-
-

Thumbnail
-
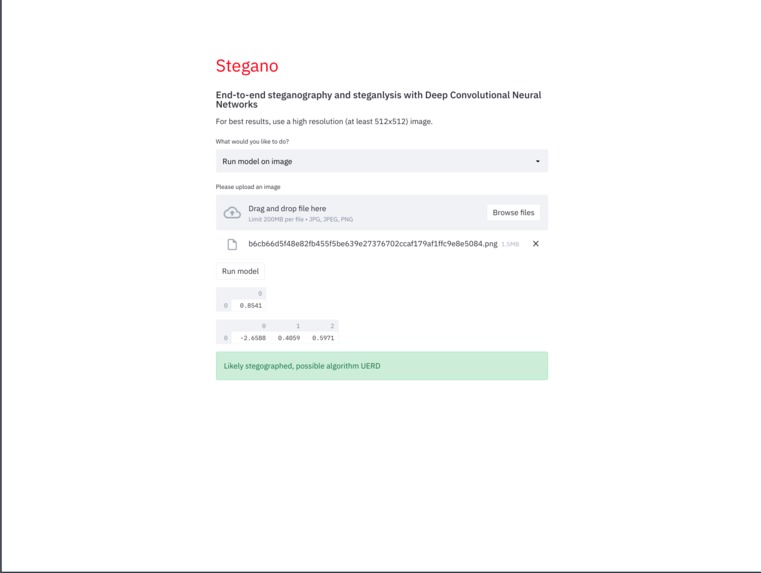
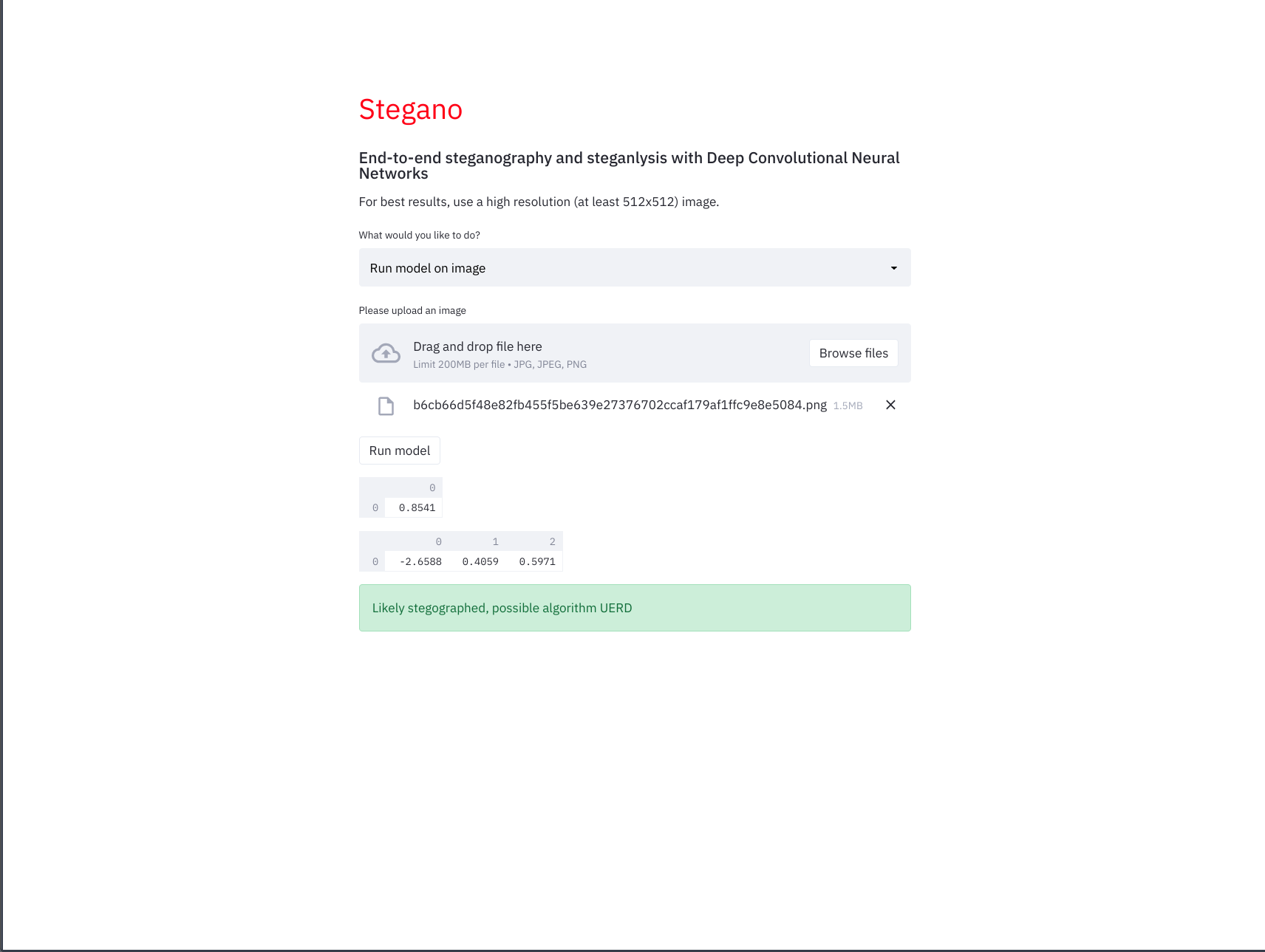
Running the model on a steganographed image
-
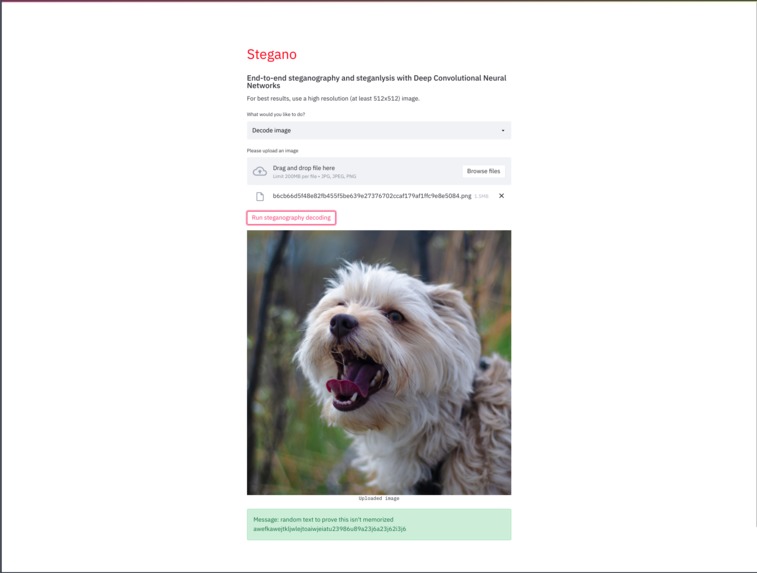
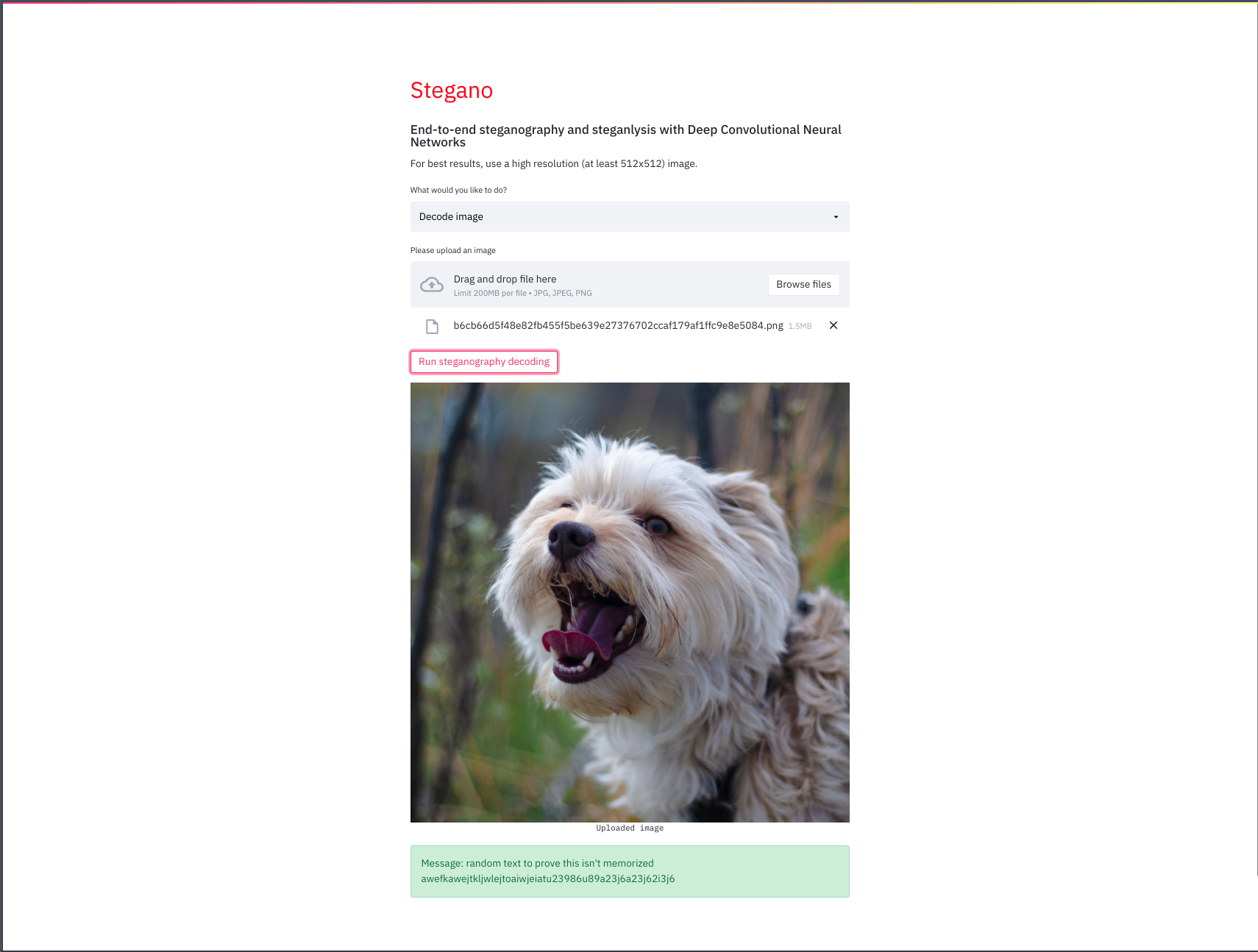
Steganographed image decoding

Stegano
End-to-end steganalysis and steganography tool
Demo at https://stanleyzheng.tech
Please see the video before reading documentation, as the video is more brief: https://youtu.be/47eLlklIG-Q
A technicality, GitHub user RonanAlmeida ghosted our group after committing react template code, which has been removed in its entirety.
What is steganalysis and steganography?
Steganography is the practice of concealing a message within a file, usually an image. It can be done one of 3 ways, JMiPOD, UNIWARD, or UERD. These are beyond the scope of this hackathon, but each algorithm must have its own unique bruteforce tools and methods, contributing to the massive compute required to crack it.
Steganoanalysis is the opposite of steganography; either detecting or breaking/decoding steganographs. Think of it like cryptanalysis and cryptography.
