-
-
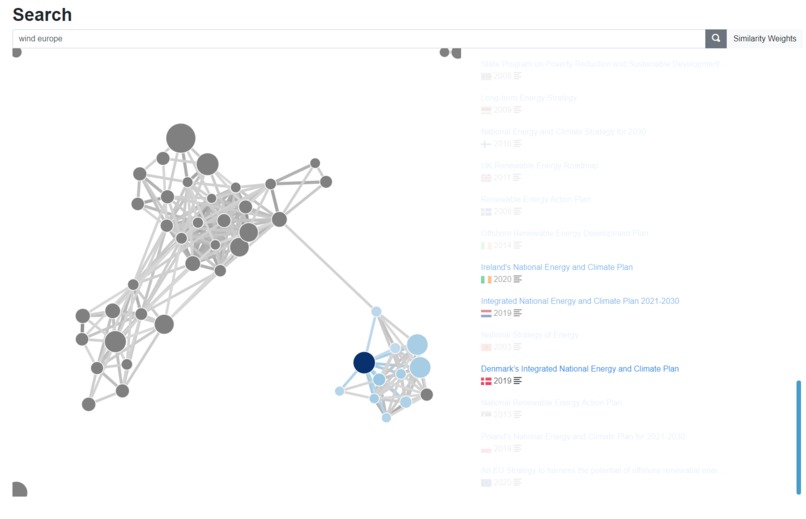
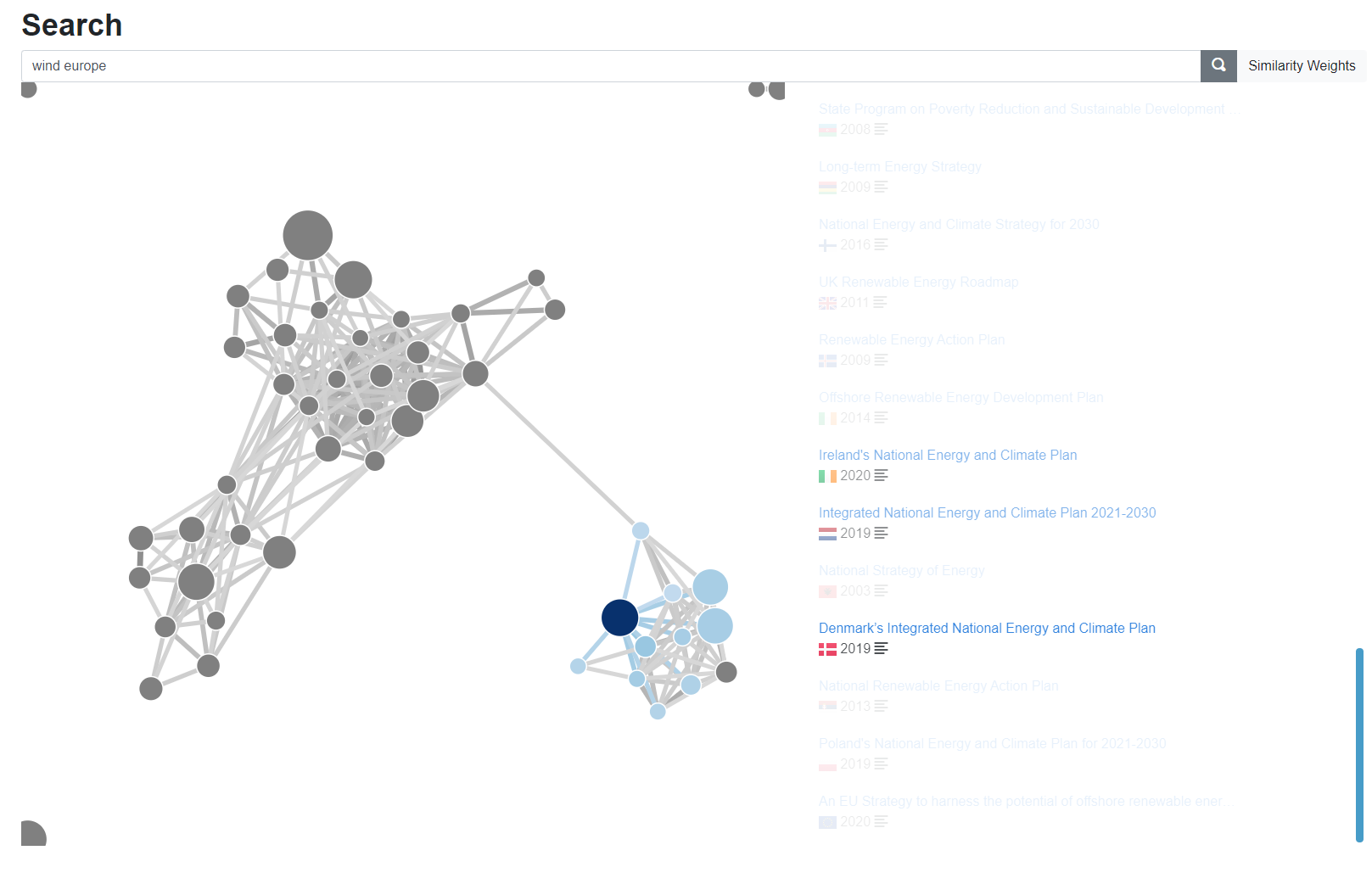
Graph view of a search result highlighting similar laws and policies for the query "wind europe"
-
