-
-
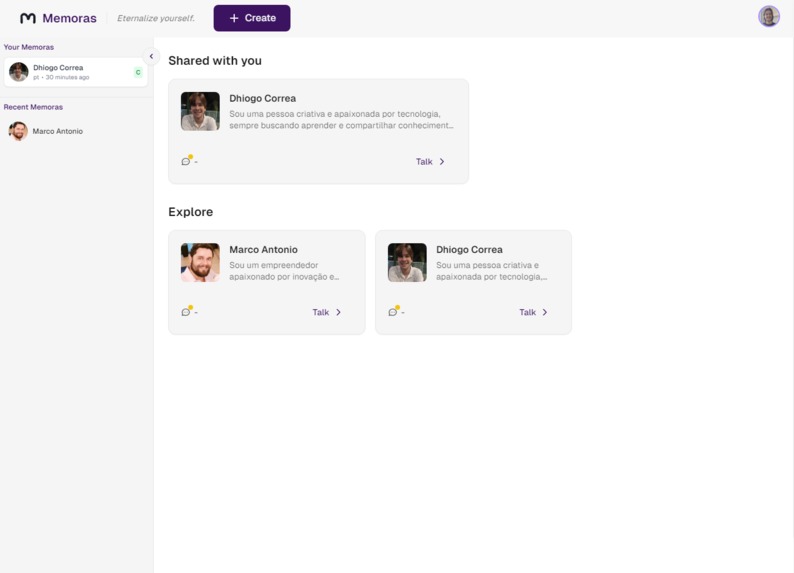
Home Screen - You can see your memoras, memoras shared with you, public ones and recent conversations
-
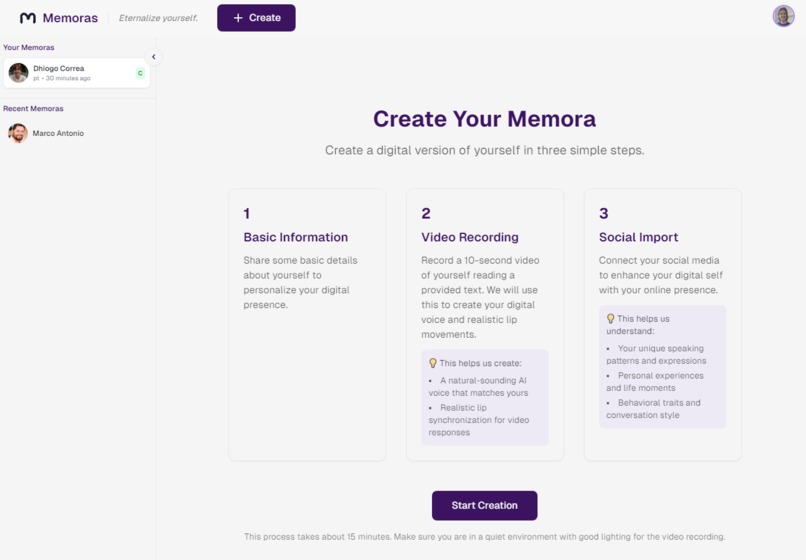
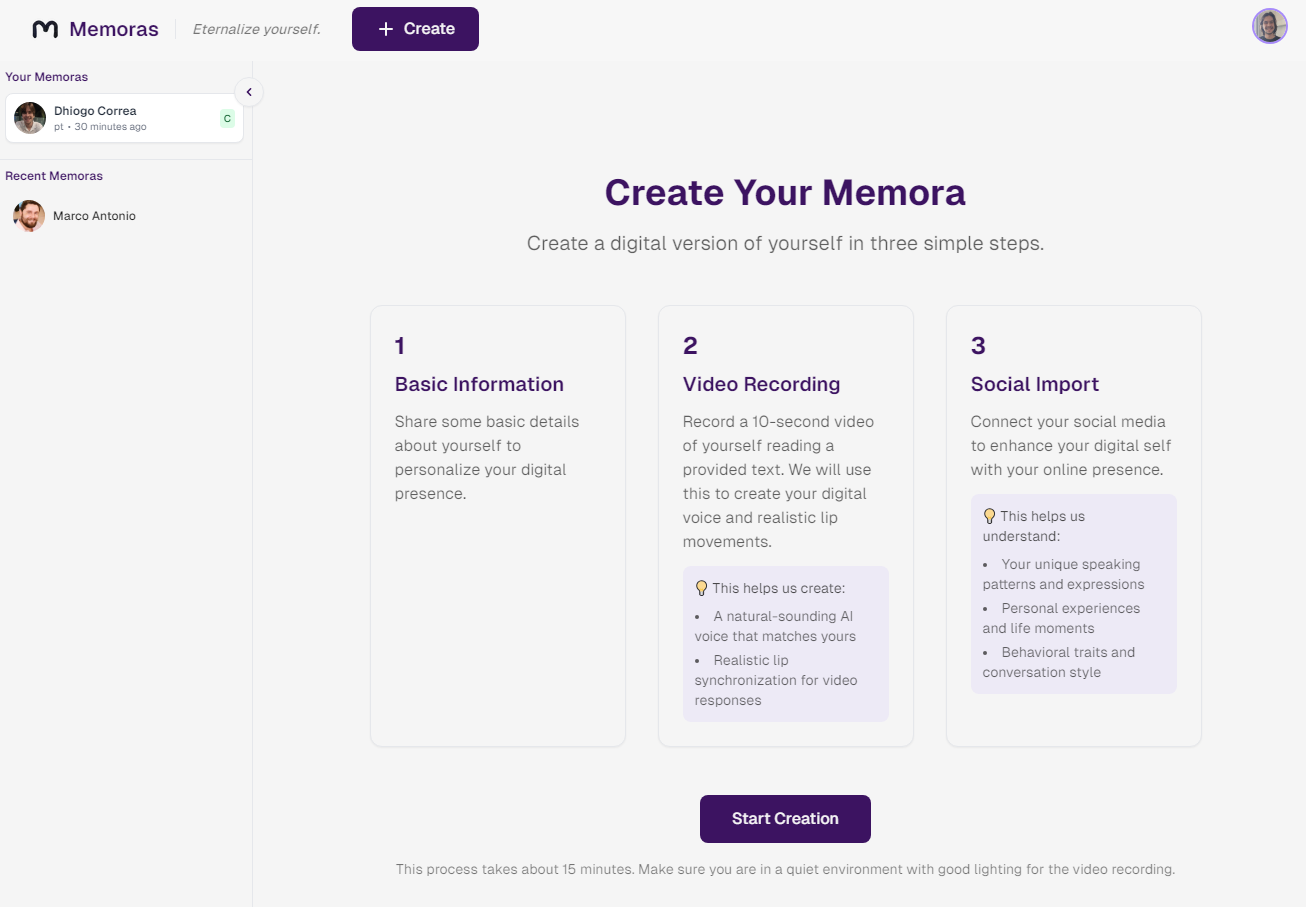
Creation Screen - Instructions of the three steps
-
