




Inspiration
frontier VLMs can look at a construction site, but they still struggle to understand what happened in space over time.
we tested this on real hardhat/bodycam-style masonry footage. a raw model can usually say "worker," "scaffold," or "concrete block wall." but when you ask questions like:
- was masonry work happening near the wall?
- what changed between these frames?
- was the worker productive, contributory, or non-contributory?
- where did activity happen in the site?
the answers get shaky fast. the model guesses, loses temporal context, and has no persistent memory of what it just saw.
VIMA is our attempt to fix that without training a new foundation model. instead of asking a VLM to reason from raw video alone, we build an auditable spatial evidence layer first.
What it does
VIMA turns egocentric construction footage into structured spatial memory.
the system processes construction video into:
- frame-level CII productivity labels: productive, contributory, non-contributory
- object detections from construction frames
- optional semantic boxes from Gemini Robotics-ER
- merged object boxes
- SAM-style masks
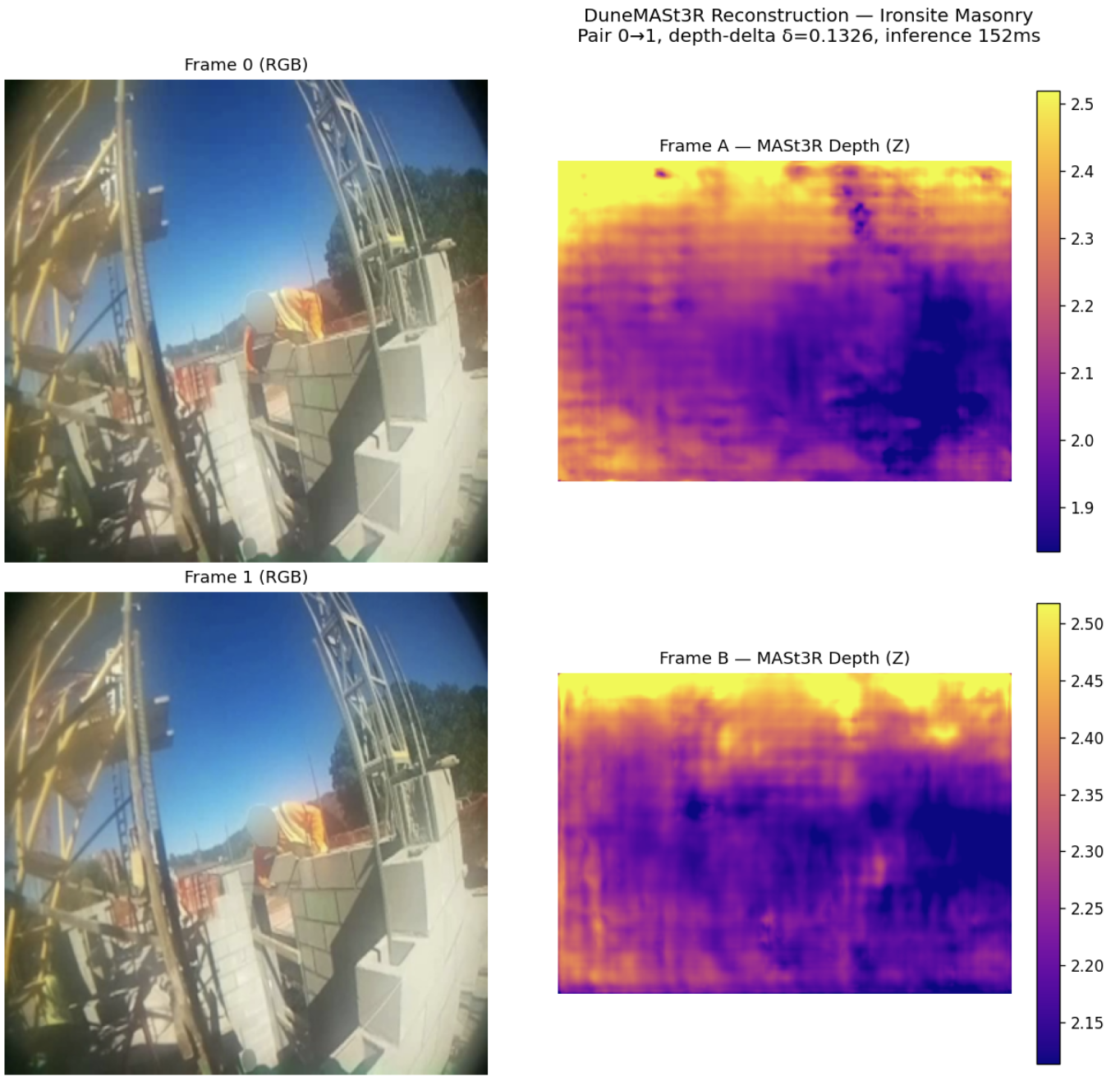
- depth estimates
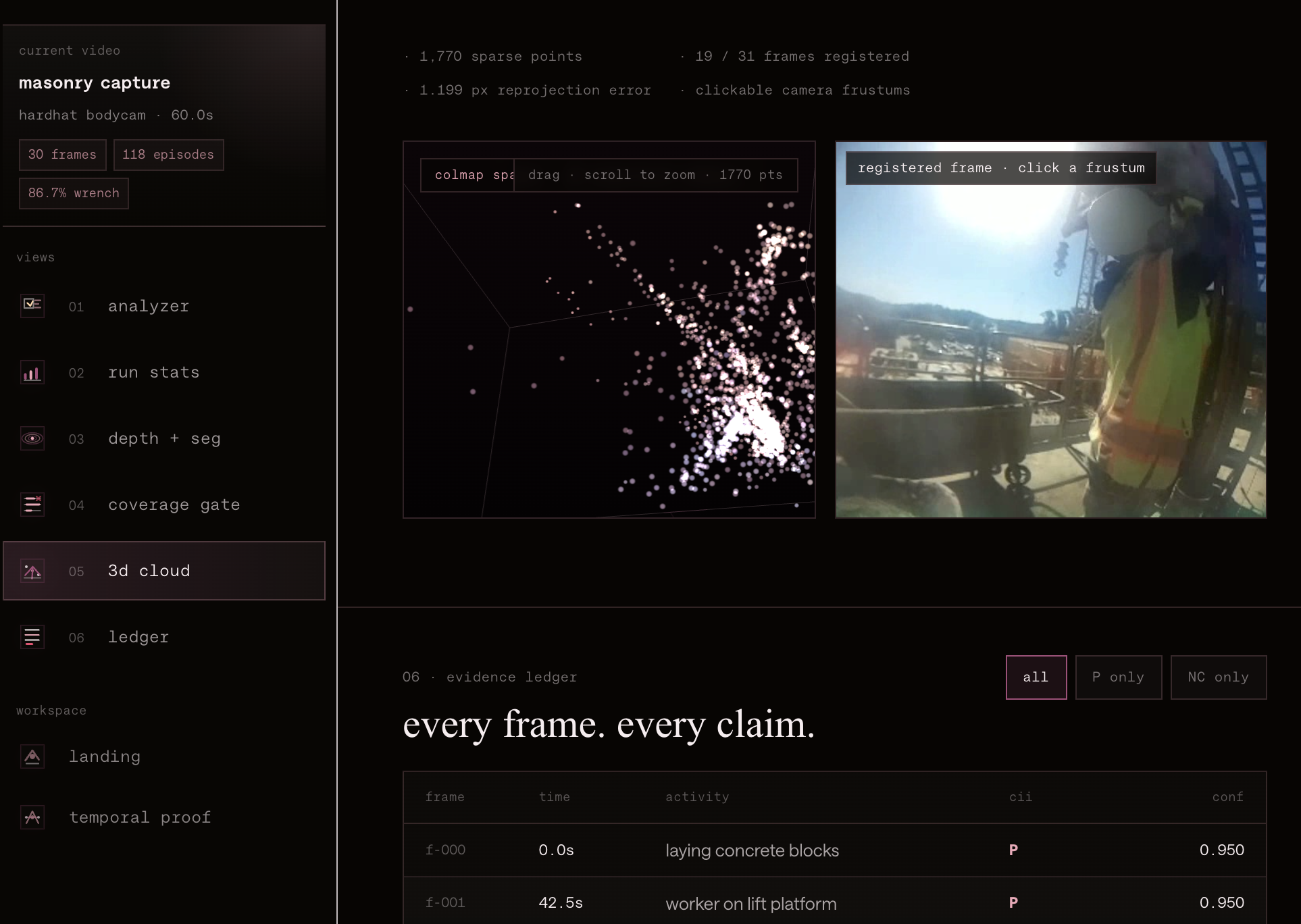
- spatial zones from COLMAP-style camera pose clustering
- event episodes with timestamps, evidence frames, tracks, depth facts, and retrieval text