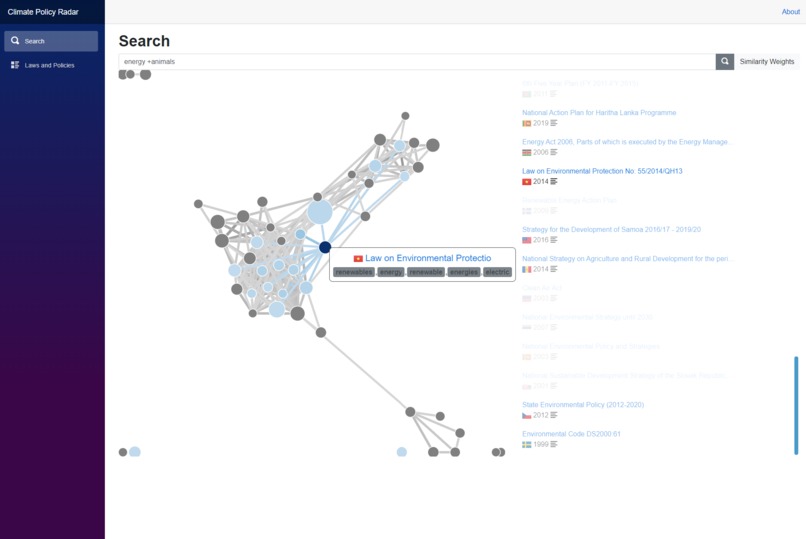
Graph view of a search result highlighting similar laws and policies.
-

Detail comparison of of two legislations showing the different similarity factors based on AI and metadata.
