-
-
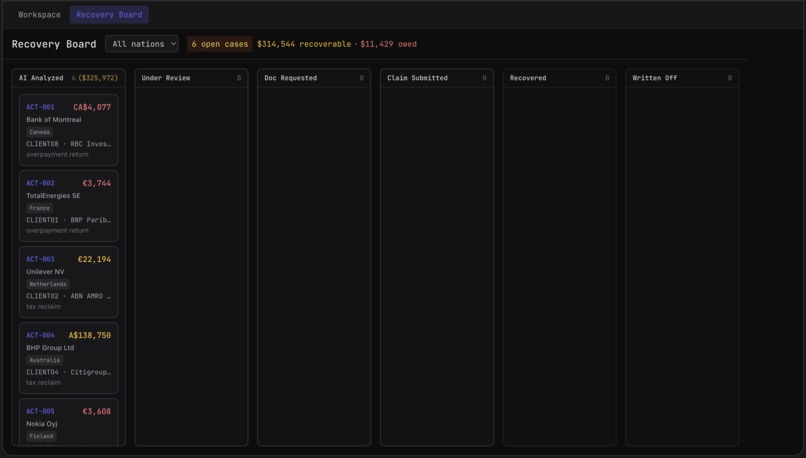
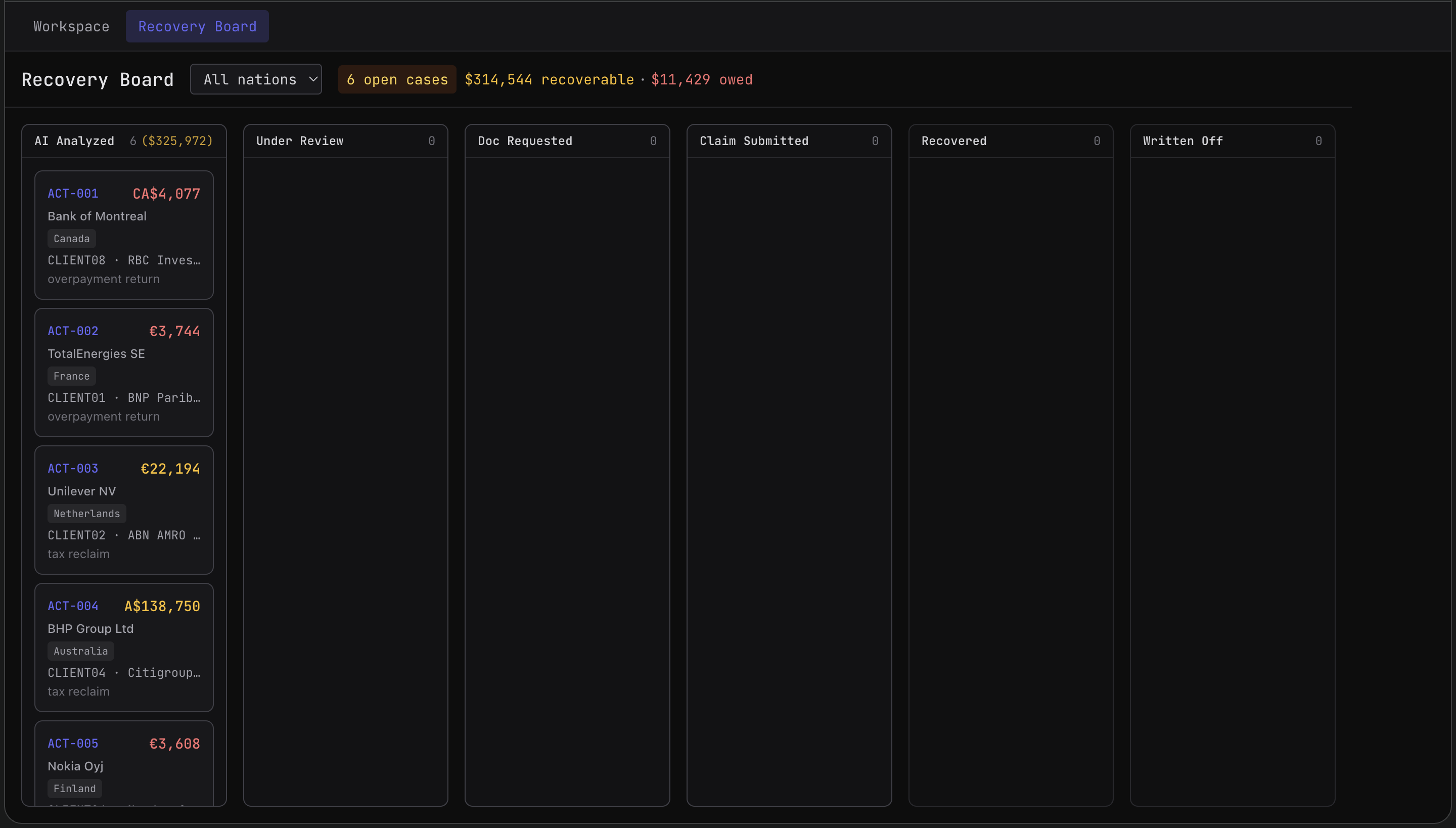
Kanban board meant for team to keep track of the events with errors needing handling
-
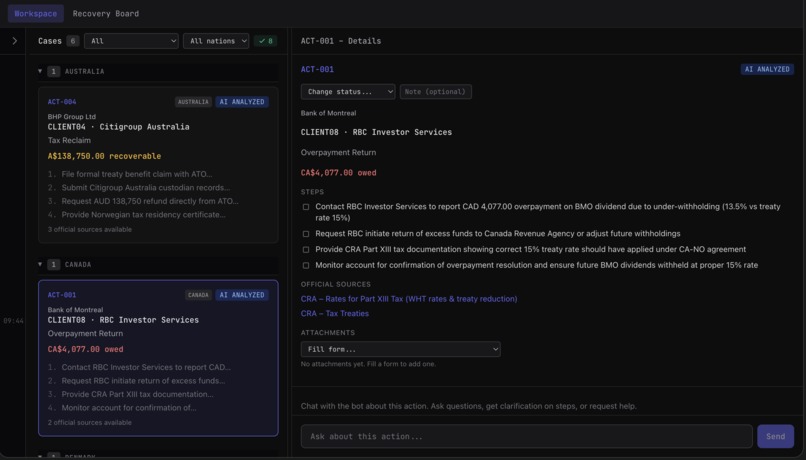
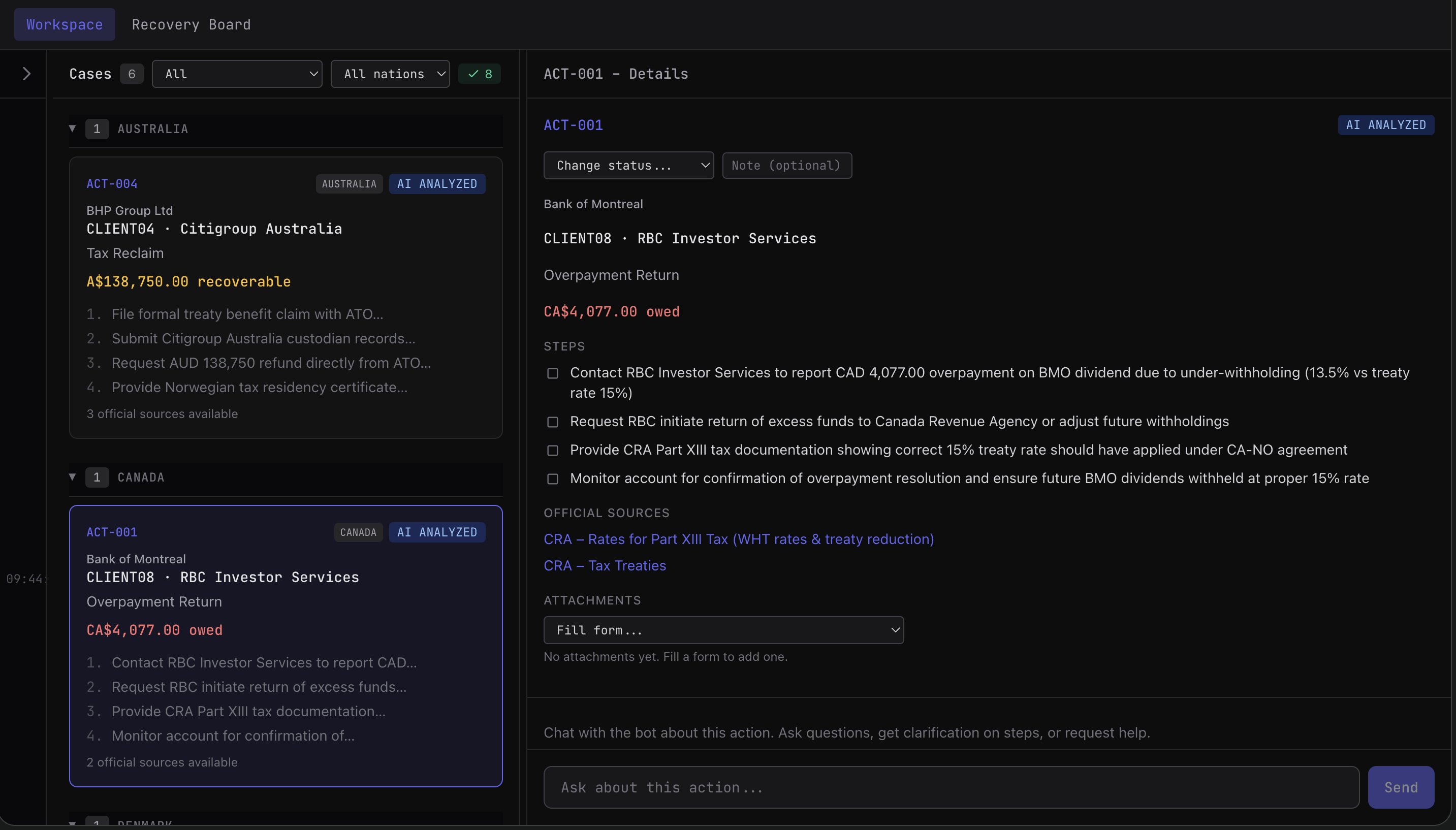
A review dashboard where users can see incoming errors, and the number of valid events
Inspiration
During an internship I observed how dividend reconciliations are handled - custodian statements are manually compared, one by one, discrepancies flagged... days were going by on spreadsheets and tax treaty lookups for errors that should be automatically detectable - that stuck with me. When HackEurope came around, I built what should have existed then.
