-
-

readmap.ai dashboard
-
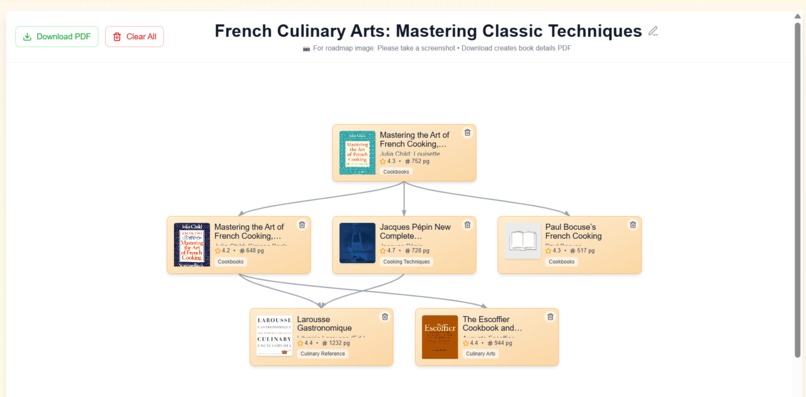
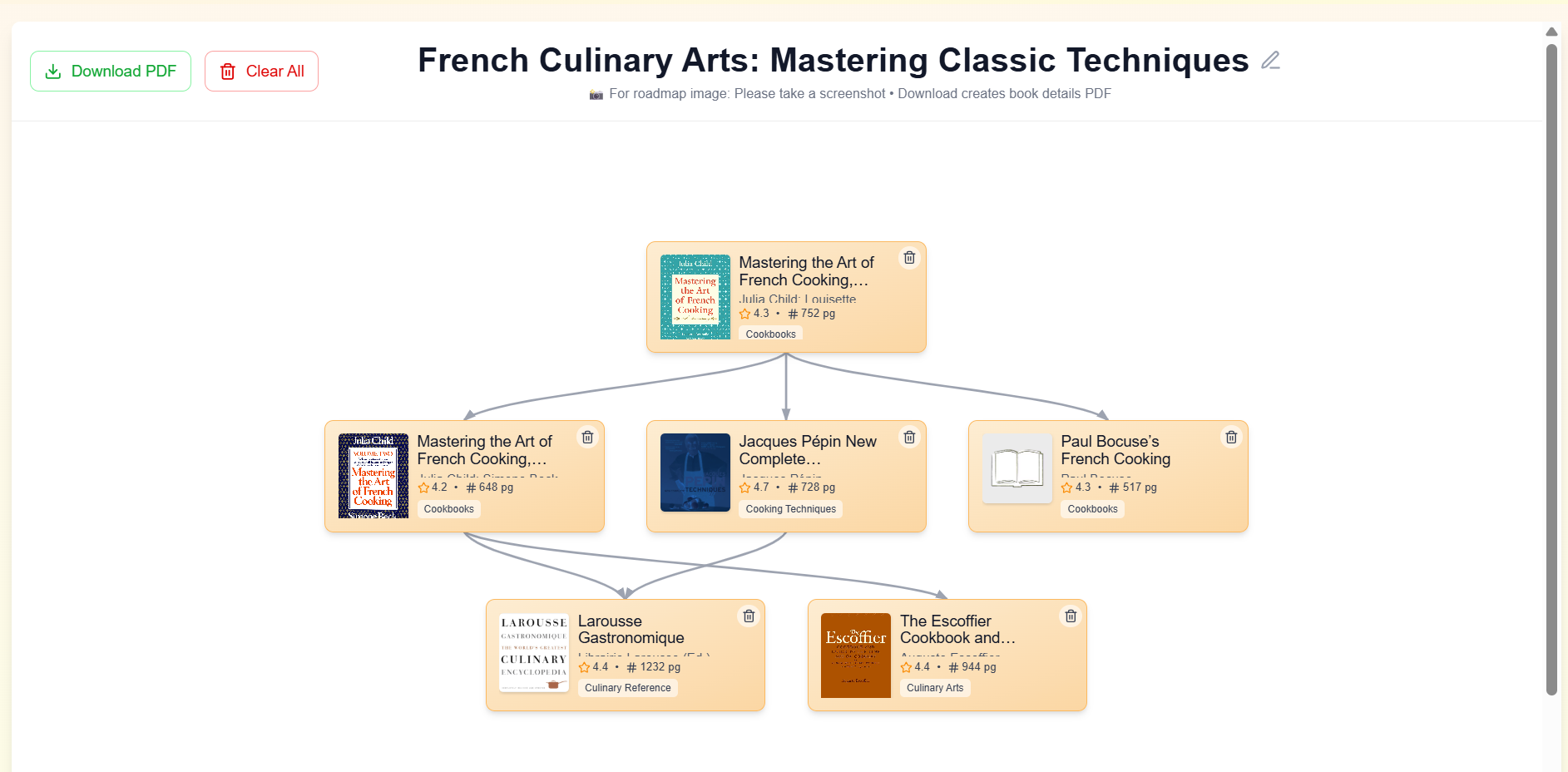
example of generated book roadmaps
-
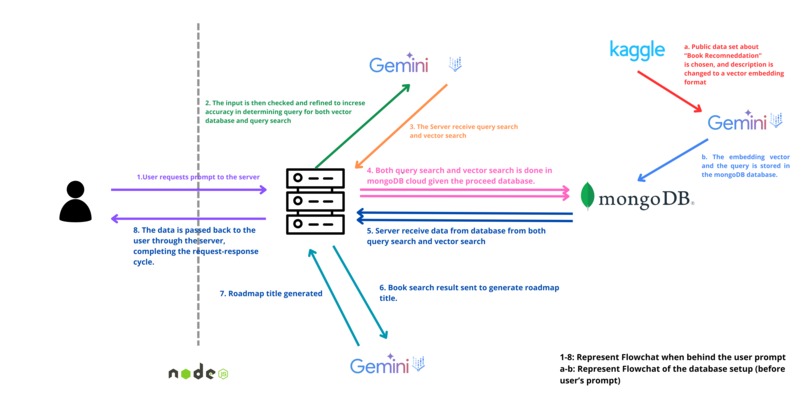
readmap.ai flowchart
-
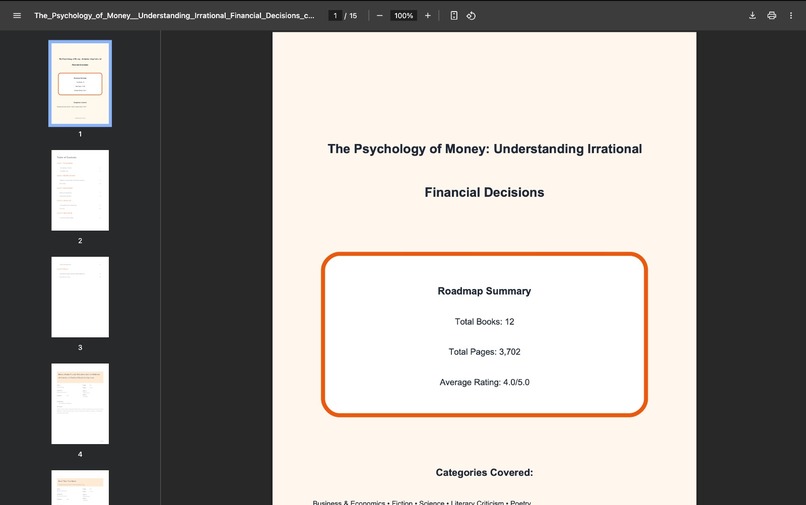
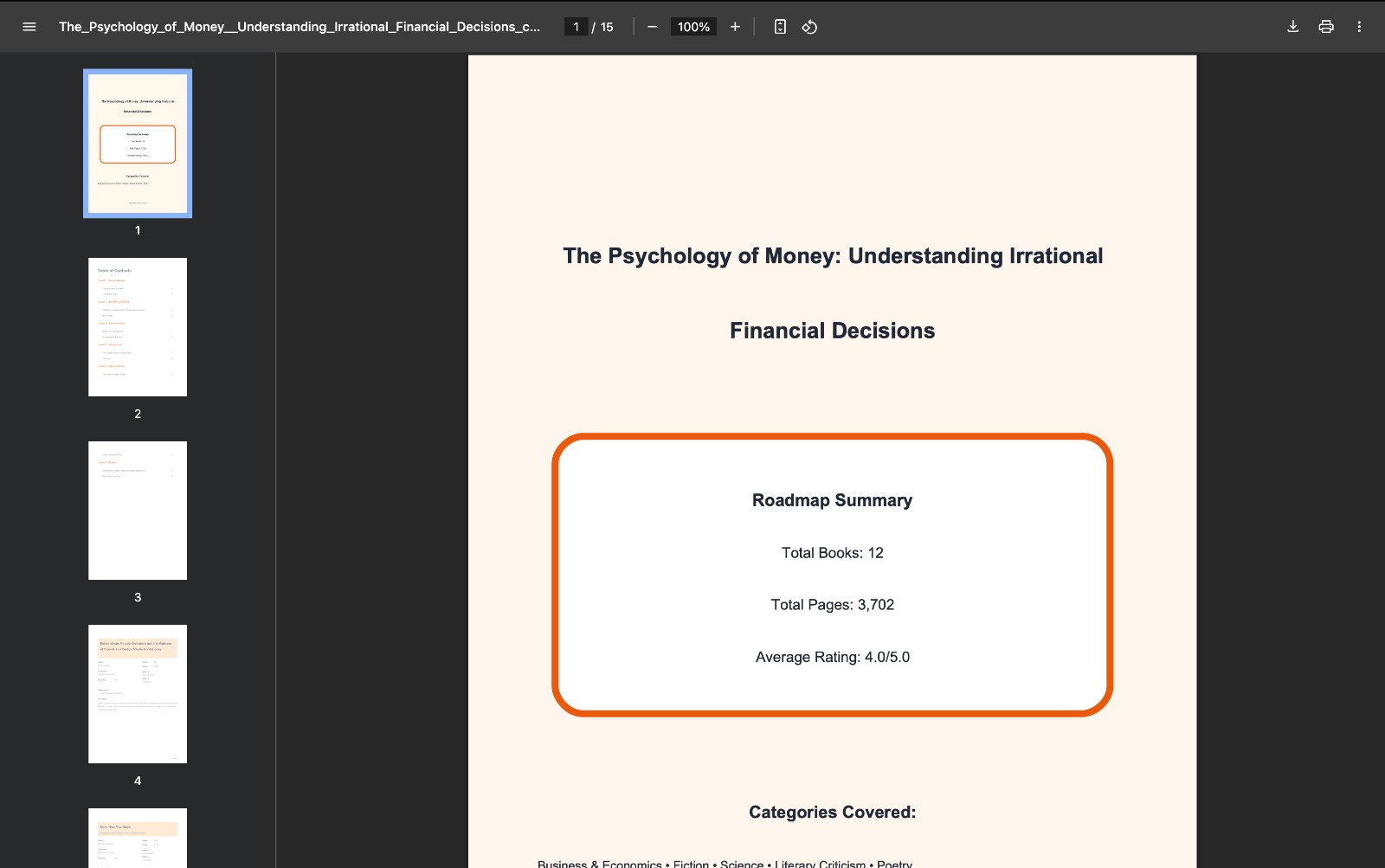
generated roadmap as pdf

Inspiration
Readmap.ai began as a team-driven response to a shared challenge we faced as students and lifelong learners: figuring out what to read and in what order when exploring a new topic. We often found ourselves lost in a sea of book lists, blog posts, and forums, unsure where to start or which source to trust. We wanted something smarter, a system that doesn't just recommend books but builds a guided, personalized learning roadmap tailored to our goals and interests. This sparked the idea of building readmap.ai, a platform that could intelligently generate personalized reading roadmaps powered by AI.
What it does
Readmap.ai takes a user’s input, whether it’s a topic, a question, or a goal, and returns a structured reading roadmap, complete with personalized book recommendations arranged in a logical learning sequence. It