-
-
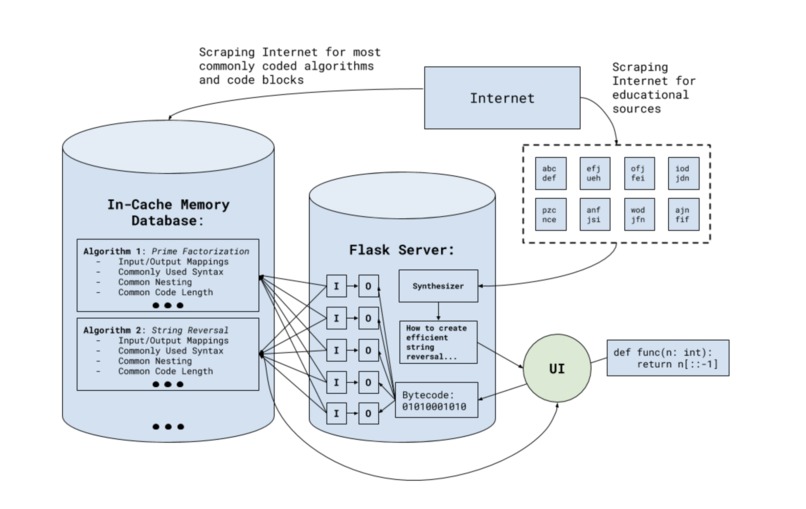
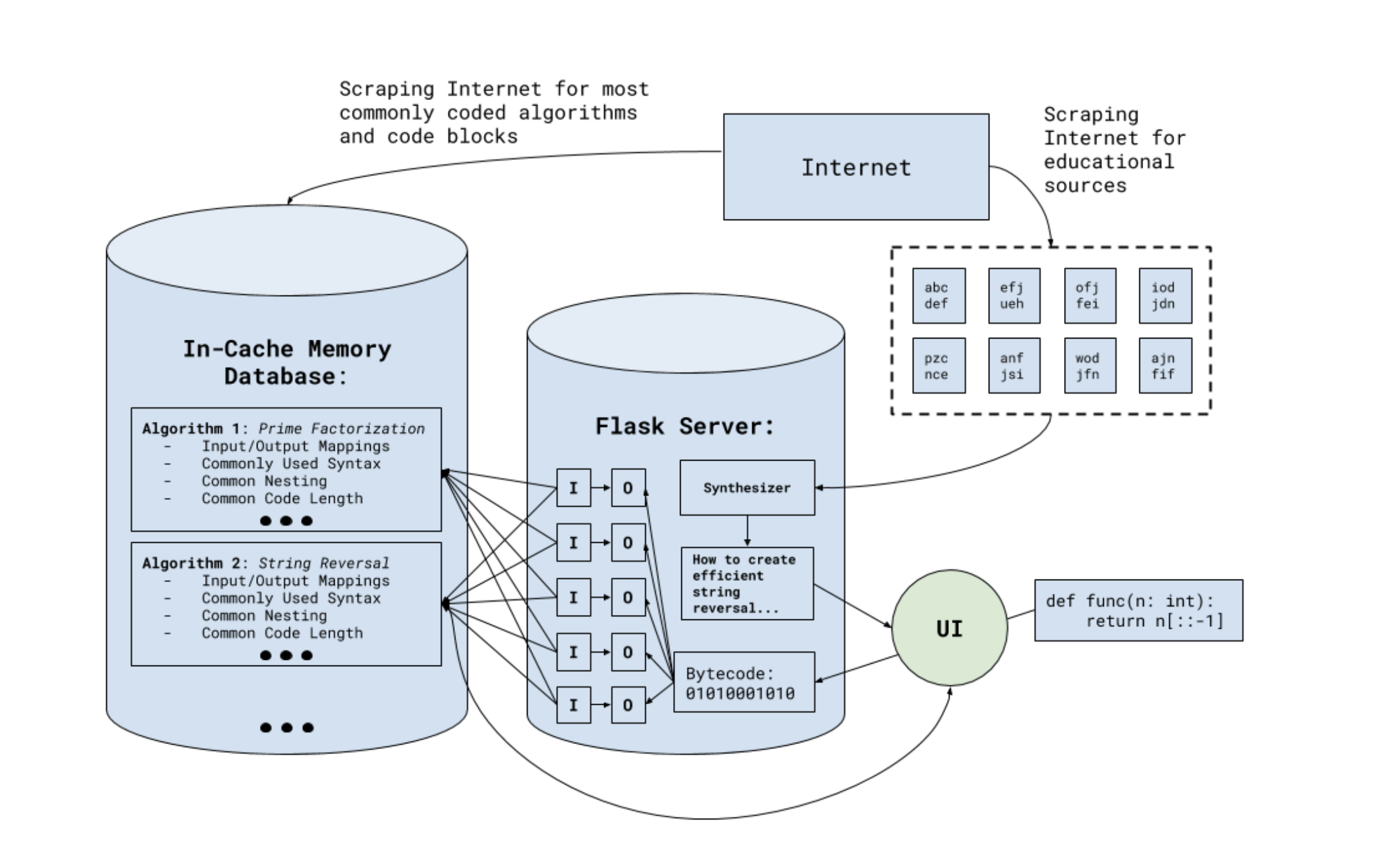
Technical Architecture of our project
-
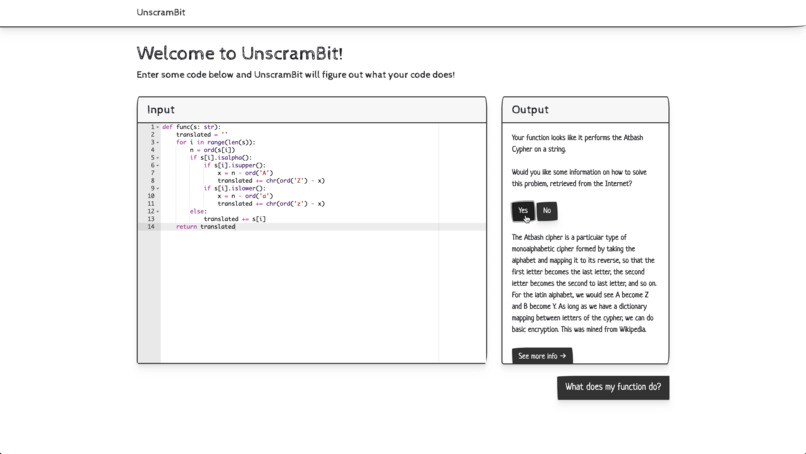
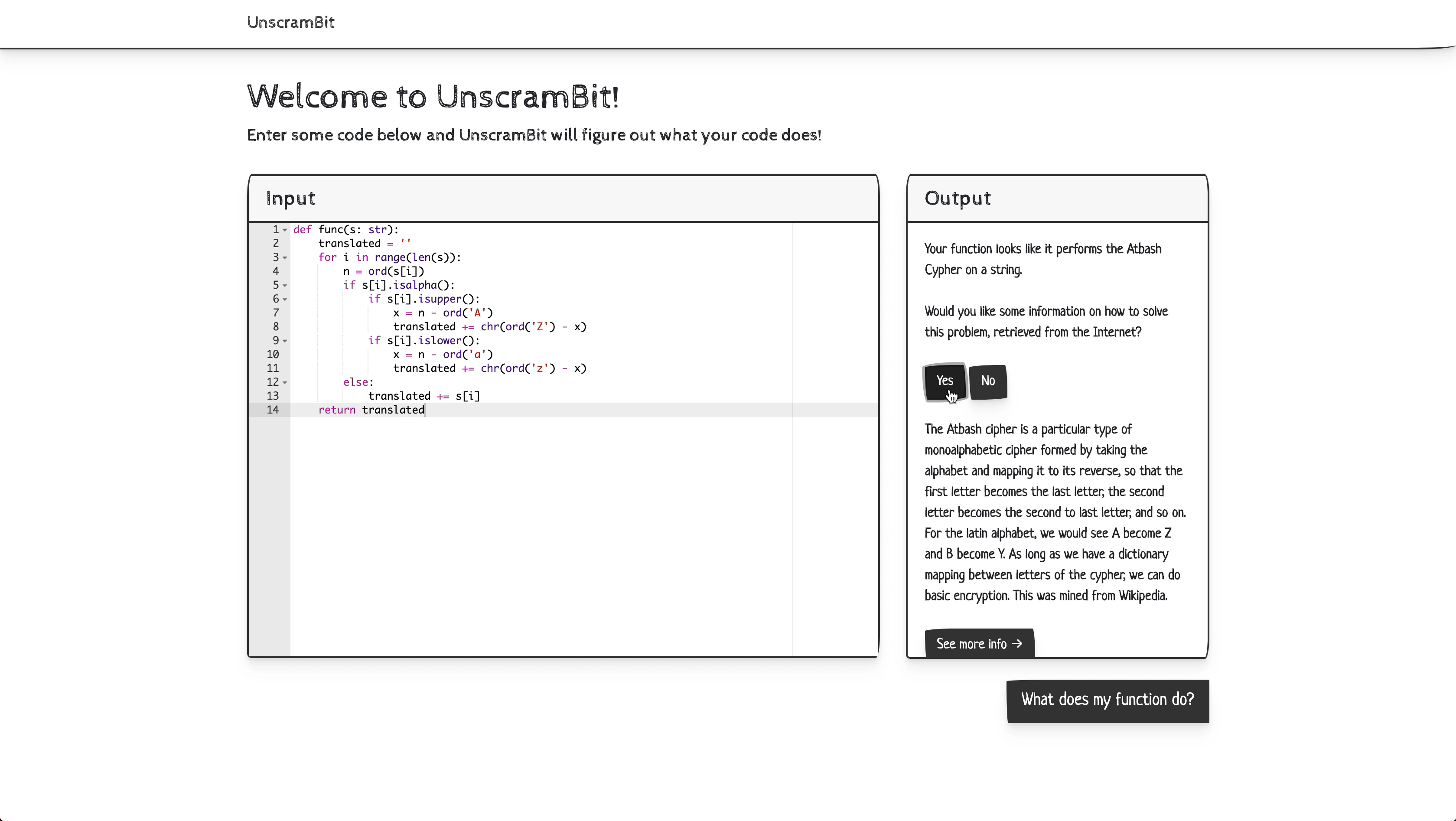
User Interface - App in action
Inspiration
As four computer science majors at UC Berkeley, we all love the challenge of creative problem-solving that coding entails. Yet we can wholeheartedly agree that one of the most dreaded aspects of programming is reading and understanding other people’s code. Even understanding the most simple of programs often requires several minutes of reading and piecing together verbose syntax and abstract variables—time that we would much rather spend in the ideation and development process. Code review—a daily experience faced by everyone from coding beginners to programming professionals—is a dull process that drains valuable time and energy.
What it does
Our framework analyzes code snippet functionality and I/O motifs to identify the purpose of each code snippet. More technically, the web-app executes a function as an input string and deciphers the patterns in its data flow. By using an intelligent matching function, we can then probabilistically