-
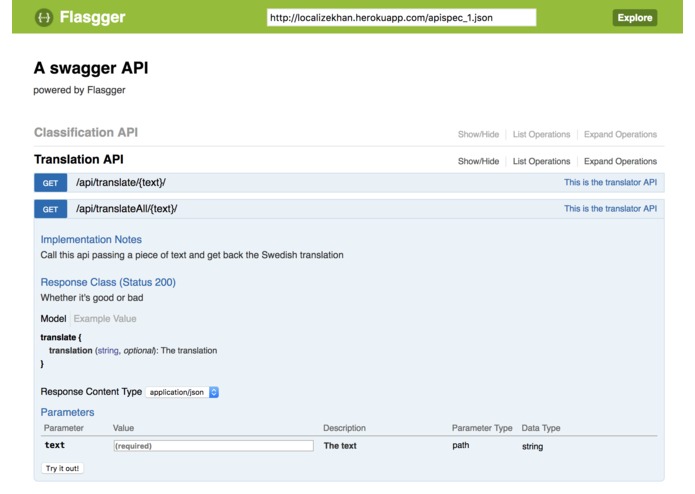
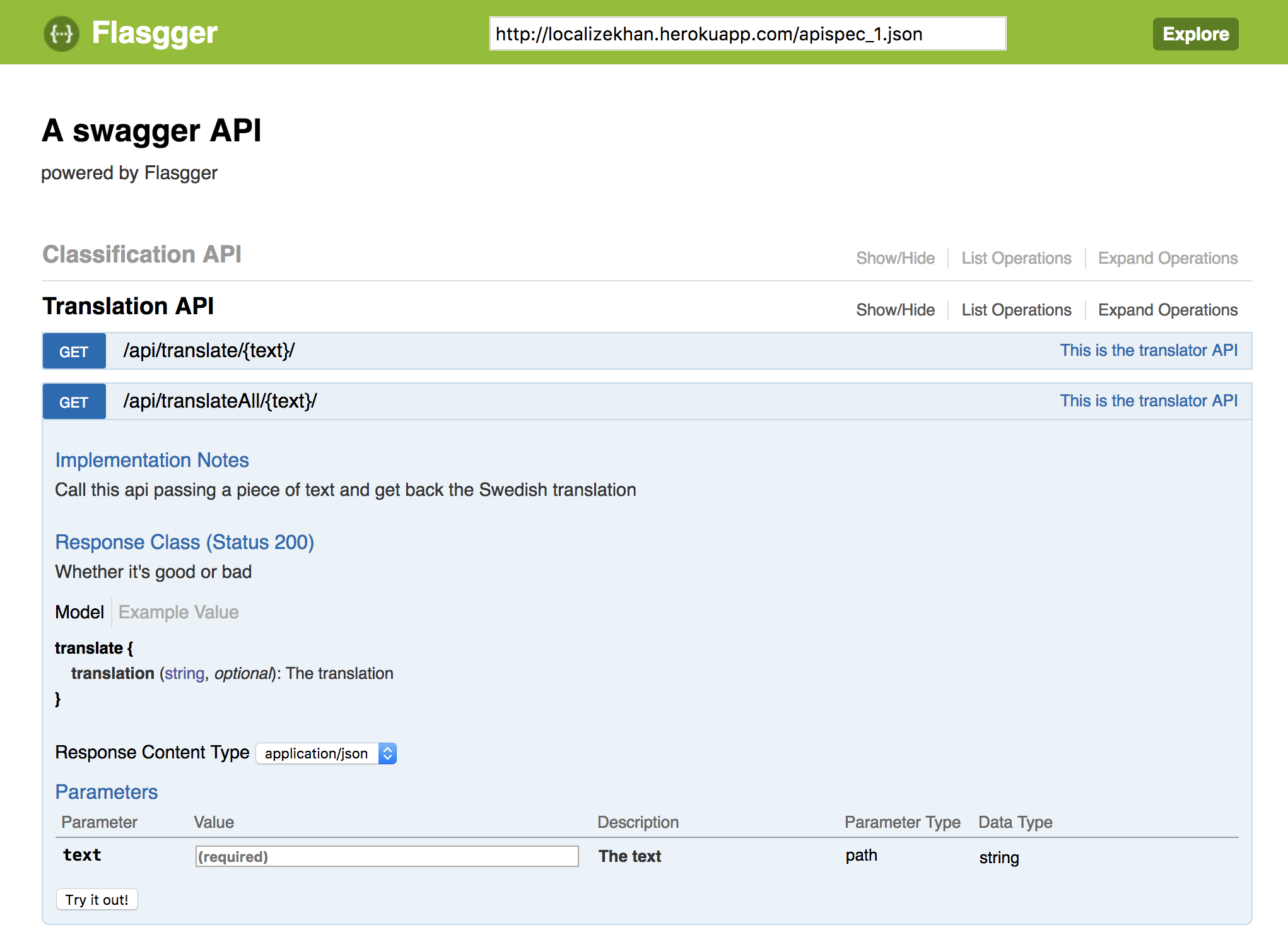
View of the API Docs
Inspiration
KhanAcademy is a nonprofit organization with the purpose of providing free education for everyone. With the mission of reaching out to a larger audience, KhanAcademy has set out to make their material available in many languages. This comes with the problem of translating thousands of hours of teaching material, which is an intrinsically slow process when carried out manually and thus hindering the outreach to people in need. As such, it would be of great interest to automate the translation process using computer software in order to achieve a high throughput while still preserving the high quality content.
To this day, translation services has provided varying results depending on the subject that is translated. This has led to large quantities of translated texts incapable of reaching sufficient quality. To combat this problem, we have set out to prototype a classification system to evaluate the translated texts and thus aid in the process.
What it does
Our solution improves the process of proofreading by automatically classifying translated texts to determine the quality of the translation. The idea is to minimize the amount of tedious manual work of proofreading texts. By placing the classifier immediately after an automatic translator, high quality texts determined by the classifier can be sent directly to production while low quality texts are sent for manual reevaluation.
How its built
We built the classifier using Python as the programming language using the machine learning library Scikit-learn and the natural language toolkit, NLTK. Translations were broken down into sentences and classified using a naive Bayes classifier as it provides probabilistic insights into the translation process. The web scraper was built using BeautifulSoup, a Python html-parser.