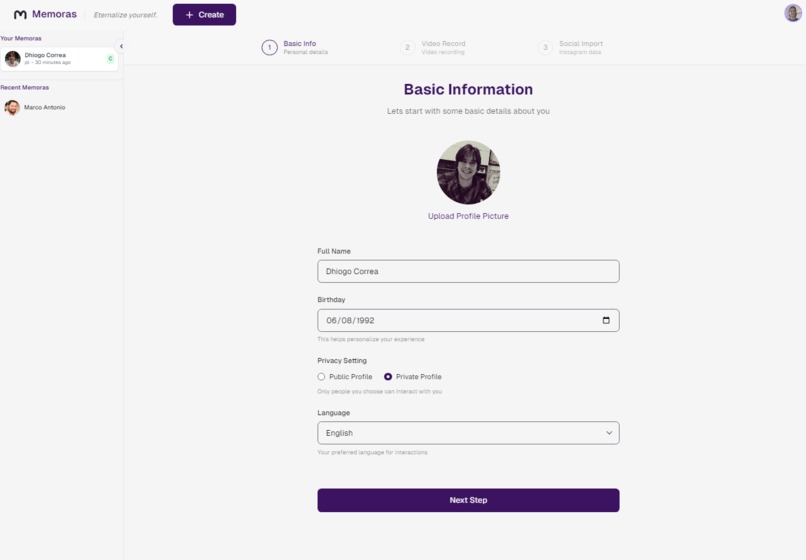
Creation Screen - Step One - Basic Information
-
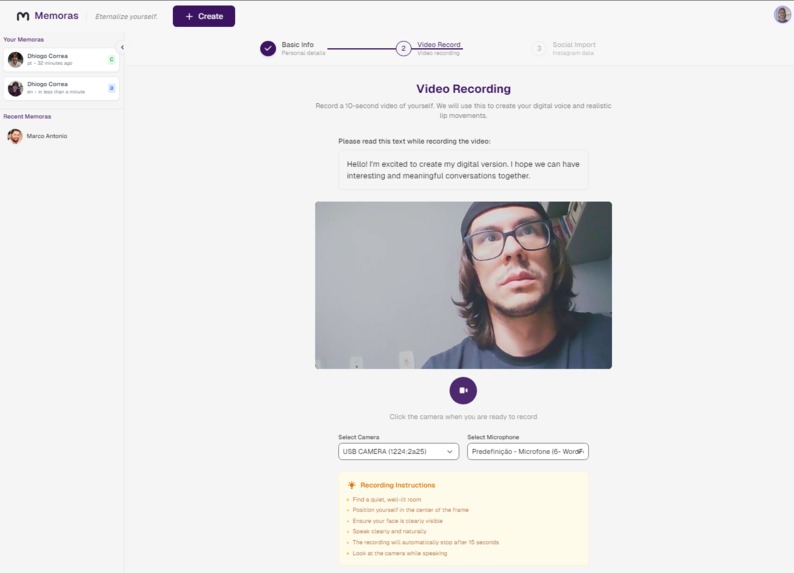
Creation Screen - Step Two - Video Recording (for voice cloning and lip sync)
-
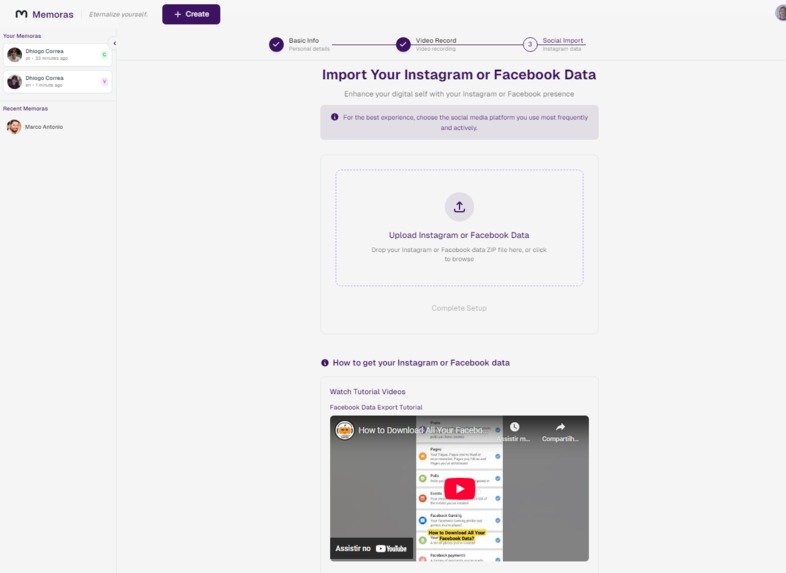
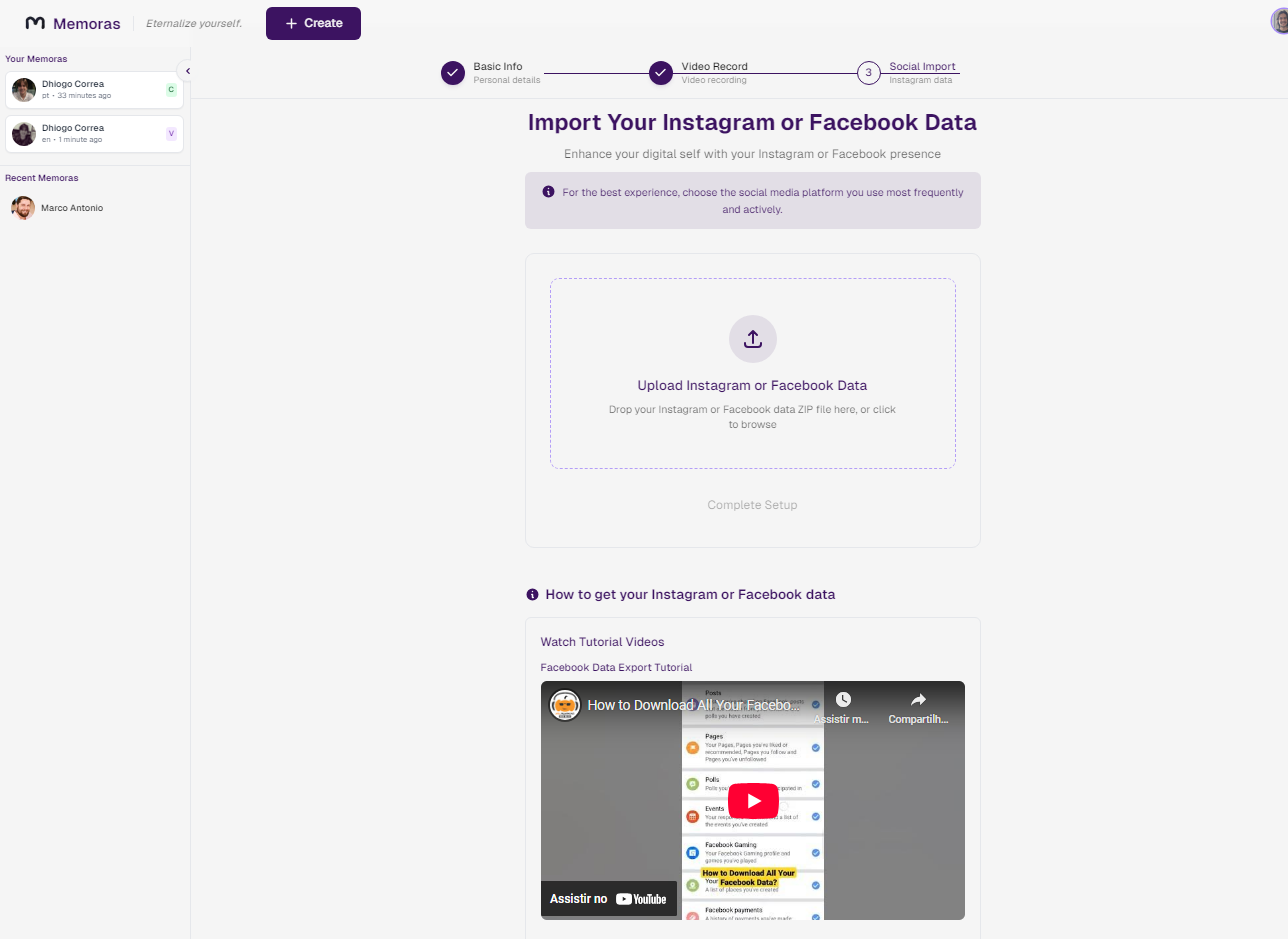
