-
-

Logo
-

Log-In interface
-
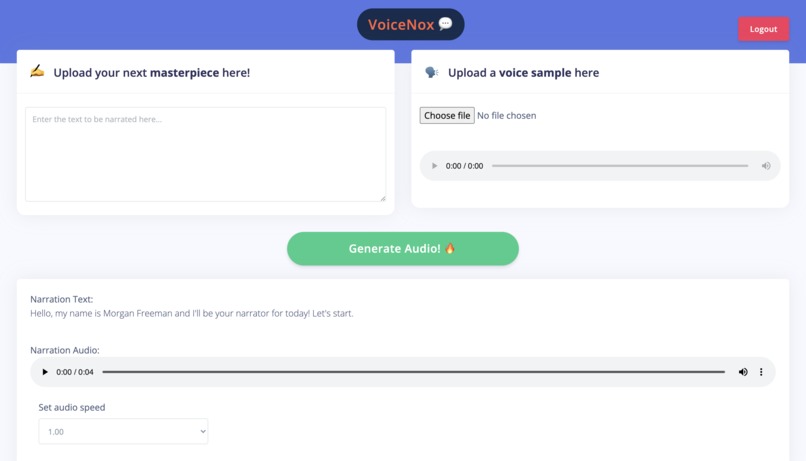
Interface for authors
-