What it does
PayScope is Grammarly for dividend payments—it catches errors banks make and shows you how to fix them. Just like Grammarly highlights grammar mistakes and suggests corrections, PayScope monitors payments from custodians, flags discrepancies (wrong tax withholding, missing amounts, calculation errors), and auto-generates the recovery paperwork with official government citations. The system handles everything from reading custodian statements to filling W-8BEN tax forms, making reconciliation seamless and trackable for operations teams at asset managers.
How we built it
The project consists of two modules, a frontend and the backend with agentic and tooling logic.
Frontend: Case Management Interface
The goal of the interface is to show cases that needs attention from human interaction and celebrate the once that don't. We also have a team Kanban board where they can coordinate who is following up on what case and in what stage it is in the reconsolidating process.
Backend: Reconciliation Engine & AI Agent
Data comes in either in JSON or PDF format, if it is a PDF we parse it to JSON.
Reconciliation Pipeline: Compares expected payments:
(holdings × dividend rates × treaty calculations)
against received payments (custodian statements).
Classifies discrepancies:
TAX_ERROR, MISSING_PAYMENT, AMOUNT_MISMATCH, OVERPAYMENT.
AI Analysis Layer:
Claude Sonnet 4 performs multi-step reasoning:
- Verify holding, dividend rate, payment date
- Cross-reference tax treaties (source country, client residency, applicable rate)
- Identify root cause (wrong rate applied, treaty not recognized, calculation error)
- Generate recovery steps citing exact treaty articles
- Link official government documentation
Outputs are structured, not free-form: ´´´ python{ "verification_steps": [...], "root_cause": "...", "action_steps": [...], "official_sources": [...], "recoverable_amount": 138750, "timeline": "15-30 days" } ´´´ Form Filling Service: Auto-generates tax forms by:
Loading client profile (name, address, tax ID, residency) Loading case context (custodian, security, treaty) Merging into form field mappings Populating PDF template Attaching to case
Caching: All Claude responses cached by request hash for consistent demo behavior and zero API costs on repeated runs. Stack: FastAPI (async), Pydantic (validation), SQLite (cases/attachments/history), uv (dependency management).
Challenges we ran into
AI consistency: Getting Claude to generate reliable, structured outputs across diverse discrepancy types was hard. Early iterations hallucinated treaty rates or invented recovery processes. Solution: Prompt orchestration—different specialized prompts for analysis, and associate links with treaties relevant for our test cases for example Norwegian - Canadian trade treaties. Each prompt includes domain examples and strict output format requirements.
Form pre-filling with mocked data: Mapping client profiles to W-8BEN fields sounds simple but gets complex fast. Client types (individuals, pension funds, corporations) need different data. Treaties have special conditions. Form field coordinates vary by PDF version. Due to time constraints this functionality is still somewhat "wonky" for certain forms.
Accomplishments that we're proud of
We built an AI agent that doesn't just detect financial errors—it generates complete recovery strategies with cited government sources. The official source citations (ATO, Treasury departments, Skatteetaten) separate this from generic AI tools: every recommendation links directly to authoritative tax guidance.
What we're most proud of is reliably identifying scenarios where no errors exist. We validated this with metamorphic testing, which fuels efficiency gains at back-office functions—teams can trust the AI to exclude error-free documents and focus human work only on cases requiring attention. That mean 90% of the documents do not need human attention.
What we learned
Getting consistent, structured outputs from LLMs requires careful agent orchestration—we learned to use specialized agents for different reasoning tasks rather than one monolithic prompt.
What's next for PayScope
Enhance the reliability of pre-filled forms to enable full automation of the follow-up process between asset managers and custodians. Expand beyond dividends to cover interest payments, corporate actions, and other custodial errors that follow similar reconciliation patterns. Build direct integrations with major custodian banks to ingest statements automatically rather than requiring manual uploads.
Built With
- anthropic
- claude
- fastapi
- python
- react
- typescript

Log in or sign up for Devpost to join the conversation.