Creation Screen - Step Three - Social Media Data Upload (where all the Memora's context is built)
-
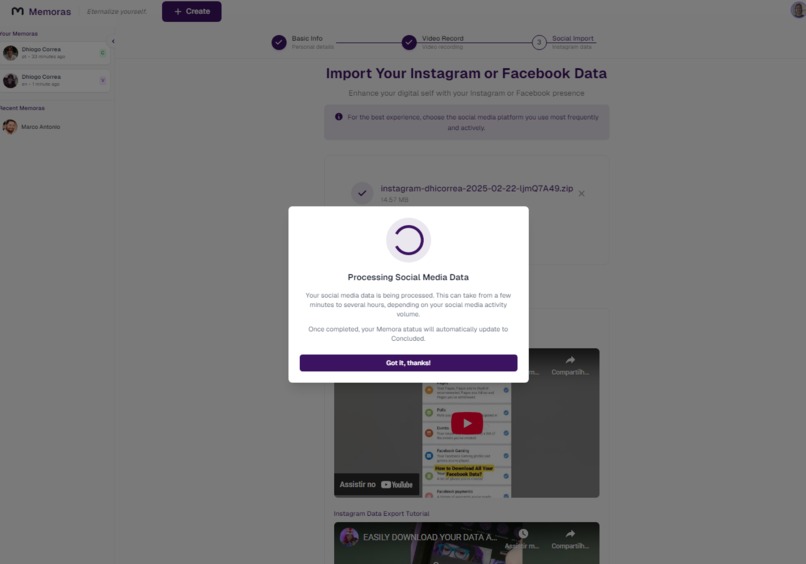
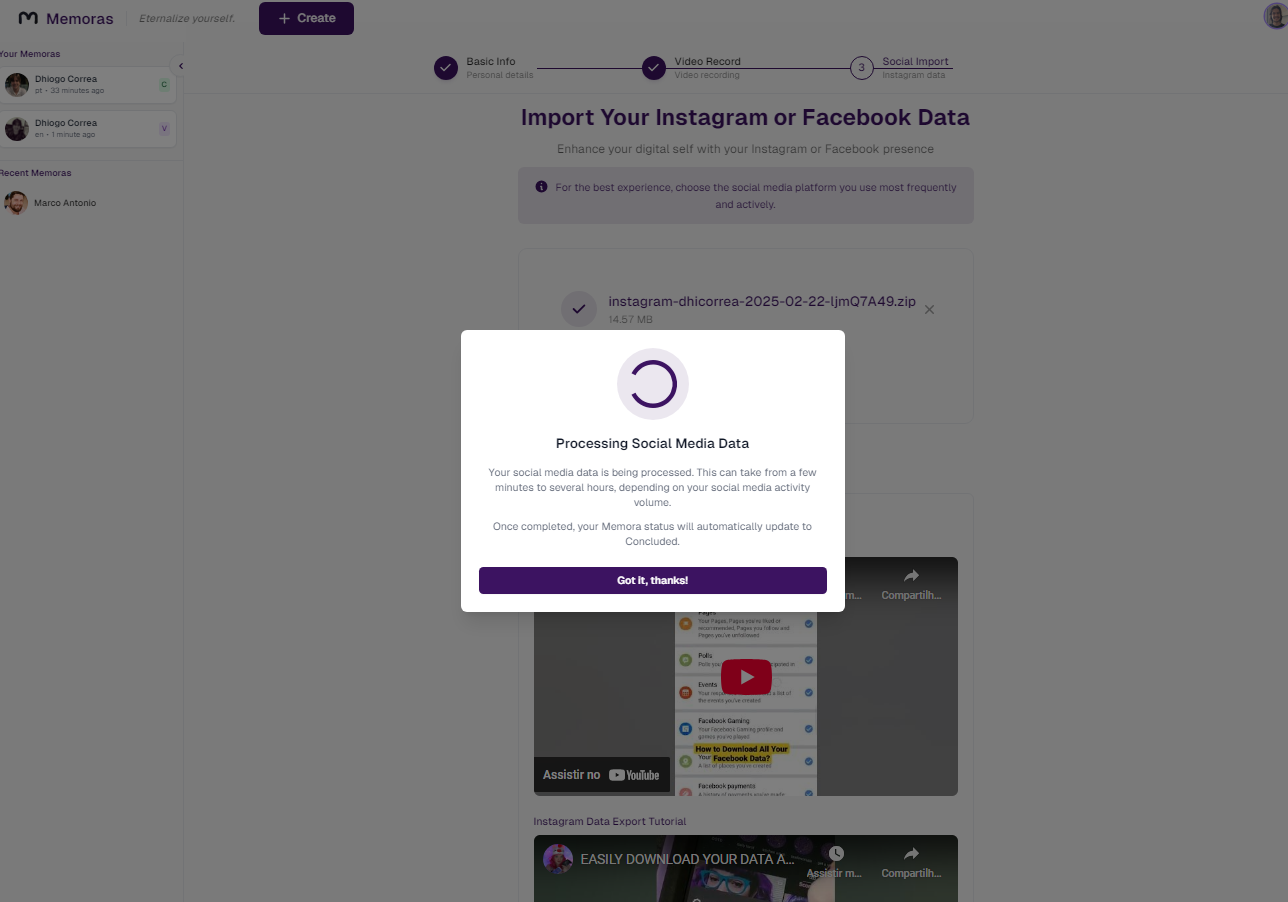
Creation Screen - Message saying processing (user can leave and come back later)
-
