-
-
Home page
-
Preselected companies
-
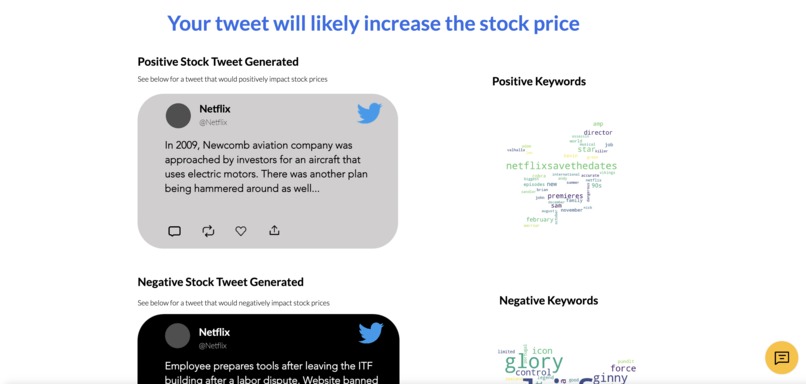
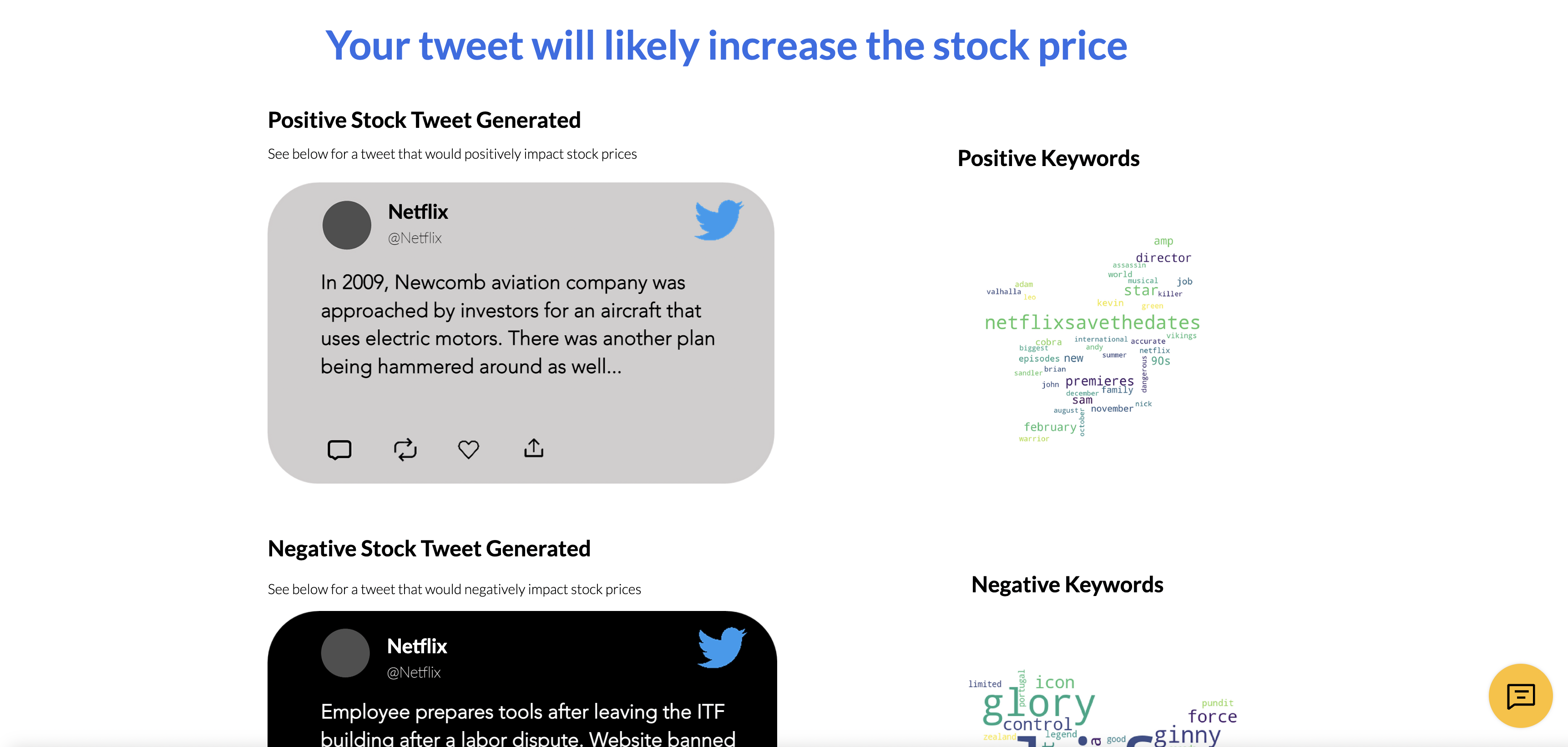
Tweet and word cloud output
Inspiration
Twitter tweets, without a doubt, have significant effects on the stock price of a company. The best example is Elon Musk's tweets and their wild effects on Tesla's stock price. Even more recently, the introduction of the paid verified blue tick by Twitter led to people posting tweets impersonating private companies, which in most cases led to plummets in stock prices. Considering all of this, we were interested in doing something that addressed this issue, and thus, StockTweet was born!