- cited answers from retrieved memory
in the current demo, VIMA analyzes real masonry footage and exposes the evidence through a hosted dashboard, API, CLI, and MCP server.
headline demo results:
- 30 sampled masonry frames
- 26 productive frames
- 4 non-contributory frames
- 86.7% wrench time
- 0.939 mean confidence on productive frames
- 118 temporal episodes in the frontend evidence workspace
- VLM-only spatial score: 0.600
- VLM + memory spatial score: 0.792
- +33.2% improvement across 5 spatial questions
How we built it
the core idea is evidence first, answer second.
hardhat footage
-> sampled frames
-> object boxes
-> optional Gemini Robotics-ER boxes
-> box merge
-> masks
-> depth
-> object-event episodic memory
-> retrieved evidence
-> cited VLM answer
we built several layers:
1. backend spatial API
the backend is a FastAPI service with endpoints for health checks, frame analysis, CII summaries, frame-level evidence, spatial zones, and temporal evals.
important endpoints include:
GET /health
POST /analyze/frame
GET /cii/summary
GET /cii/frames
GET /spatial/zones
GET /eval
POST /temporal/run
2. CII productivity classification
VIMA classifies each sampled frame using the construction industry institute style categories:
- P: productive
- C: contributory
- NC: non-contributory
the demo run produced 26 productive frames out of 30, which gives 86.7% wrench time.