-
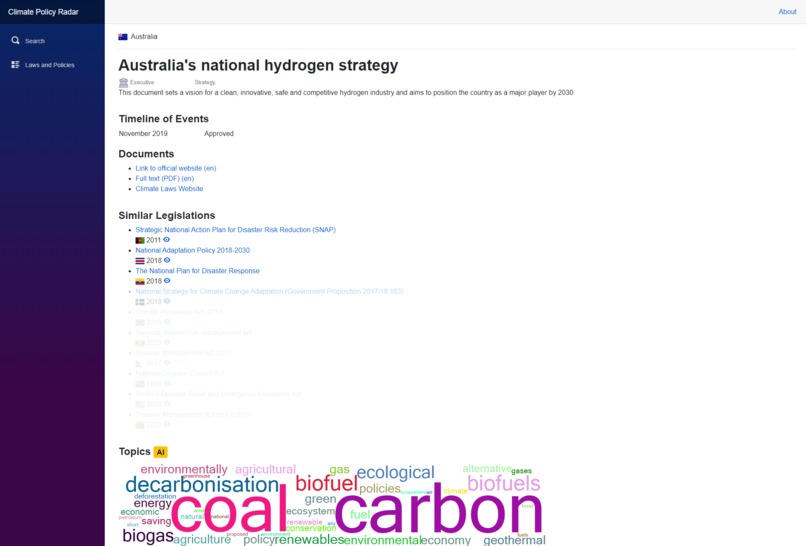
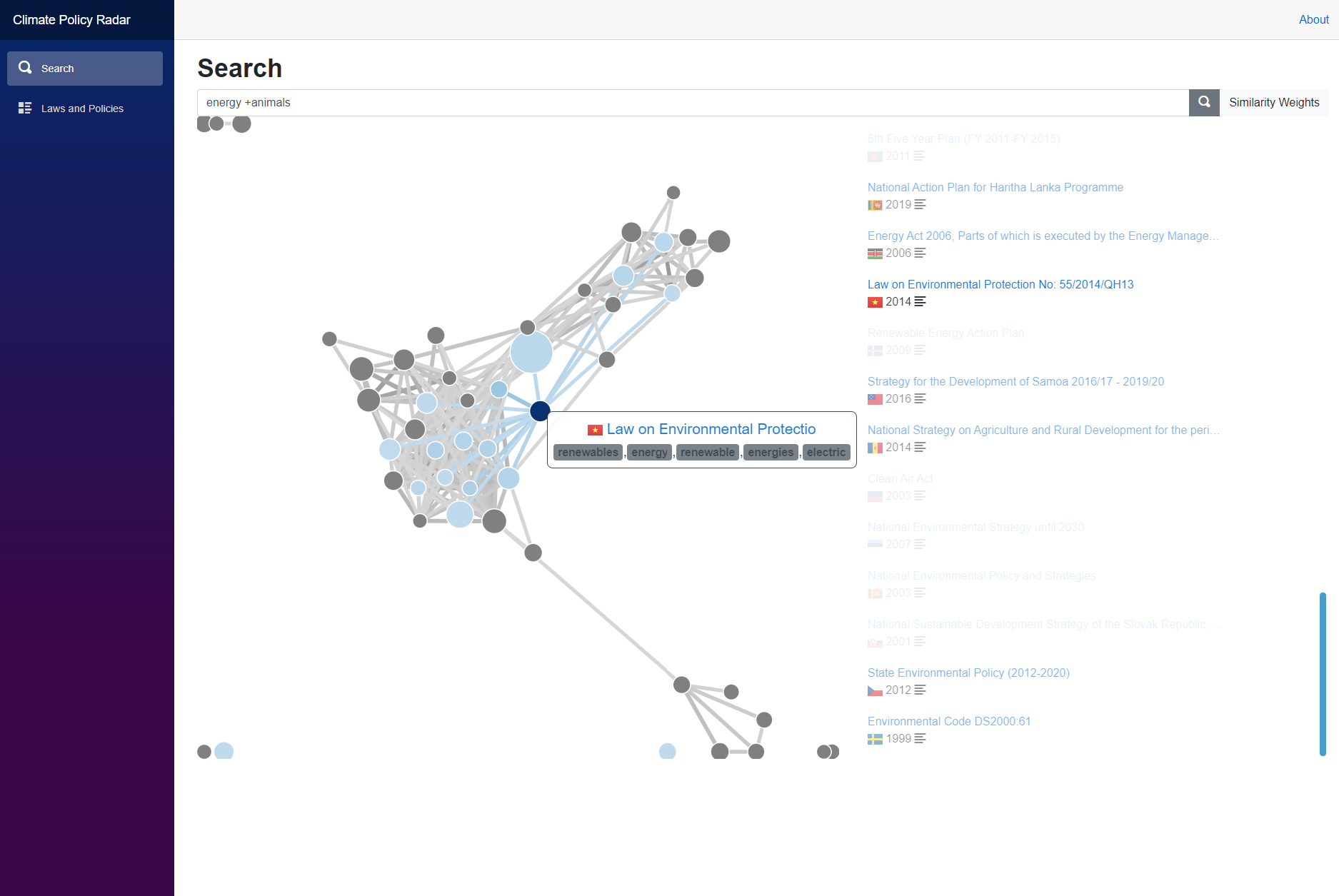
Detail page of a legislations showing similar legislations and the topics extracted with AI text analysis
-

The Purple Penguin tech and method approach at a glance
