads their digital medical or utility bill. The backend cross-references the line items against the user's profile and the GraphRAG policy database. In seconds, the app returns the document with all potentially reimbursable expenses clearly highlighted in yellow. Crucially, to uphold Responsible AI standards, we frame these highlights strictly as "potential eligibility," keeping the human user—and ultimately the social worker—in control of the final decision. By tapping any highlighted text, users are redirected to the exact official application portal, guided by a built-in AI assistant. The application operates statelessly, ensuring no personal documents are stored after the scan.
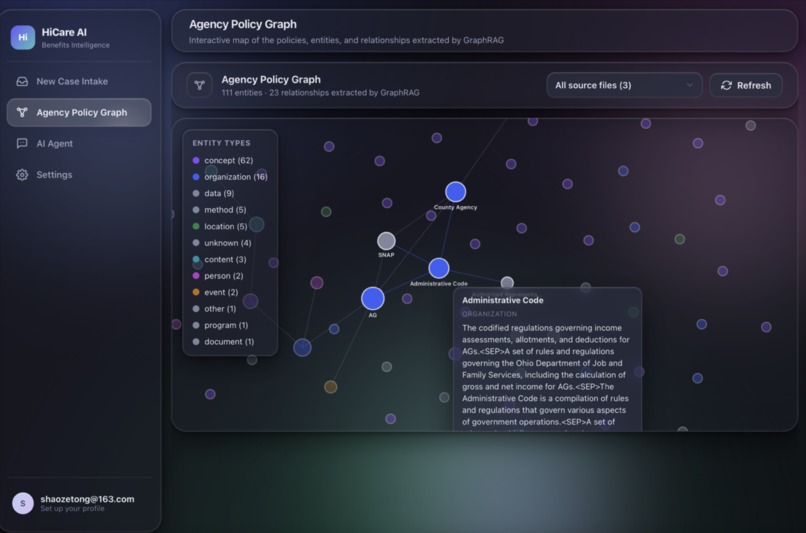
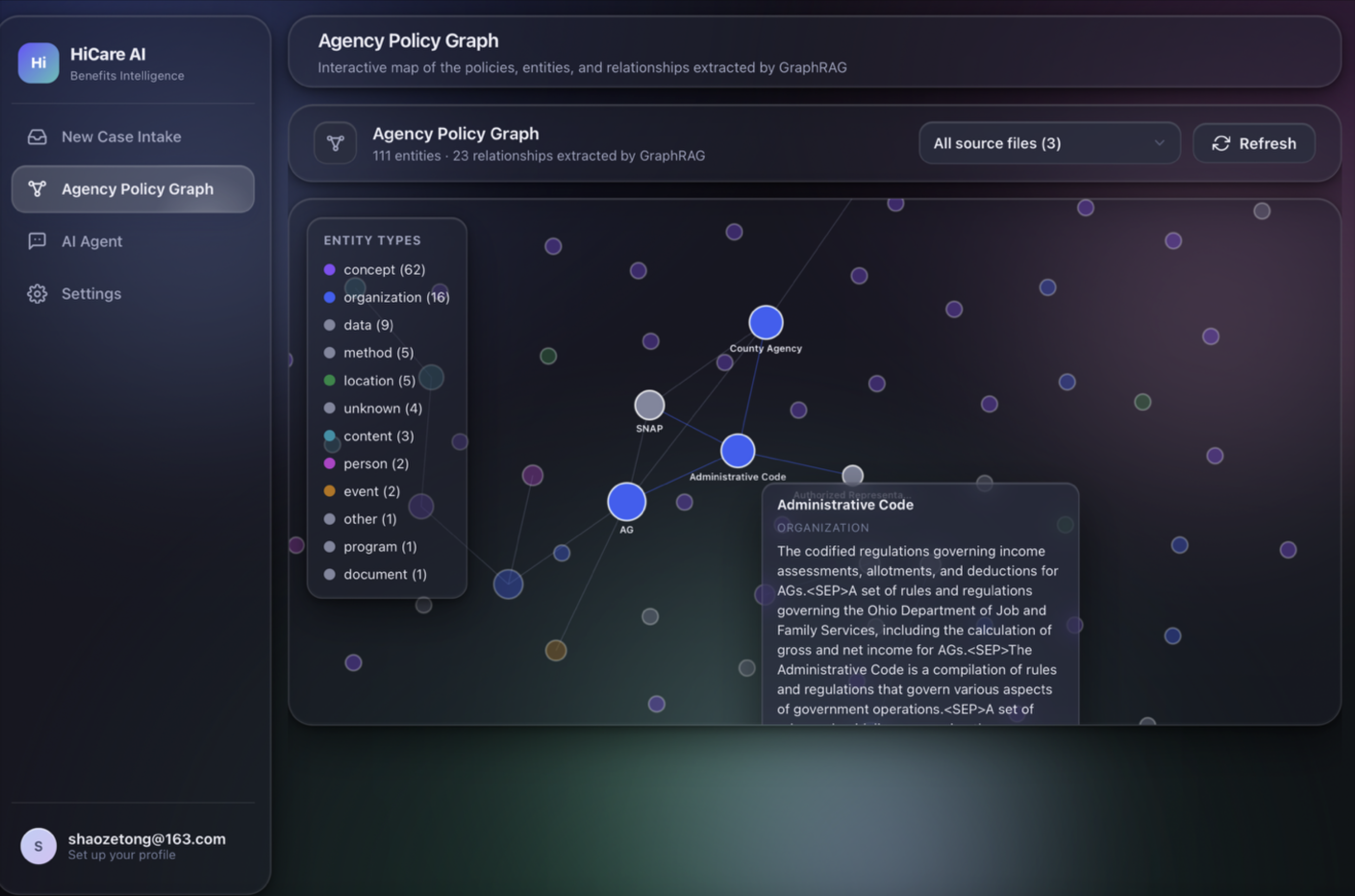
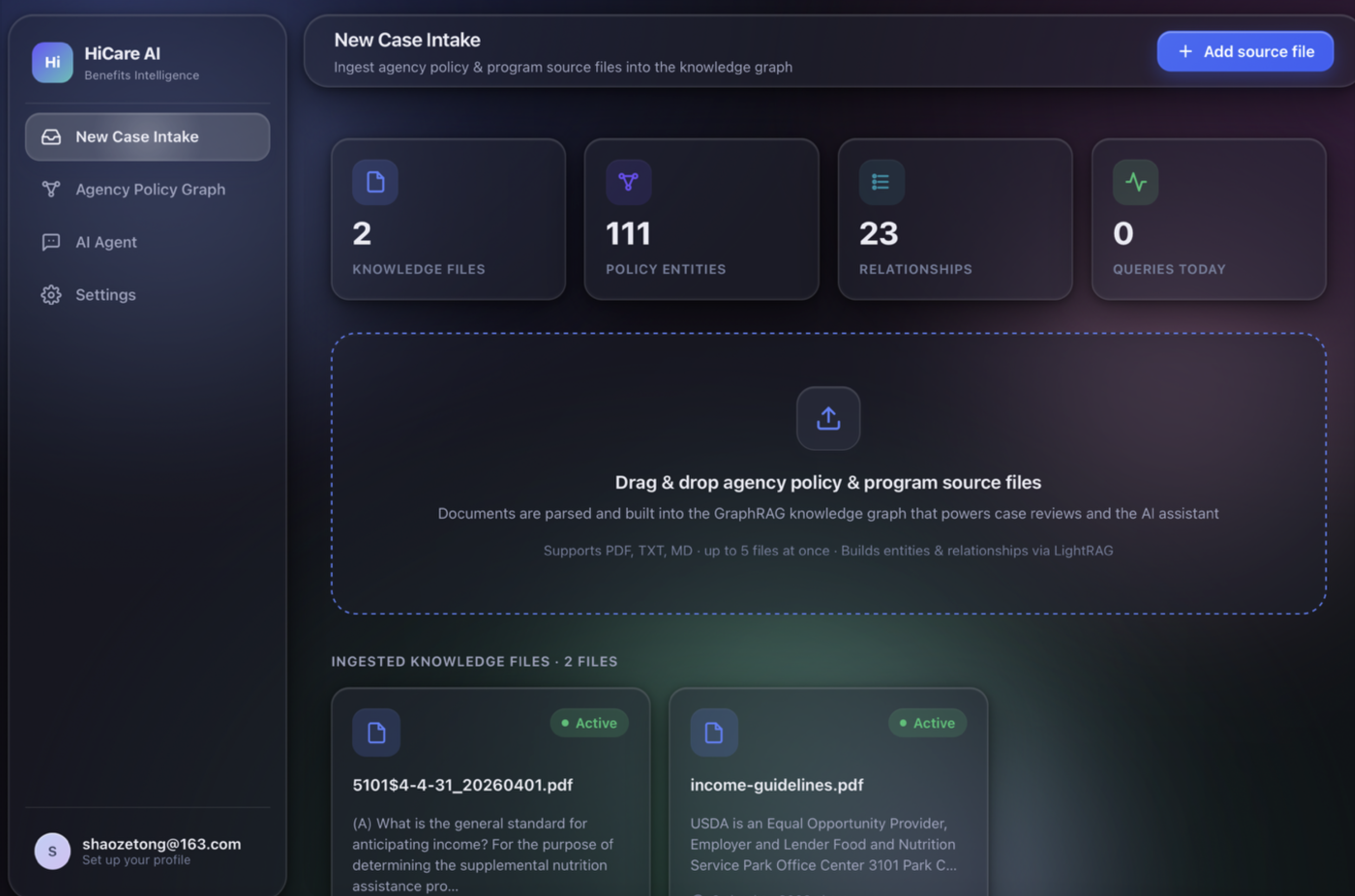
For the Welfare Institution (Agency Backend): Administrators simply upload raw, complex policy PDFs to our portal. Our system processes these using GraphRAG, instantly converting dense legal jargon into a highly structured, accurate knowledge graph without requiring manual data entry.