adapts to the user’s interests, background, and depth of inquiry, making sure every roadmap feels custom-built. The interface is intuitive and visually appealing, providing an engaging experience through:
- AI-generated roadmap logic
- Interactive chatbot-like query input
- Visually stacked book progressions
- A clean and modern UI powered by Tailwind CSS
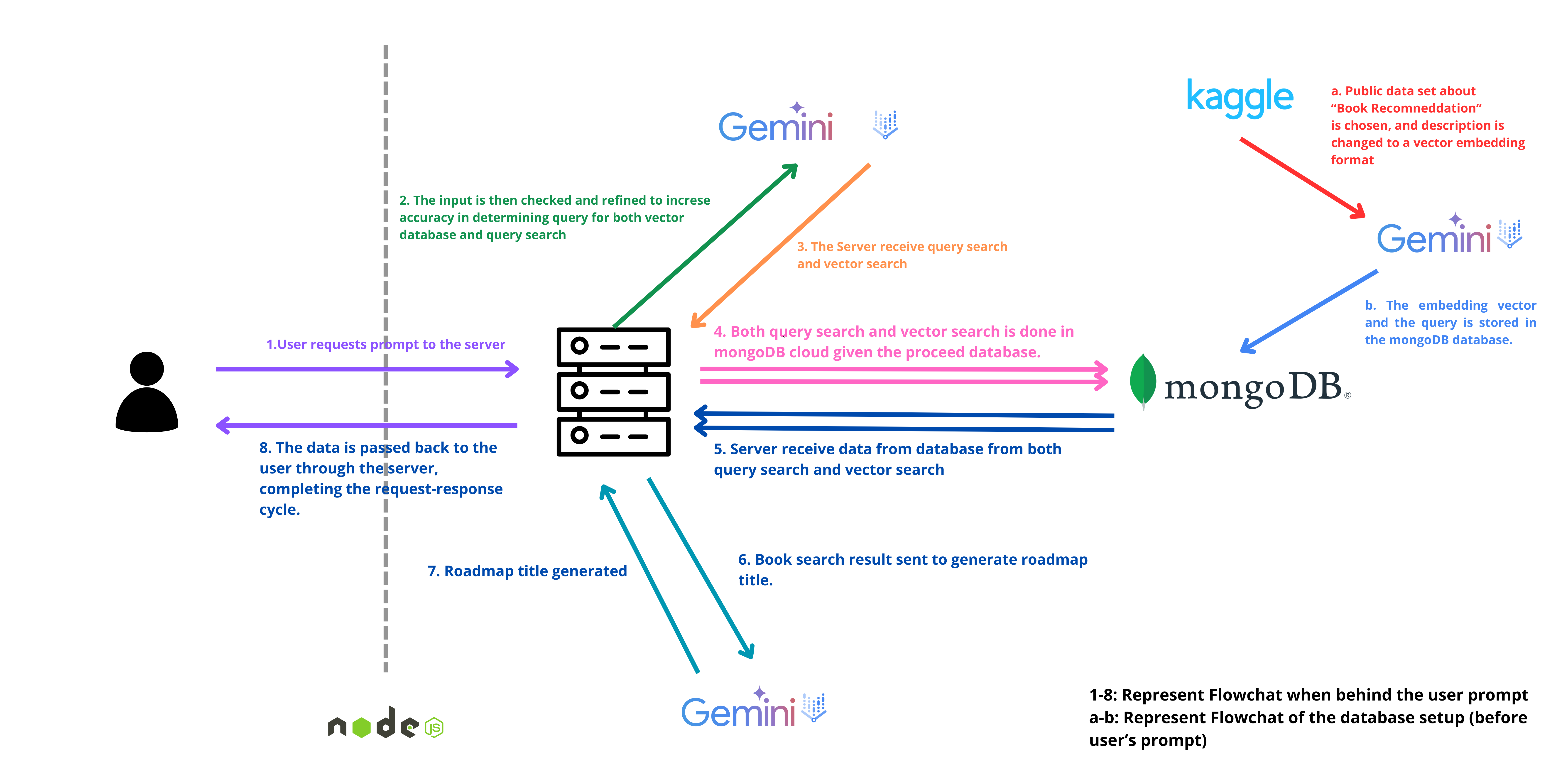
How we built it
- Frontend: Next.js 13+ using the App Router and TypeScript, styled with Tailwind CSS and ShadCN UI for modern UI components.
- Backend: Python setup scripts that initialize MongoDB Atlas and perform vectorization of books.
- AI/Embeddings: Google Cloud’s Vertex AI powers the semantic understanding of user queries and book data.
- Database: MongoDB Atlas stores and serves the book collection and vectorized embeddings.
- Deployment: Hosted on Google Cloud Run for scalability and serverless deployment. The book data is pre-processed and vectorized using embedding models, then stored in MongoDB. When a user submits a query, a similarity search retrieves the most relevant books and arranges them based on topic progression.
Challenges we ran into