-
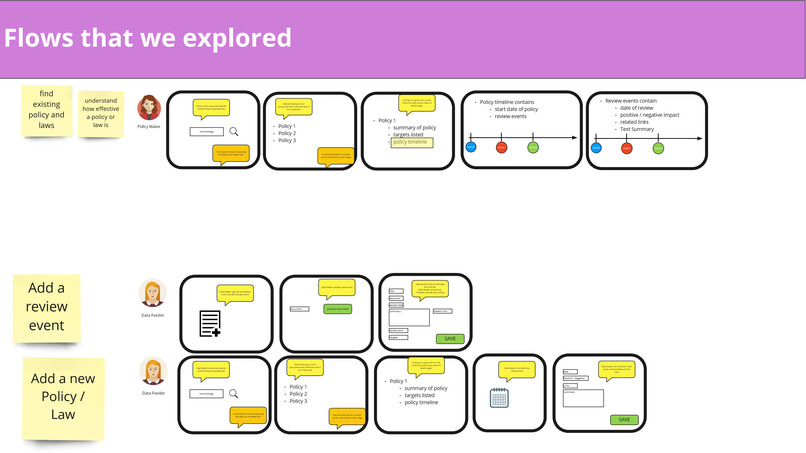
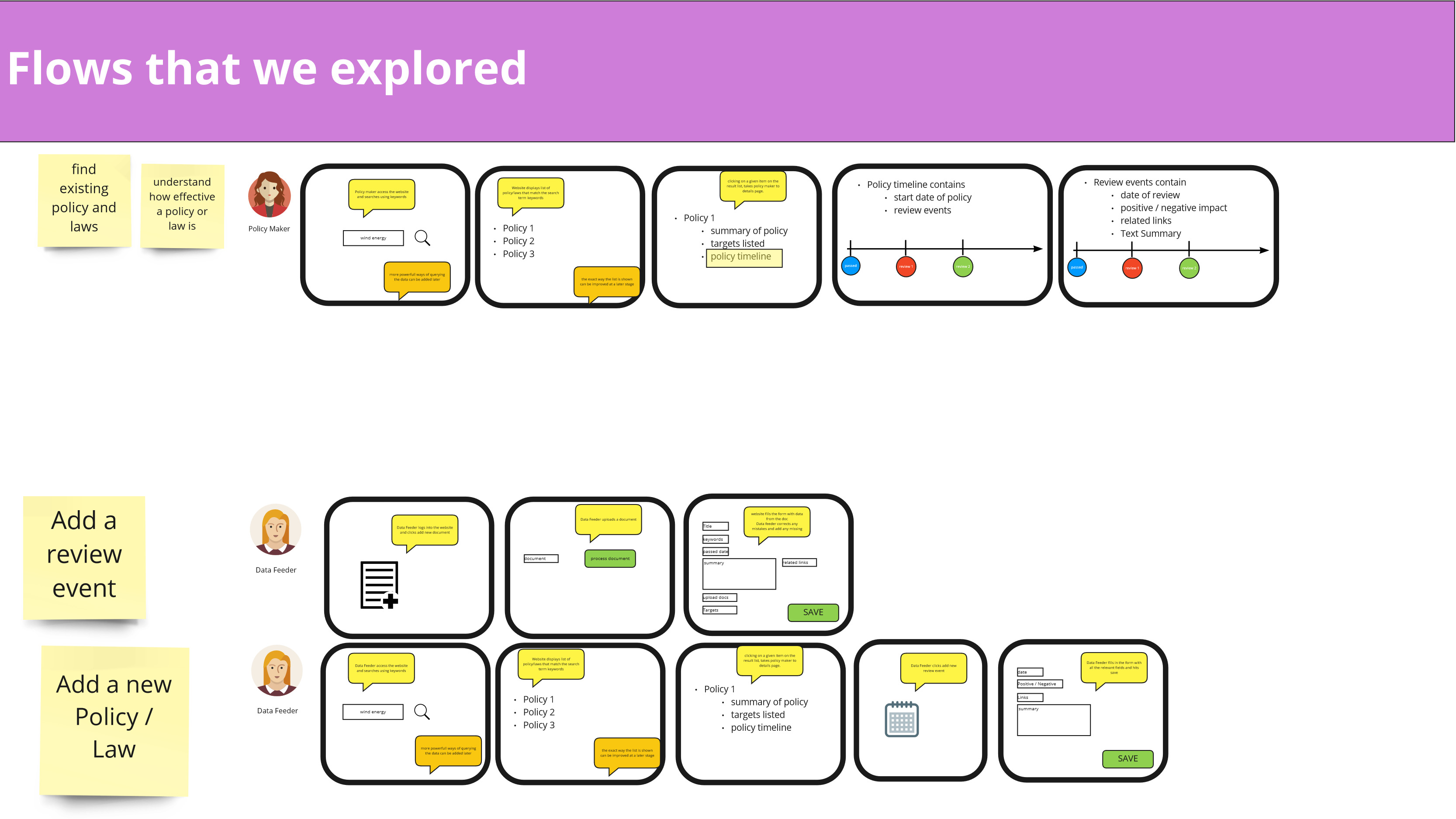
User flows we considered when designing the Data Exploration Platform
-
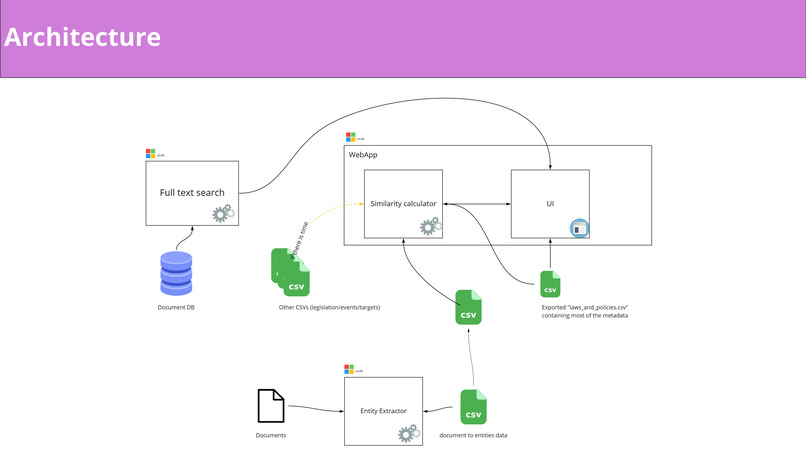