To build a user friendly interface we used Swagger, a tool for designing, building, and testing APIs. For this, a web server was set up using Flask, a lightweight Python framework.
Challenges we ran into
As we choose a data driven approach when building the classifier, we were naturally constrained by the amount of available labeled data. In addition, we had problems representing texts in a machine readable format when training and evaluating the classifier. This made our classifier inaccurate due to the high dimensionality occurring when working with texts and as we did not take into account of grammatical structures.
Accomplishments that we're proud of
We are proud to have built a ready to train classification system with a corresponding lightweight and easy to use API. Furthermore we have designed a text scraper capable of extracting any words or sentences on the clearnet and translating them with the help of wikipedia.
What we learned
By working with the problem, we obtained an insight into the problems that non profit organizations face under limited resources. We also learned the importance of working as a team in order to overcome challenges faced and the usefulness of asking for help when needed. As we worked under limited time, we learned how to quickly set up environments for prototype building and thus our technical skills were enhanced. Finally, the presentation along with the associated coaching improved our ability to communicate and pitch our work.
What's next for LocalizeKhan
Next up would be first and foremost to improve the quality of the currently translated texts. In addition, we think it would be beneficial to further develop a classification system and integrate it into the current system that is used.
Built With
- beautiful-soup
- bogosort
- flask
- google-cloud-translate
- machine-learning
- nltk
- no-sleep
- numpy
- python
- scikit-learn
- swagger
- wikipedia-crawling





Log in or sign up for Devpost to join the conversation.