

Inspiration
With the rise of AI, a new kind of database has emerged that allows developers to fully leverage AI models, called a vector database.
While there are vector database options available in Web2, there aren't any in Web3 yet. In Web3, applications are decentralized and accessed by end users, unlike non-Web3 apps that rely on centralized servers.
As a result, a vector database for Web3 needs to be designed differently.
What it does
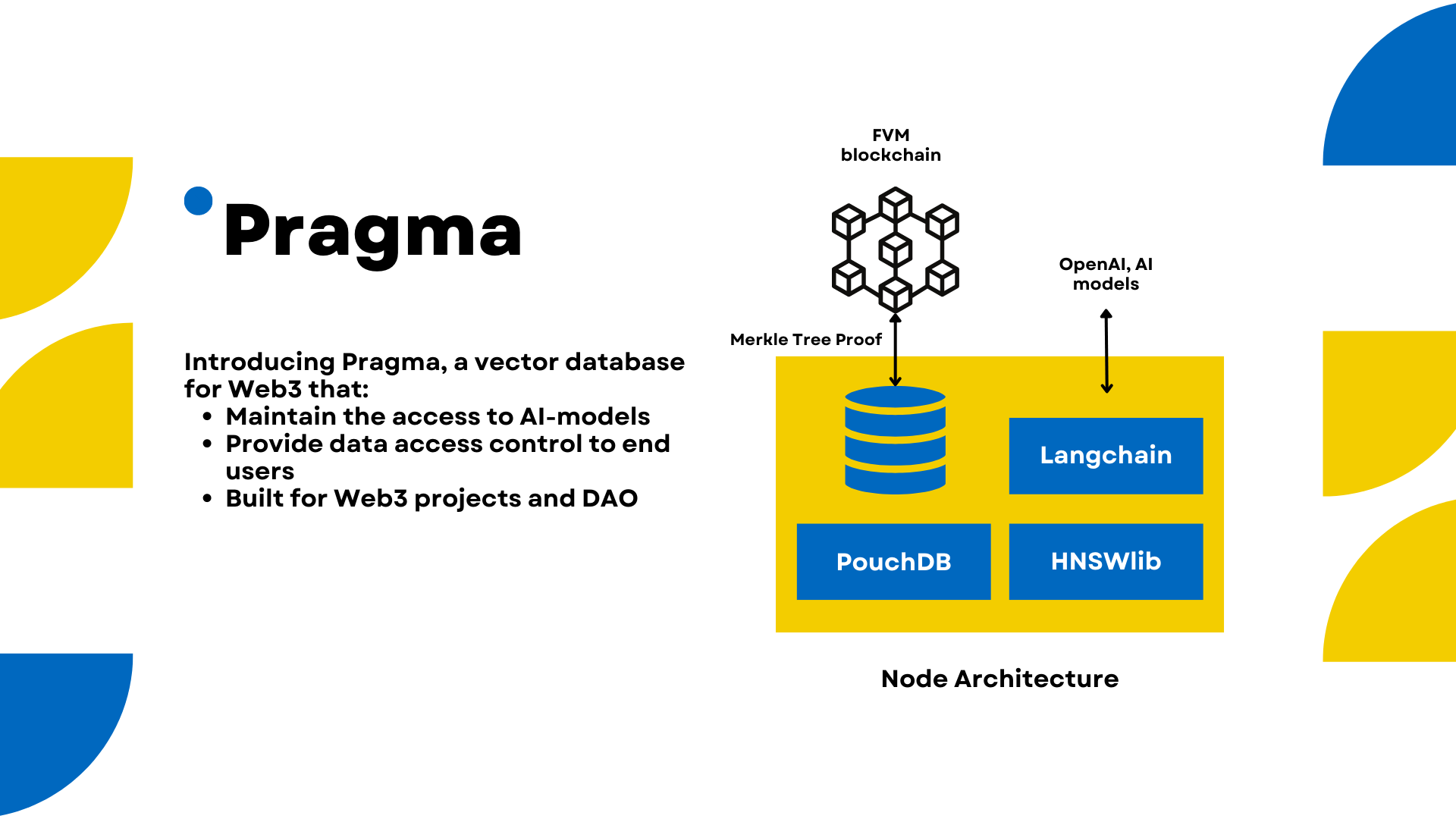
Pragma is a decentralized vector database built on FVM, employing Merkle tree proof to synchronize off-chain vector data with the state on-chain. It allows the leveraging of AI models to generate knowledge and facts, serving the needs of your community, for example, in the video demo, we show how to upload the chat history from the Telegram Web3 project group chat. We can then ask questions based on the conversation that has already been discussed.
How we built it
This hackathon project consists of three modules:
Indexer node - the main module of the project that uses JavaScript PouchDB to store the data, HSNWlib for vector indexing, and the Langchain framework to interact with OpenAI and parse documents.
UI - The UI is built with Next.js, providing the interface for users to create collections and upload entries. Users are required to connect with a Web3 wallet and sign messages when interacting with indexer nodes. Users do not need to pay any gas fees as the indexer will subsidize them.
Smart Contract - The smart contract on FVM's hyperspace testnet stores the collection's name and its metadata, including the Merkle Tree root hash. However, individual entries are stored on an off-chain indexer node
In the long run, we will provide an SDK that allows developers to point to a specific URL, which serves as an endpoint wrapping around all vector data in the collection.
During the hackathon, we're provide 3 pre-defined query operations for experimentation: Summarizing the entire collection, asking questions, and performing basic similarity searches.
Challenges we ran into
In the beginning, we had big plans - setting up Lotus nodes, making storage deals, and envisioning multiple indexer nodes. Later, we decided to simplify and focus on explaining our core idea instead, ensuring it is straightforward and reliable.
Accomplishments that we're proud of
Before developing this, we explored several vector database solutions in the market and concluded that developing a vector database is not about creating an entirely new database, but rather decomposing existing components available in the market. By the concept, we orchestrate PouchDB, HSNWlib, and Langchain to create a vector database solution for Web3.
What's next for Pragma
There is still a long way to go before it is production-ready, I think we need:
A decentralized network - Llikely to be a threshold network allowing trusted parties to help protect data from the users
End-user level access control - Unlike non-Web3 that the main consumption point is at a centralized server, the Web3 model would have a access control that allowing end users can encrypt and decrypt the data with their own keys
SDK - The SDK allows for the development of AI applications for Web3 and DAO, including chatbots for Web3 communities.


Log in or sign up for Devpost to join the conversation.