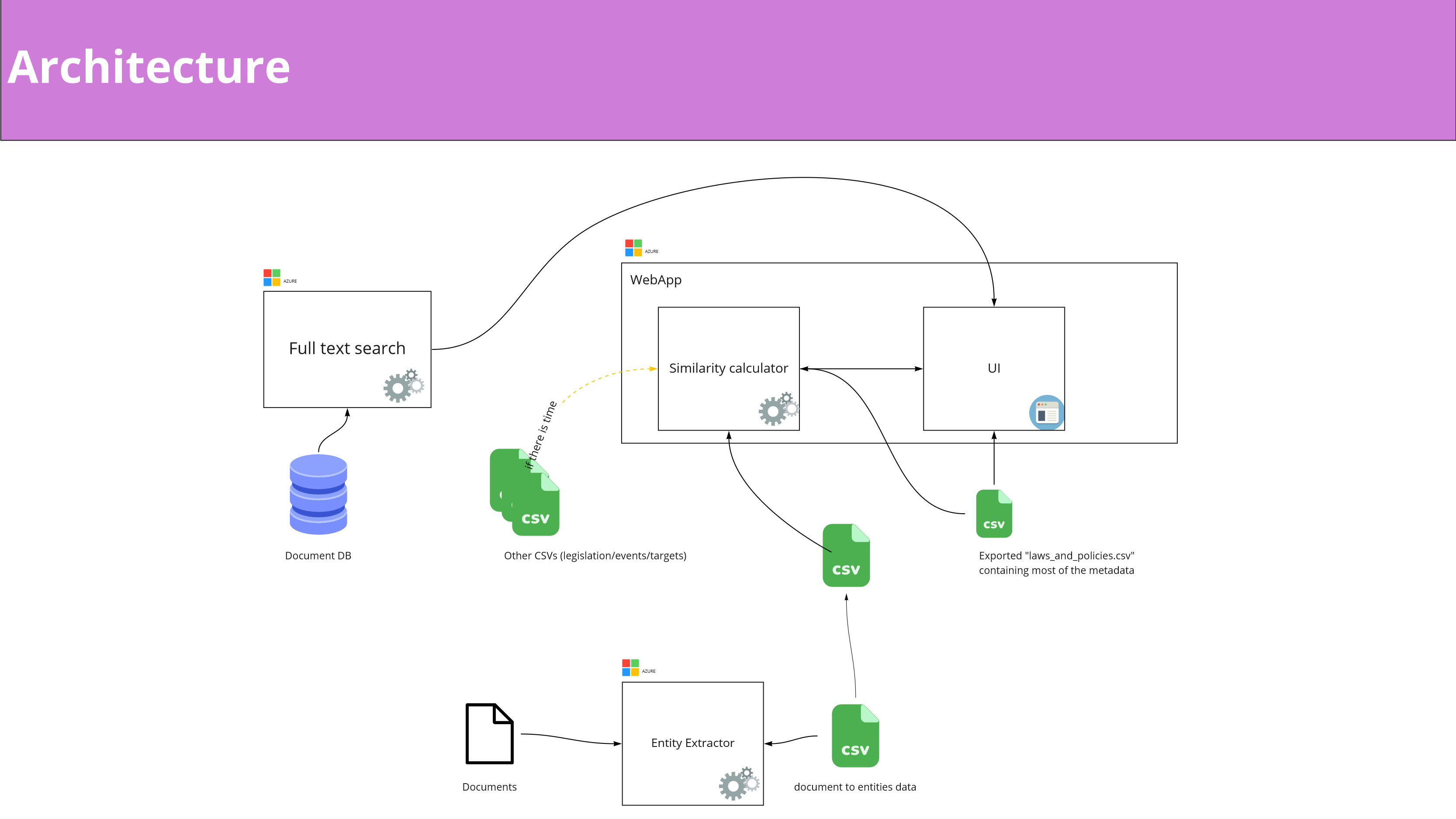
The high-level architecture of the Data Exploration Platform
-
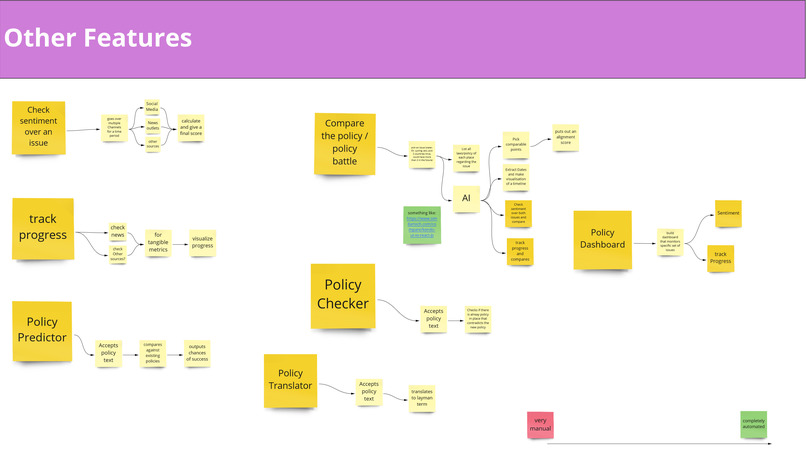
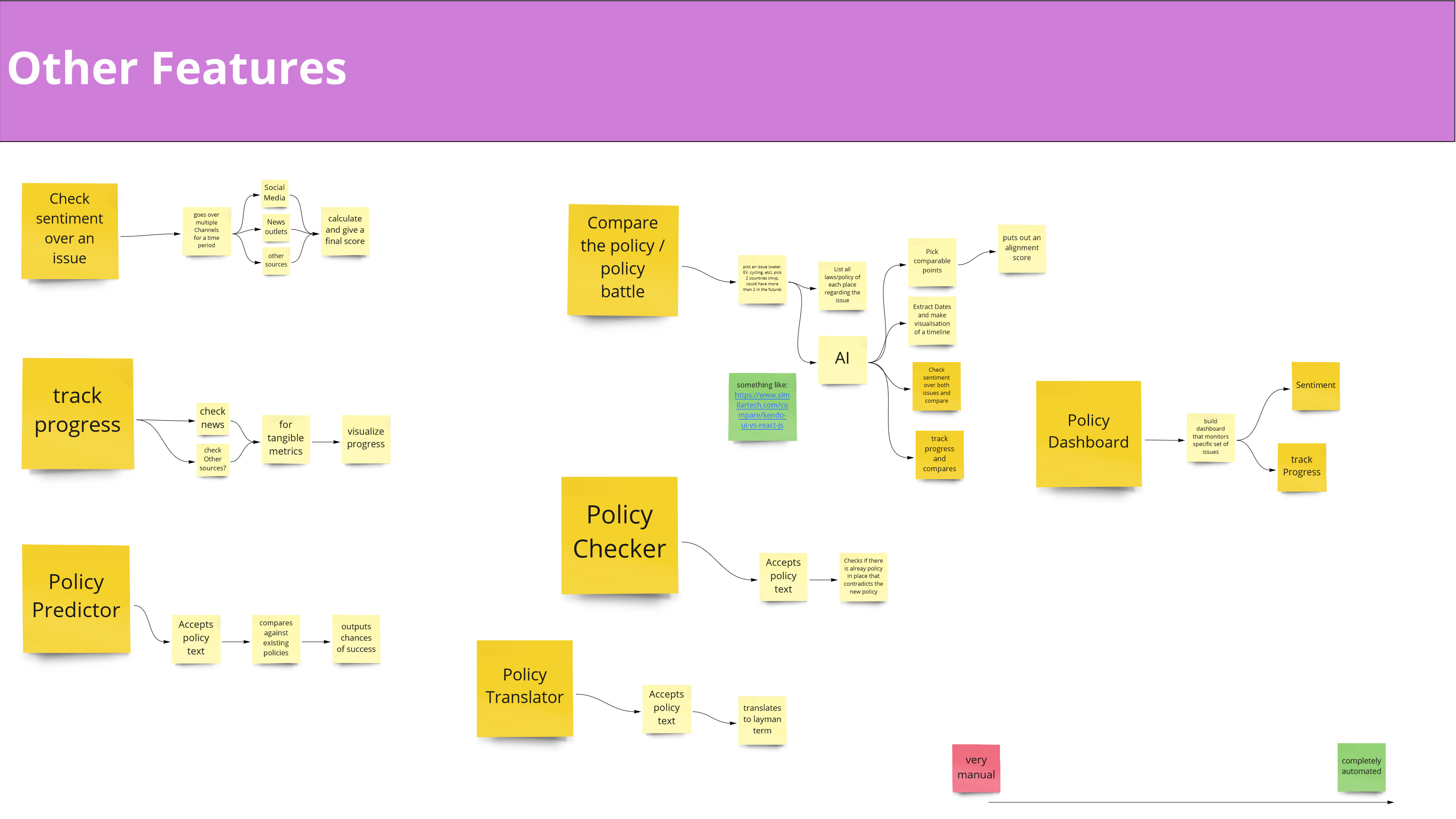
Features that can be implemented based on our technology (excerpt)



Inspiration
The world is governed by laws and policies. So, how do you make our market economy and capitalist society care more for nature? Exactly: you put in place effective laws and policies!
But what makes a law an effective law, what makes a policy an effective policy? If we know what works and what doesn't, we can potentially impact everything - from food and agriculture, to carbon emission, energy, waste, natural disasters, and so on.