What it does
StockTweet allows users to analyze the tweets of any publicly traded company to determine keyword trends that emerge in ones that lead to a stock price uplift and ones that lead to a decrease. Users can also input a sample tweet before posting it to the world to check if it may have some potentially undesirable effect on a company's stock price and visualize the output in a beautiful word cloud. As expected, the target audience for this program would be business owners, whose company is publicly traded, or even the PR team at a large company.
How we built it
A project of this size, unsurprisingly, has a complex implementation. The front-end is built entirely using Velo by Wix. It serves as the face of the project and allows the user to interact with the software, such as submitting inputs like the company name, Twitter handle, and sample tweet. It is served by a Flask server, a lightweight python backend framework hosted on Google Cloud, where the heavy lifting takes place, and all other resources and endpoints of our application meet. MongoDB is used to store the tweets of the six most common companies, namely Google, Meta, Microsoft, Tesla, Amazon, and Netflix. This facilitates faster performance for what we hypothesize to be popular queries by users. If the user-entered company is not among these, the server instead calls upon a library that scrapes Twitter for tweets in real-time, getting the tweet text and the date/time it was posted. This information is used by another function to access the stock price change of the company in the 24 hour period after the tweet was posted. As such, each tweet is classified as having either increased or reduced the stock price. The tweet is then further decomposed into important keywords, sorted based on their impact on the stock. An aggregate is performed, and specific keywords are associated with certain stock movements. These keywords are then used to create the word cloud visualization to help the user better interpret the results. Additionally, the keywords are used by OpenAI's GPT-2 language model to generate an example tweet of something that may increase the stock price or decrease it. The user-entered sample tweet comes into play in this step. A word2vec model is trained and used to generate the similarity score of any two words. This is done for each keyword of the tweet, and whichever category has the higher similarity score at the end is returned as the category of the sample tweet. As can be seen, the tech stack is incredibly diverse, with a multitude of amazing features implemented and made available to the user for maximum utility.
Challenges we ran into
The limited computational power among our team's laptops and the lack of time were our team's most prominent problems during this event. We wanted to make sure our models were as best as they could be and our backend infrastructure as reliable and fast as possible, but unfortunately, there were many corners that we had to cut. For one, we had to use tiny datasets and, consequently, less powerful models that sometimes outputted nonsensical results. Even with all of this, we are confident in that what we were able to accomplish certainly shows the potential of our idea!
Accomplishments that we're proud of
Regardless of whatever challenges we faced, we are proud that we saw this project to the end. The all-nighters that we had to put in just to ensure that we had enough time to implement everything that we wanted to do demonstrates the determinism of each team member, and that is something to be happy about!
What we learned
In an effort to qualify for as many challenges as we could, we tried to incorporate whatever technology that challenge demanded into our tech stack, even though we had never encountered them before. However, this presented us with an opportunity to learn and use something new, and that kind of opportunity is never a bad thing. I am sure all of us took away something from this event that we did not know before, be it technical skills, like snscrape or gensim, or just getting to know someone else; we can say for sure that it was all worth it in the end!
What's next for StockTweet
The lack of time and computing power certainly posed an obstacle to us since we had some ambitious plans for the project. This, however, does not mean that the future is fixed. We truly believe that our product has so much potential that if it were given sufficient resources, it would turn into an incredible piece of software, with more complex models, and extended functionality, like using other social media sites, such as Instagram. We, ourselves, are excited to see where we can take it, and what kind of impact it can have on businesses and the financial industry! #stocksgobrr
Built With
- flask
- gensim
- google-cloud
- gpt-2
- matplotlib
- mongodb
- python
- snscrape
- spacy
- tensorflow
- transformers
- velobywix
- wordcloud
- yfinance

Log in or sign up for Devpost to join the conversation.