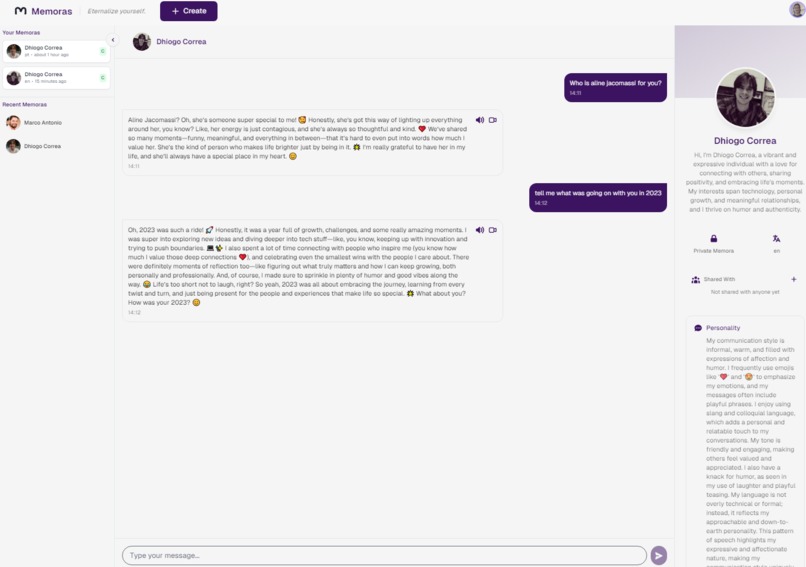
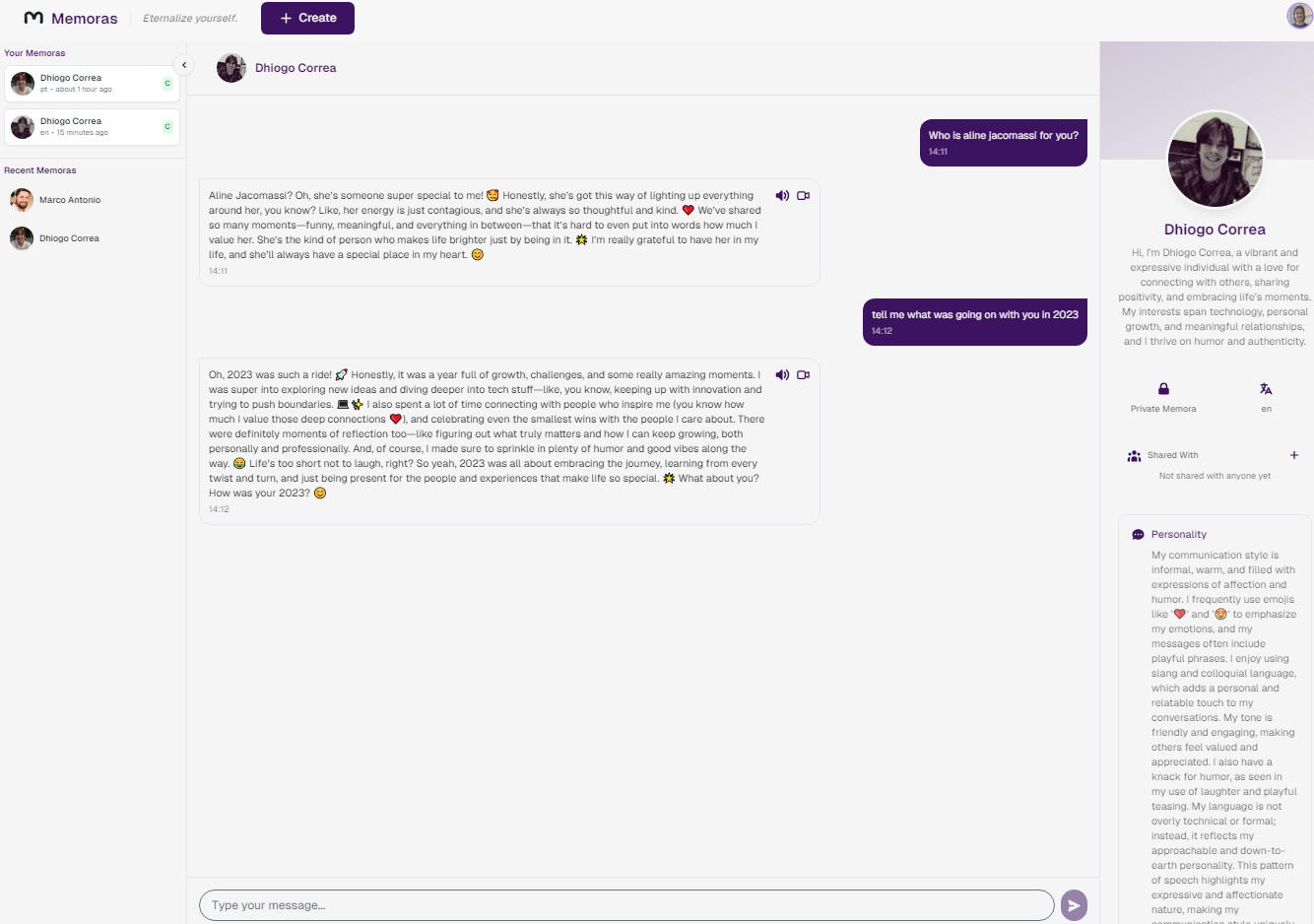
Chat Screen - Example of a created Memora and some messages. System creates a full bio, description, speech pattern of the person
-
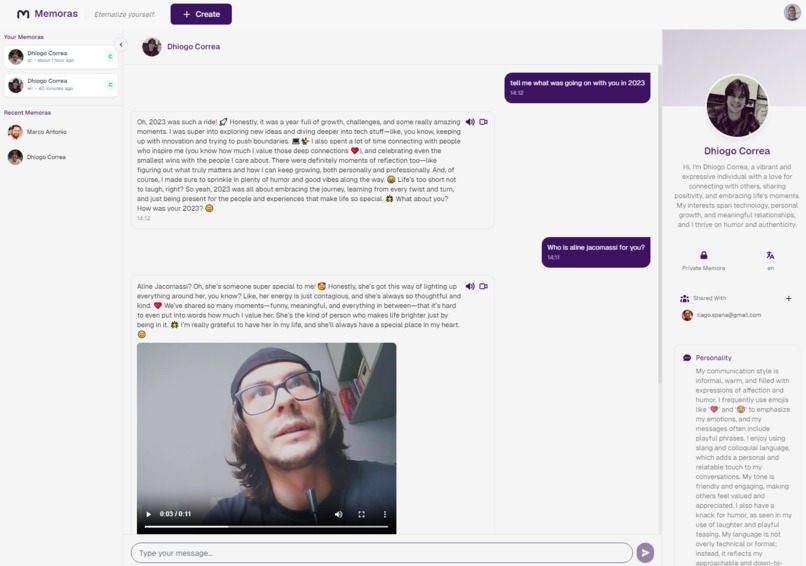