- Finding a proper dataset: We had to curate and structure book data suitable for semantic search and learning progression.
- Determining a satisfiable data structure: Mapping books to knowledge levels and themes required careful schema design.
- Designing the collaboration between RAG (Retrieval-Augmented Generation) and vector query search: Merging semantic relevance with roadmap logic was tricky.
- Front-end clashes: Building a functional UI that still looked polished within a tight timeline meant constant iteration.
- Balancing visual appeal and usability: Making the drag-and-drop interactions, dropdown menus, and modals work seamlessly required cross-functional debugging.
- Integrating the AI + database + UI stack: Each layer had different expectations and tooling; bringing it all together smoothly was a technical feat.
Accomplishments that we're proud of
- Built a fully functional end-to-end product in a short time with modern frameworks and technologies
- Developed a personalized AI assistant that feels intuitive and practical
- Integrated Google Vertex AI for real semantic search, not just keyword matching
- Implemented drag-and-drop reordering, renaming, and deletion of maps — all with responsive UI feedback
- Achieved a polished UI with animations, gradients, and structured layout using Tailwind
What we learned
- How to implement semantic search using embedding models and vector databases
- The importance of design systems (like ShadCN and Tailwind) for rapid prototyping
- Data modeling for AI systems that need progression logic, not just relevance
- Real-world integration of cloud AI services, especially Vertex AI
- How to collaborate effectively in a high-pressure environment while juggling frontend/backend/AI simultaneously
What's next for Readmap.ai
We plan to take Readmap.ai to the next level by:
- Adding sign-in and authentication so users can save and sync their maps
- Building saved maps persistence using cloud storage for cross-device support
- Integrating a more dynamic AI assistant that adapts in real-time to user feedback
- Expanding the dataset to include podcasts, videos, and articles beyond books
- Adding a sharing feature so learners can collaborate and discover from one another





Log in or sign up for Devpost to join the conversation.