How we built it
We engineered a dual-node, full-stack architecture prioritizing data privacy and deterministic AI reasoning.
- 100% Local AI & Privacy Layer: Because users upload highly sensitive financial documents, sending data to cloud APIs was out of the question. We deployed Ollama locally, running a quantized Llama 3.1 model alongside an embedding model to ensure all processing remains strictly on-premise.
- The GraphRAG Engine: Standard RAG struggles with the multi-hop reasoning required for state welfare policies. We implemented LightRAG to ingest complex government PDFs and build a dynamic Knowledge Graph. When evaluating a user's document, the system traverses these entity relationships to retrieve highly accurate, context-aware legal conditions, drastically reducing hallucination.
- Visual Grounding via PyMuPDF: Instead of outputting a generic text summary, we utilized PyMuPDF to parse the uploaded digital documents. Our backend forces the LLM to map its findings back to the exact physical coordinates
(x0, y0, x1, y1)of the document. The frontend then overlays non-destructive SVG highlights directly over the text, transforming the AI from a black box into a transparent auditing tool. - The Client App & Asynchronous Backend: The backend is powered by FastAPI, utilizing asyncio tasks to handle heavy LLM generation without blocking the API. The applicant-facing interface is a responsive single-page application built with HTML/CSS/JS, wrapped in Capacitor to deploy as a native Android APK.
Challenges we ran into
Our biggest challenge was ensuring spatial accuracy for the Visual Grounding feature. Initially, the LLM struggled to accurately map extracted policy logic to the exact bounding box coordinates of the PDF. We had to heavily refine our PyMuPDF parsing pipeline to pass strict coordinate metadata alongside the text chunks to the LLM, forcing it to cite the precise location of its findings.
Accomplishments that we're proud of
We are incredibly proud to have built a fully functional, privacy-first system that operates entirely on local infrastructure. Successfully integrating GraphRAG with Visual Grounding on a mobile Android interface proves that powerful AI can be deployed safely in highly sensitive public service sectors.
What we learned
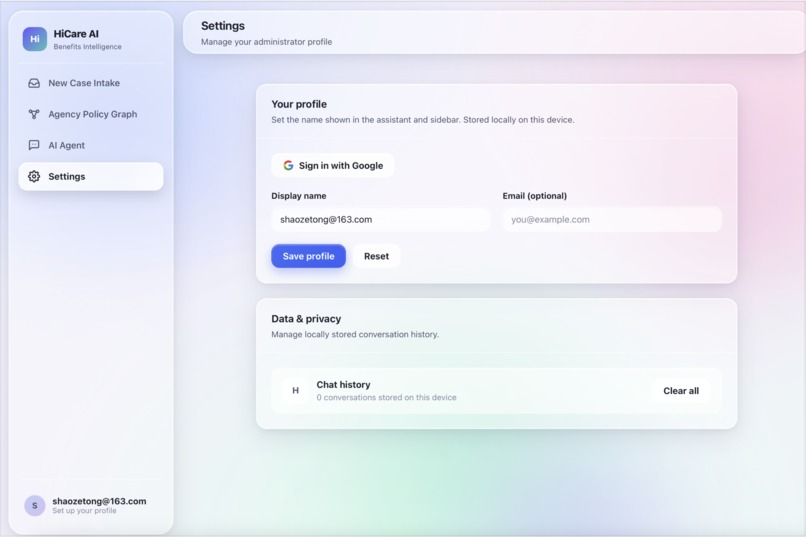
We learned that in the context of government technology and legal aid, accuracy and auditability are far more important than generative capabilities. The true value of AI here isn't writing new text, but structuring and anchoring complex legal truths into an accessible visual format. We also deepened our understanding of Responsible AI, actively designing the system to prevent users from over-relying on automated outputs.
What's next for HiCare
Currently, our Visual Grounding feature relies on PyMuPDF, which requires digital PDFs. Since many low-income families only receive physical paper bills, this creates a barrier to entry. Our immediate next step is integrating a privacy-preserving local OCR engine. This will allow users to simply scan physical paper documents and receive the exact same coordinate-mapped visual highlights, making the platform universally accessible.
Built With
- capacitor
- docker
- fastapi
- graphrag
- html/css
- javascript
- lightrag
- llama-3.1
- ollama
- pymupdf
- python


Log in or sign up for Devpost to join the conversation.