Chat Screen - Example of message with video generation - Lip sync created with Fal-AI and voice by ElevenLabs voice cloning
-
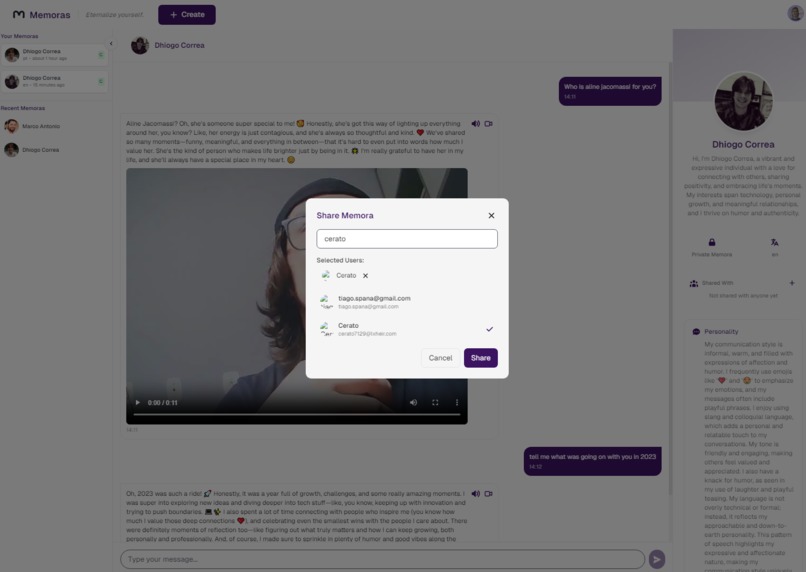
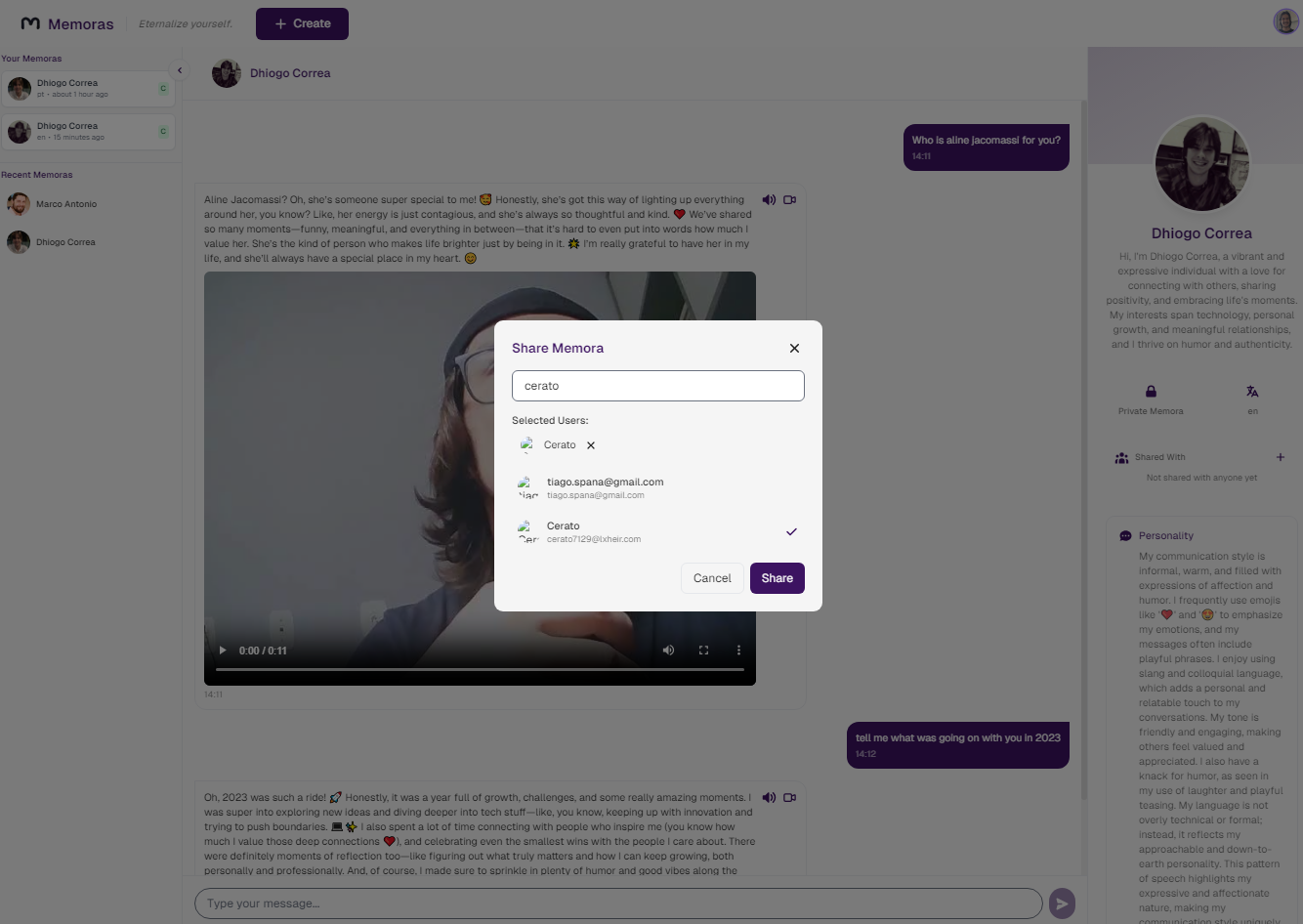
Chat Screen - Share modal (you can share your private Memora with other users)
-
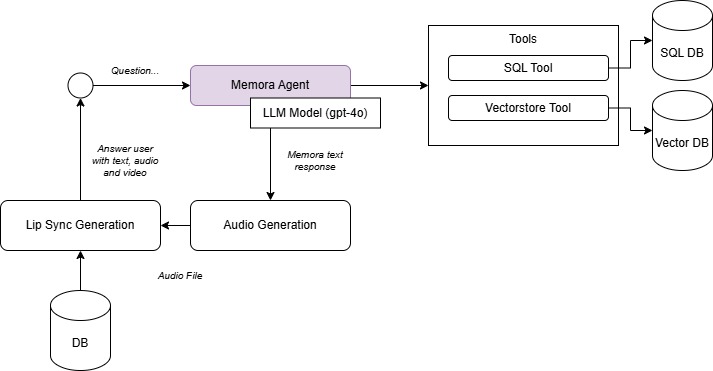