What it does
Almost every country has put climate laws and policies in place - with varying effect on the environment. Hence, there must be plenty of examples out there for what works and what doesn't.
The intelligent Data Exploration Platform by Purple Penguins helps policy makers and civil servants make informed decisions about how to design their laws and policies. Using state-of-the-art topic extraction and similarity matching techniques, the platform identifies laws and policies from all over the world that are relevant to the user's search request.
The artificial intelligence behind the Data Exploration Platform automatically ranks search results by relevance and puts them in context as a visual policy tangle. This allows the user - at one glimpse - to identify the most important laws and policies for their task, similar policies that may be worth consideration, and outliers that may provide counterexamples or new perspectives.

Additional functionalities include quick-and-easy information access via tooltips and screen design, marketplace-like features based on similarity matching (aka "people looking at this policy were also interested in that law"), and smart A-B-comparison by clicking on tangle connections ("policies A and B have X in common but differ in Y").

If you want to know exactly how the Data Exploration Platform works, check out our GitHub code repository, especially the implementation of similarity matching mechanism.
How we built it
We set out playing around with the current database of laws and policies that was built up manually over the past few years, looking at what works and what pain points needed to be solved. This helped us narrow down our focus on what would leverage the greatest benefit.
From there on, we looked at who potential users of our solution may be and defined user flows. This helped us create a solution concept that would bring the greatest benefit to all of them.
We then narrowed down our scope for the hackathon to one central user flow and defined a solution architecture that would allow us to parallelize our work and create a modular solution that could easily be modified and extended in an efficient and sustainable way.

By Tuesday afternoon, we were ready to start implementing our tool using the .NET stack and Azure cognitive services. The core elements of the Data Exploration Platform are our similarity matching services; you can check out their final code here on GitHub.
We chose an agile implementation style with rapid adaptation cycles, frequent tech reviews, intra-day standup meetings, and continuous backlog refinement. Whilst our different backgrounds helped bring in an umbrella of useful skills, our joint understanding of collaboration allowed us to proceed quickly and bring the project forward.
How it can be developed further
Our hackathon submission of the Data Exploration Platform is already functional for key requirements like law and policy search, metadata enrichment and feature extraction, relevance determination, and tangle representation. Cleary, there are always ways to further tweak the performance and resolve the odd bug that may occur.
Furthermore, we see a plethora of ways to add functionality that increases the Data Exploration Platform's usefulness beyond the scope of the hackathon. One central aspect will be to implement a smart automated law and policy ingest to quickly and effortlessly expand the available amount of law and policy data in a curated manner. Second, we want to use real-world social, economic and environmental data to correlate against implemented laws and policies to infer their effective impact.
Beyond that, there are more examples of functionality we can foresee to add further value to the Data Exploration Platform, digging deeper into the used technology:
- law and policy sentiment checker: score the public opinion about laws and policies
- law and policy translator: translates/paraphrases laws and policies for the general (layman) public
- law and policy dashboard: monitors a specific set of issues
- law and policy checker: checks for contradicting or redundant laws/policies
- law and policy tracker: visualize progress in tangible metrics
- law and policy predictor: determine chances of success
- law and policy battle: match the effect of two given laws/policies
Challenges we ran into
- Sliders and dialogs seem to be a tough combination to crack.
- Different languages present in all the provided documents. Lots of room for improvement was left open.
- Multiple people and line ending in files
- Working with a large body of documents that we did not really have knowledge about their content. Thus reasoning about search and similarity results is hard.
Accomplishments that we're proud of
- Good teamwork and laser focus, once we established a clear target for our project
- Quite functional and good looking piece of software given the timeline
What we learned
Phew, there's so much we learned, starting from technology, to team spirit, to surviving hours without coffee ... but most importantly, we didn't know each other beforehand yet grew together to become a great team!
What's next for Purple Penguins
We'll need to go back to our regular jobs, yet won't forget what still needs to be done. There's enough left to do for some after-work hacking - and who knows, maybe we'll get the chance to continue our work on the climate law and policy Data Exploration Platform ...!











Log in or sign up for Devpost to join the conversation.