-

File Uploading
-
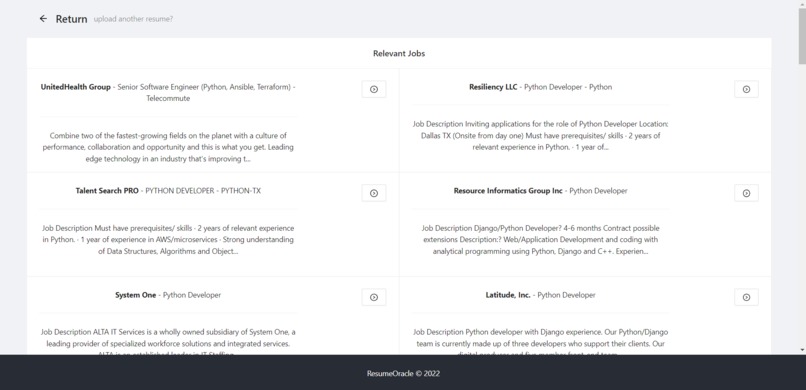
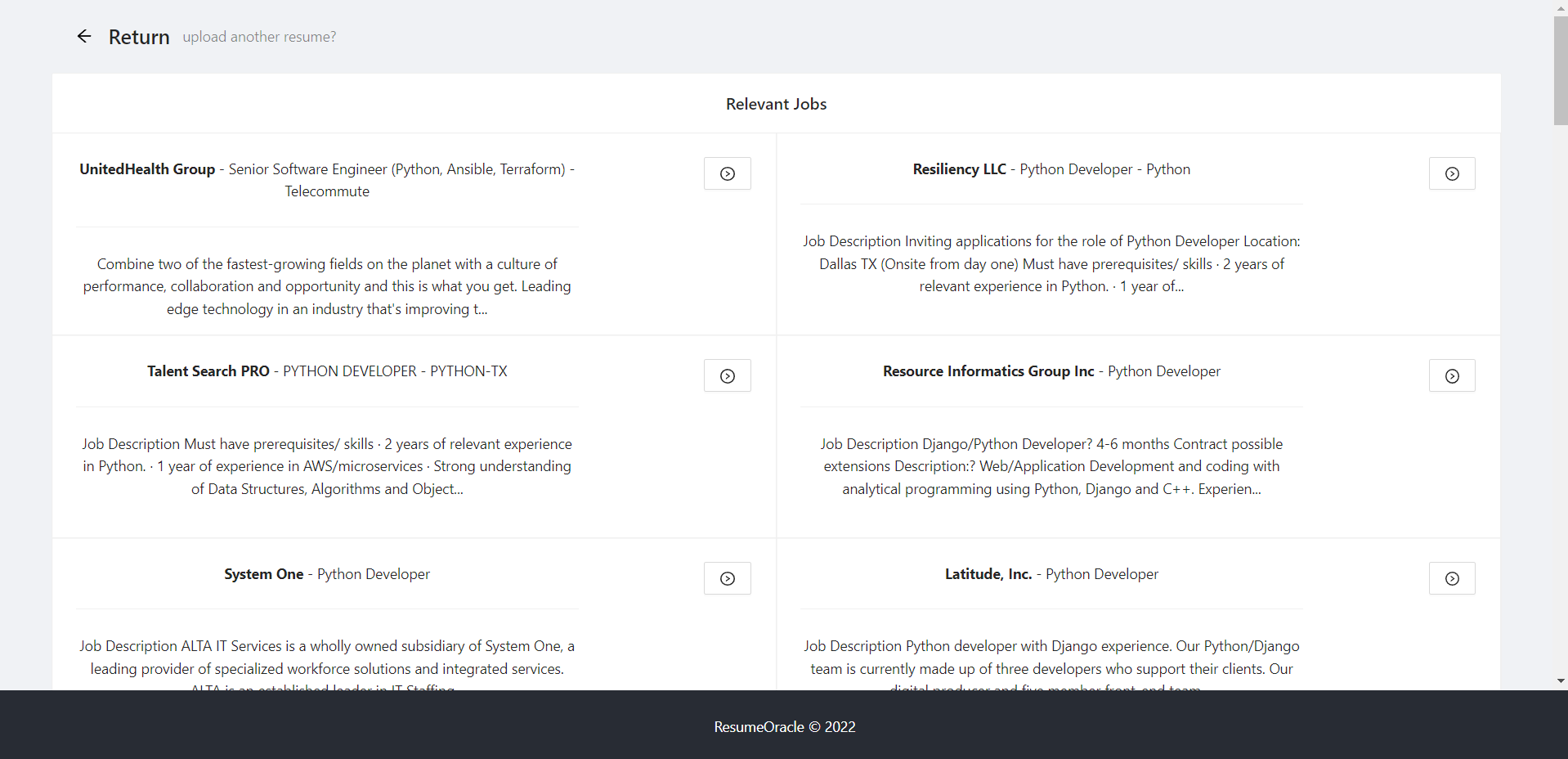
Jobs

Inspiration
My teammates and I have applied to dozens of internships this past year but have found it difficult to find internships that match our specific skills. So we wanted a fast, simple way to find internships that match the skills that we have already listed on our resume. Thus, Resume Oracle was born, allowing users to upload a resume and instantly get a list of jobs that match one's skills from Adzuna.
What it does
Resume Oracle allows users to upload a resume and instantly get a list of jobs that match one's skills from Adzuna.
How we built it
We built Resume Oracle using a couple of different moving parts.
- First, we built a text extractor in Python that can retrieve raw text from .pdf, .docx, and .doc files.
- Second we built a skills extractor that tokenizes the raw text and identifies noun-chunks using Spacy, a pretrained Natural Language Processing (NLP) Model in Python.
- Third, we extract all the skills from the resume by recording all of the noun-chunks which match the skills found in a list of resume skills we found on the internet.
- Fourth, we use the Adzuna API to retrieve jobs from Adzuna which require the skills found in the resume. Note: Adzuna is a website that helps people get jobs.
We then built a frontend and backend for this program using flask, html, CSS, React.js (JavaScript), and Python.
Challenges we ran into
We ran into several challenges.
The first challenge was parsing raw text from .pdf files. This problem is not 100% solved and I tried four different pdf parsing packages before settling on one that generally worked. For reference, we found numerous resume parsers on the internet but many of them were unable to parse pdfs and would often fail to recognize even a single line of raw text in a .pdf document.
The second challenge was tokenizing the noun-chunks without using too much memory. In order to host our project for free on Heroku, we need our project to be under 500 MB. However, many of the resume parsers already on the internet had a large memory footprint as they relied upon both Spacy (177 MB) and NLTK (335 MB), two NLP Python packages. We decided to create a memory-efficient resume parser and used just Spacy to perform some of the analysis previously done with NLTK.
Accomplishments that we're proud of
We are proud that we successfully integrated and hosted a machine learning application. It was awesome to build a product that relies upon such fascinating cutting edge technology.
We are also proud of the fact that we were able to improve upon existing resume parsers by building a smaller, more lightweight application then what currently exists out on the internet.
What we learned
We learned how to use Spacy, build a frontend website, and host our project. This was also the first collaborative project for some of our teammates and they learned how to merge conflicts on github. For some of our team members this was their first hackathon. They learned that in a hackathon it is often wise to use preexisting technologies to create new products such as what we by relying upon Spacy and checking out other resume parsers on the internet.
What's next for Resume Oracle
We are currently in talks with Mark Zuckerberg and Elon 'Doge' Musk about acquiring our product. JP Morgan has already agreed to do our IPO.


Log in or sign up for Devpost to join the conversation.