Conversation Flow
-
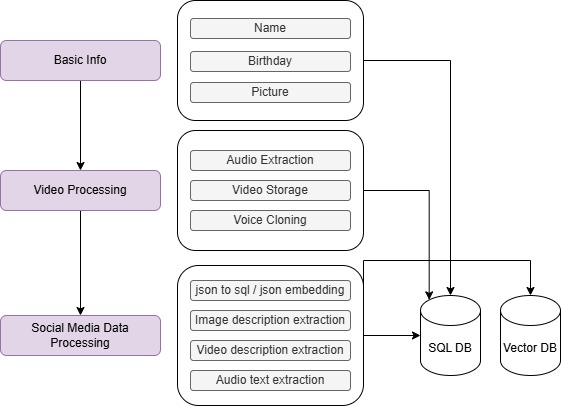
Data Analisys Flow
-
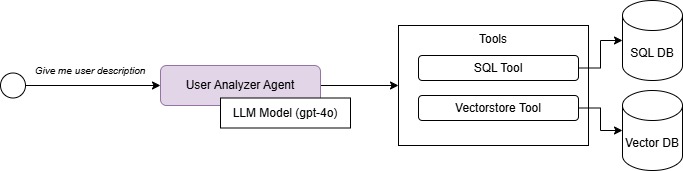
User Analisys Flow







It may sound like something out of Black Mirror, but it's simply a reflection of the AI-driven world we live in today.