infer the function’s purpose. These features therefore allow beginner coders to learn about functions that they’re not familiar with. By providing links, a description, and a basic identification of the code snippet in an auditory format, we allow for the end-user to understand and learn more about the given function.
How we built it
Front-end stack: HTML CSS JavaScript jQuery Ace.js Bootstrap
Back-end stack: Python Flask
Challenges we ran into
The greatest problems we encountered were mainly in technical development. Namely, the server-side literal evaluation for function testing was faulty at first. We spent lots of our time fixing this bug so that function given could be entered as a string. Additionally, we made an array of test cases for analyzing the function data flow. Assigning a probability for a function to be similar to the one given was definitely the most challenging aspect.
Accomplishments that we're proud of
We were able to build a crowdsourcing algorithm that finds commonly used code blocks on the Internet. It involved many moving parts, including a data flow processing engine, creating an in-cache memory database of input/output mappings, creating statistical distributions of code lengths/styles, and analyzing stylistic uses in the code. The algorithm is also extremely fast, querying tens of thousands of algorithms in a few milliseconds through a distributed system. We believe our solution can work in both industrial, professional, and educational settings, due to its extremely fast architecture and its very minimal, pedagogically-based UI.
What we learned
We learned lots about the mathematical background of probability estimation. Creating a probability inference involves not only an argument maximum but also a hard threshold for failure protection. As a team, we were also able to understand the dynamics of a business proposal and how to encapsulate an IP into a pitchable idea for public usage.
What's next for UnscramBit
We envision high school students abstracting code and managing computational complexity as they treat coding as an imaginative process, not a tedious one; we believe that our product will eradicate the elitism that experienced programmers seem to portray, simply because of their cryptic coding style. Any prime factorization algorithm is worthy of admiration!











Log in or sign up for Devpost to join the conversation.