Inspiration
We read an article about the use of steganography in Al Qaeda, notably by Osama Bin Laden[1]. The concept was interesting. The advantage of steganography over cryptography alone is that the intended secret message does not attract attention to itself as an object of scrutiny. Plainly visible encrypted messages, no matter how unbreakable they are, arouse interest.
Another curious case was its use by Russian spies, who communicated in plain sight through images uploaded to public websites hiding steganographed messages.[2]
Finally, we were utterly shocked by how difficult these steganographs were to decode - 2 images sent to the FBI claiming to hold a plan to bomb 11 airliners took a year to decode. [3] We thought to each other, "If this is such a widespread and powerful technique, why are there so few modern solutions?" Therefore, we were inspired to do this project to deploy a model to streamline steganalysis; also to educate others on stegography and steganalysis, two underappreciated areas.
What it does
Our app is split into 3 parts. Firstly, we provide users a way to encode their images with a steganography technique called least significant bit, or LSB. It's a quick and simple way to encode a message into an image.
This is followed by our decoder, which decodes PNG's downloaded from our LSB steganograph encoder. In this image, our decoder can be seen decoding a previoustly steganographed image:

Finally, we have a model (learn more about the model itself in the section below) which classifies an image into 4 categories: unstegographed, MiPOD, UNIWARD, or UERD. You can input an image into the encoder, then save it, and input the encoded and original images into the model, and they will be distinguished from each other. In this image, we are inferencing our model on the image we decoded earlier, and it is correctly identified as stegographed.

How I built it (very technical machine learning)
We used data from a previous Kaggle competition, ALASKA2 Image Steganalysis. This dataset presented a large problem in its massive size, of 305 000 512x512 images, or about 30gb. I first tried training on it with my local GPU alone, but at over 40 hours for an Efficientnet b3 model, it wasn't within our timeline for this hackathon. I ended up running this model on dual Tesla V100's with mixed precision, bringing the training time to about 10 hours. We then inferred on the train set and distilled a second model, an Efficientnet b1 (a smaller, faster model). This was trained on the RTX3090.
The entire training pipeline was built with PyTorch and optimized with a number of small optimizations and tricks I used in previous Kaggle competitions.
Top solutions in the Kaggle competition use techniques that marginally increase score while hugely increasing inference time, such as test time augmentation (TTA) or ensembling. In the interest of scalibility and low latency, we used neither of these. These are by no means the most optimized hyperparameters, but with only a single fold, we didn't have good enough cross validation, or enough time, to tune them more. Considering we achieved 95% of the performance of the State of the Art with a tiny fraction of the compute power needed due to our use of mixed precision and lack of TTA and ensembling, I'm very proud.
One aspect of this entire pipeline I found very interesting was the metric. The metric is a weighted area under receiver operating characteristic (AUROC, often abbreviated as AUC), biased towards the true positive rate and against the false positive rate. This way, as few unstegographed images are mislabelled as possible.
What I learned
I learned about a ton of resources I would have never learned otherwise. I've used GCP for cloud GPU instances, but never for hosting, and was super suprised by the utility; I will definitely be using it more in the future.
I also learned about stenography and steganalysis; these were fields I knew very little about, but was very interested in, and this hackathon proved to be the perfect place to learn more and implement ideas.
What's next for Stegano - end-to-end steganlaysis tool
We put a ton of time into the Steganalysis aspect of our project, expecting there to be a simple steganography library in python to be easy to use. We found 2 libraries, one of which had not been updated for 5 years; ultimantely we chose stegano[4], the namesake for our project. We'd love to create our own module, adding more algorithms for steganography and incorporating audio data and models.
Scaling to larger models is also something we would love to do - Efficientnet b1 offered us the best mix of performance and speed at this time, but further research into the new NFNet models or others could yeild significant performance uplifts on the modelling side, but many GPU hours are needed.











Log in or sign up for Devpost to join the conversation.