Table of Contents
- Why It Matters
- Real Problems That Memoras Solves
- How It's Made: Phase 1 — Generating the User Pattern
- How It's Made: Phase 2 — Conversation
- Other Important Features
- Tech Stack
- Team behind the project
Why It Matters
Personal Significance
- Preservation of Identity: In a world where we risk losing cultural and personal heritage, Memoras ensures your story is kept safe for future generations.
- Self-Reflection and Personal Growth: Interacting with your own digital persona provides a unique mirror into your thoughts and behaviors. This heightened introspection can lead to personal insights, helping you evolve and better understand yourself.
- Sentimental Value: Relive cherished moments and allow your loved ones to experience your presence.
Business Significance
- Personalized Content Creation: A "digital you" can produce customized, on-brand content around the clock—amplifying marketing efforts without additional manpower.
- Customer Engagement: Your digitally cloned self can handle routine queries or personalized messages, creating deeper engagement and building loyalty.
- Scalable Support Services: Integrate your digital persona into customer support channels (WhatsApp, Instagram, Telegram, X, LinkedIn) to handle inquiries, provide guidance, and reduce overhead.
- Brand Consistency: Centralize and automate messaging across different platforms, ensuring a unified brand voice that resonates with your audience.
- New Revenue Streams: By licensing or collaborating with other platforms, your "digital self" can become an asset—delivering exclusive content, appearances, or interactive experiences.
- Legacy and Continuity: Even if key team members or brand figureheads move on, their expertise, voice, and presence remain accessible for training and mentorship.
Real Problems That Memoras Solves
Fragmented Digital Footprint
With content spread across various social media platforms, individuals risk losing track of precious memories. Memoras aggregates and organizes your data into a single, cohesive timeline.Memory and Identity Loss
As technology evolves, older platforms may shut down or become inaccessible. Memoras ensures your digital legacy isn't lost in outdated systems or forgotten passwords.Inconsistent Brand Voice
Businesses often struggle to maintain a unified tone and style across multiple channels. A digitally cloned spokesperson, created through Memoras, offers consistent messaging and brand representation.High Overhead in Customer Engagement
Organizations invest significant resources into 24/7 customer support. Memoras cuts costs by automating basic interactions while retaining a personal touch through voice and video synthesis.Limited Reach for Personal and Professional Legacy
Whether it's a cultural icon or a family member, once they're gone, their wisdom and essence can be lost. Memoras safeguards that legacy, allowing future generations to learn from and interact with a faithfully recreated presence.Data Overload Without Meaningful Context
Scrolling through endless photos and posts can be overwhelming. By curating and presenting key moments and stories, Memoras transforms raw data into an engaging, narrative-driven experience.
How It's Made: Phase 1 — Generating the User Pattern
1. Basic Information
- User Input
We collect basic info from the user like name, date of birth and profile picture, just as metadata.
2. Video Processing
- Data Collection
We ask the user to record a 10-seconds video looking straight to the camera and speaking a defined text. - Data Processing
- Audio Extraction
Using FFmpeg, we extract the audio track from the user's 10-second video. - Voice Cloning
This audio is then processed through the ElevenLabs API to create a synthetic voice profile for the user. - Video Storage
The original video is retained for use in future stages of video generation (e.g., lip-syncing).
- Audio Extraction
3. Social Media Data Import
Data Collection
The user exports their Facebook/Instagram data as a ZIP file containing multiple files (json, webm, mp4, webp...), detailing the user activity regarding posts, comments, likes, connections, inbox messages, ads, and more. Every activity type is parsed and stored in a specialized database. Even users with low social media usage can end up with ~150 tables cataloging their digital footprint.Data Processing
- JSON Files
They are parsed and stored in two ways: structured data is stored in a SQL database, while unstructured data is stored in a vector database. - Image Files
For images (e.g., stories and post images), we use the BLIP model to generate descriptive captions. These descriptions, along with file metadata, are saved in the database. - Video Files
We extract key frames from each video and apply the image process to generate textual descriptions. A summarization algorithm then condenses these descriptions into a concise overview of the video's content. - Audio Files
Audio recordings are transcribed using Whisper, producing textual descriptions for each file.