3. spatial memory pipeline
we use object boxes, masks, and depth estimates to build object-event memory. the checked-in demo memory includes 10 frame-based episodes and 35 frame events, including:
- masonry work candidates
- scaffold zone visibility
- safety edge context
- foreground worker presence
- material staging visibility
4. temporal reasoning eval
we compare raw single-frame reasoning against memory-augmented reasoning. the memory version gives the model before/after context, evidence frames, and structured event claims instead of asking it to infer changes from one frame at a time.
our checked-in eval shows:
VLM-only: 0.600
VLM + memory: 0.792
improvement: +33.2%
questions improved: 5 / 5
5. frontend and agent interfaces
we built a Next.js frontend with:
- landing page
- live demo workspace
- frame ledger
- CII stats
- temporal proof page
- review interface
- depth / segmentation / reconstruction visuals
we also built a portable vima-agent CLI and MCP server so other agents can inspect the same evidence programmatically.
6. mobile field companion
we also built a mobile-first companion app for the people actually closest to the jobsite.
the mobile flow turns VIMA's scene ledger into quick verification cards. a worker or supervisor can swipe through claims like "masonry work continues along the open wall edge" or "worker at elevated masonry edge with no fall protection," then confirm, reject, or skip each claim.
we connected that flow to a lightweight Solana incentive layer: verified work and claim review can earn raffle progress, and the prototype includes SOL reward states plus a payout queue for wallet addresses. the intent is to make verified field feedback feel immediate while keeping the actual evidence trail tied back to VIMA's spatial ledger.
the prototype includes:
- swipe-based claim review
- xp, levels, and streaks for completed verification
- raffle unlocks after repeated verified claims
- a lottery wheel for xp or SOL rewards
- payout queue flow for a wallet address
- Capacitor config so the web prototype can become a native mobile shell
the point is not to make construction work feel like a game for its own sake. the point is to close the loop: VIMA produces spatial claims from video, and the mobile app gives field teams a fast way to verify or dispute those claims while keeping the audit trail alive.
what makes it different
most construction vision demos stop at detection or classification.
VIMA is focused on auditable spatial memory.
instead of saying:
"the worker is doing masonry."
VIMA can point to the supporting episodes, frames, tracks, and spatial facts that led to the answer.
for example, when asked:
was there masonry work happening near the wall?
the memory-backed Gemini answer retrieved 4 relevant episodes and cited specific frame evidence showing workers near a concrete block wall. it also preserved uncertainty by calling them "masonry_work_candidate" events instead of overstating the claim.
that evidence trail is the whole point. construction teams do not just need a confident answer. they need a checkable one.
Challenges we ran into
construction footage is messy as hell.
the camera moves constantly, objects are partially visible, lighting changes, workers block each other, and the same wall can appear from several different angles. raw frame-level VLM answers were often plausible but ungrounded.
we also had to decide what story mattered most. the repo has several working pieces: CII productivity, spatial zones, temporal memory, masks, depth, agent tooling, and a Solana-based reward concept. the hard part was turning that into one coherent product:
VIMA builds spatial memory from hardhat footage, then uses that memory to make construction video answers auditable.
another challenge was making the demo practical. some local model paths, like Qwen-VL, were not reliable enough to depend on for the live flow, so we focused the demo around the artifacts and services that worked consistently.
Accomplishments that we're proud of
we got a real end-to-end system working across backend, frontend, evaluation, and agent surfaces.
we are proud of:
- the hosted API and dashboard at
vimaspatial.tech - 30-frame masonry CII evidence with 86.7% wrench time
- temporal memory with 118 frontend episodes
- an A/B eval showing +33.2% improvement from memory augmentation
- object-event memory with masks, depth, tracks, relations, and cited retrieval
- a CLI and MCP server so agents can query the same evidence as humans
- a demo that shows not just model output, but the evidence behind it
What we learned
the biggest lesson is that the model is not always the missing piece. sometimes the missing piece is memory.
VLMs are strong at recognizing objects, but construction intelligence needs more than object recognition. it needs temporal state, spatial grounding, and evidence that can be inspected later.
we also learned that uncertainty is valuable. a system that says "this looks like masonry work, and here are the frames that support that claim" is more useful than a system that confidently invents progress.
What's next for vima
next, we would extend VIMA into a fuller construction intelligence layer:
- run the robotics box pipeline across many frames, not just selected frames
- use registered COLMAP camera poses for production zone attribution
- improve multi-visit change detection across different walkthroughs
- add stronger object tracking over longer videos
- expand the eval set beyond the current 5-question A/B comparison
- make the dashboard a full evidence browser for frames, boxes, masks, depth, episodes, and final answers
- connect VIMA to construction workflows for progress tracking, safety review, and productivity reporting





Log in or sign up for Devpost to join the conversation.