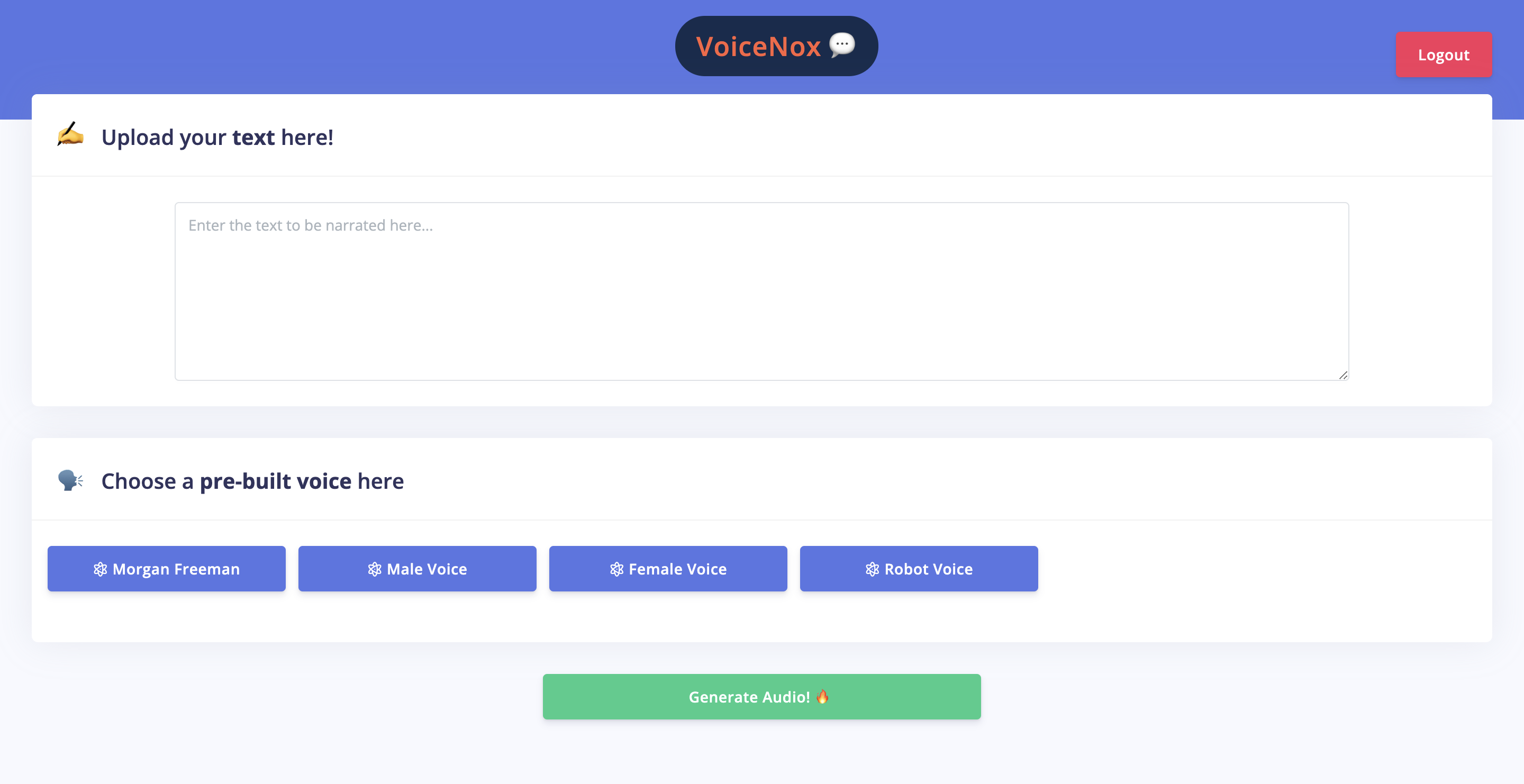
Interface for users



Pain Points
Around 600,000 to 1,000,000 books are published every year in the US alone [Forbes, 2013] and Audible currently offers around 200,000 audiobooks. This shows that there is a big disparity in terms of the text-content and audio-content available on the market for consumption.
Most authors are unwilling to make audiobooks because it requires a proper audio setup to record engaging audiobooks, and the time investment required is quite high as well.
Engagement via conventional textbooks has become increasingly difficult, especially in this virtual setting.
Audio-first applications are starting to emerge and dominate the market (see: ClubHouse, Discord Stages, Podcasts in-general)
What it does
VoiceNox is a web application built for writers/authors to easily convert their text-first books into audiobooks (narrated in the author's voice) using the state-of-the-art, open-source voice cloning model called SV2TTS (sound vector to text-to-speech).
To use the web app, authors can submit a 5-second sample of their voice and our application will then generate an audiobook of the specified text. For casual users, VoiceNox provides a selection of pre-defined voice samples which allows easy access to the narration capabilities of the application.
The 5-second audio input need not be in English, it supports all languages since the model extracts audio features using Mel Spectrograms which is independent of the speaker's language. The output however will only be in English. This, further, opens up the market for non-native English speakers who often are confined within language barriers, especially when it comes to publishing an audiobook.
VoiceNox aims to make audible formats easy to create and accessible to everyone. From people with ADHD or Dyslexia who solely rely on audiobooks to upcoming authors who don't speak English, and kids who prefer to follow along with audiobooks, VoiceNox provides a voice for everyone!
P.S. Here's an audio output that our model produced (in Morgan Freeman's voice): output
How we built it
The project uses an open-source voice-cloning (pre-trained) SV2TTS model, a three-stage deep learning framework, hosted locally in the backend over a Flask server. We had to re-engineer many parts of the model to host it locally with Flask. We defined routines to carry out audio file upload, loaded all 3 components of the model (speaker encoder, synthesizer & vocoder), and used python's SoundFile module to create .wav files for the output.
The web application was also hosted over the same Flask server. We kept our front-end pretty simple based on our team's frontend skillsets - used HTML, CSS, Bootstrap, and some Jinja to render templates.
The model is pretty scalable too since it features dynamic batch size allotment which can easily process longer input texts in roughly the same amount of time.
Challenges we ran into
The model used Tacotron for the synthesizer which we had to replace with the newer version of pre-trained .pt files manually. We also had to solve a lot of dependency issues. The model used Librosa for reading and writing the .wav files which created several issues since some features had been deprecated. We replaced it with the SoundFile module which worked out pretty well.
Accomplishments that we're proud of
Neither of us had worked with a voice cloning model previously but we were still able to make the model work which was pretty big for us as first-timers.
What we learned
We learned tons about the architecture of SV2TTS whilst working on this project. Moreover, none of us had worked with wave files before so this was definitely something new for us and we thoroughly enjoyed working on it. Finally, we learned a lot about hosting models locally over flask and creating an end-to-end ML application that we hadn't tried before.
What's next for VoiceNox
- Implement a feature to upload .epub books directly onto the web app, parse it to extract text and load it into the model
- Store speaker embeddings for pre-defined voices in storage buckets/containers so as to fetch them quickly whenever required instead of creating them from scratch every time.
- Look into OpenMined for implementing better privacy into our models.







Log in or sign up for Devpost to join the conversation.