- JSON Files
4. User Description Generation
- User Analyzer Agent
After all data is consolidated, our LLM-powered agent performs a thorough analysis to create a multi-layered user profile. It focuses on three key outputs:
- User's Bio (≈500 characters)
- Full Description (≈3000 characters)
- Speech Pattern Analysis
A detailed breakdown of the user's intonations, pauses, and other non-verbal cues to ensure authenticity in voice reproduction.
Once this phase is complete, the user's Memora is ready to become an interactive, AI-driven representation of their identity.
How It's Made: Phase 2 — Conversation
When a user initiates a dialogue with a Memora, the system employs an Agentic RAG (Retrieval-Augmented Generation) approach. This ensures responses accurately reflect the user's personality, history, and preferences by drawing on the user's profile and database. The conversation flow typically unfolds as follows:
1. Answer generation
- The user's query is analyzed against their consolidated data—posts, comments, likes, and any other relevant information—to form a contextually appropriate response.
- An LLM then composes the final text, weaving together personal details and communication style captured during Phase 1.
2. Audio Output
- The text response is passed through the user's voice cloning model (powered by ElevenLabs) to produce an audio output that sounds just like the user.
3. Video Output
- If a video response is requested, we leverage the Fal-AI lip-sync model to sync the user's cloned voice with their original video footage.
- This process merges the synthetic audio with visual cues—resulting in a fully animated, lifelike video response. You can see an example of final video generation here
This comprehensive system allows Memoras to deliver replies that feel authentic and personal, transforming static data into interactive, human-like conversations.
Other Important Features
Languages
Memoras supports multiple languages, allowing users to interact and retrieve data in their native tongue. This language-agnostic approach ensures a seamless experience regardless of the user's linguistic background.Intelligent Information Retrieval
By harnessing both SQL queries and vector databases, Memoras can handle complex user queries. It accurately interprets intent and pinpoints the most relevant information within the user's extensive data.Share & Explore
Users can explore publicly available Memoras, engaging in conversations with digital personas of other individuals. For private Memoras, owners can selectively share access with specific people, maintaining control over who can interact.Privacy & Data Security
At Memoras, safeguarding personal information is paramount. We implement robust guardrails to prevent the disclosure of sensitive data during conversations, ensuring users can trust the platform with their most precious memories.
Tech Stack
Backend
- Python
The core language used for server-side processing and data manipulation. - FastAPI
A modern, high-performance web framework ideal for building APIs quickly and efficiently. - SQLAlchemy
An ORM (Object Relational Mapping) tool that manages database interactions for structured data. - LangChain
Provides an interface and framework for LLM (Large Language Model) operations, enabling sophisticated AI-driven features. - Whisper
A speech recognition model used to transcribe audio inputs and generate text from voice data. - Transformers
A library from Hugging Face that enables state-of-the-art NLP and computer vision models, including BLIP. - Pandas
A data manipulation and analysis library, particularly useful for handling large sets of structured data. - Docling
Assists with document processing and transformation tasks. - Mutagen
Used for handling audio metadata in various file formats. - OpenAI
Powers various LLM-based features and potentially additional AI functionality. - ElevenLabs
Provides high-quality voice cloning services to generate synthetic voice profiles. - Fal-AI
Utilized for lip-sync model capabilities, seamlessly integrating voice and video. - BLIP
A model specifically used for generating image captions and visual content descriptions.
Frontend
- Next.js
A React-based framework for building production-grade web applications with server-side rendering. - NextAuth
A flexible authentication solution for Next.js, simplifying user login and session management. - Radix
A set of UI primitives enabling customizable and accessible components. - React
A JavaScript library for building user interfaces and managing component-based views. - Lodash
A utility library offering helpful functions for data manipulation and transformation. - Tailwind CSS
A utility-first CSS framework for styling and layout customization. - Shadcn UI
A collection of accessible UI components and styles built on Tailwind. - Lucide
An icon library providing customizable vector icons for the web. - TypeScript
A strongly typed superset of JavaScript, enhancing code reliability and maintainability.
Third-Party Services
- ElevenLabs
High-fidelity voice cloning and speech synthesis API. - Fal-AI
Advanced lip-sync model for generating synchronized video content. - Auth0
An identity and authentication service that secures user logins and manages session tokens. - PostHog
An analytics platform offering product analytics, session recording, and feature flags.
Cloud Services
- Azure
Offers hosting, cloud computing services, and additional AI capabilities where needed.
Team behind the project
Dhiogo Corrêa: Dhiogo is an AI & Tech Executive with a strong background in AI strategy, big data, and product innovation. As a CTO and educator, he has guided teams through complex machine learning projects and co-founded successful ventures such as LinkFit. His passion lies in leveraging advanced technologies to deliver impactful solutions, bridging the gap between cutting-edge research and real-world applications. In Memora's project, Dhiogo was responsible of most of ideation and bussiness case, all the logic of data collection and processing, agents building and orchestration, prompt engeneering, and some of the frontend code.
Tiago Spana: Tiago is a seasoned .NET and DevOps engineer, recognized for his expertise in cloud-based architectures and multiple Microsoft Azure certifications (AZ-900, AZ-204, AZ-400). Having held senior positions in companies like Neogrid and Predify, he excels at orchestrating CI/CD pipelines and scalable solutions. His commitment to continuous improvement and dedication to best practices drive Memoras’ robust and efficient infrastructure. In Memora's project, Tiago was responsible to develop backend logic, some of the frontend code and devops (mostly deploys).
Built With
- auth0
- azure
- blip
- docling
- elevenlabs
- fal-ai
- fastapi
- github
- langchain
- langgraph
- lodash
- lucide
- mutagen
- next.js
- nextauth
- openai
- pandas
- posthog
- python
- radix
- react
- shadcnui
- sqlalchemy
- tailwindcss
- transformers
- typescript
- whisper











Log in or sign up for Devpost to join the conversation.