-
-
LLM application
-
Data pipeline
Inspiration
Imagine being a new joiner at a company, where everything is new to you - the system, processes, tools, and work environment. We understand that starting a new role can be overwhelming. For example, trying to access internal tools, connecting to the company VPN, searching through an internal knowledge base, and understanding task specifications if you're a software engineer. As a software engineer, translating specifications into code and ensuring compliance with the company coding standard can be challenging for new joiners. Mapping a large number of fields can be time-consuming.
What it does
We believe that our hack idea can help new joiners by utilizing a large language model and a vector database to:
- Make it easier to search and find related confluence data.
- Summarize documents.
- Generate code.
How we built it
We've divided the work into three parts:
- Data Preparation
- LLM application
- Infrastructure
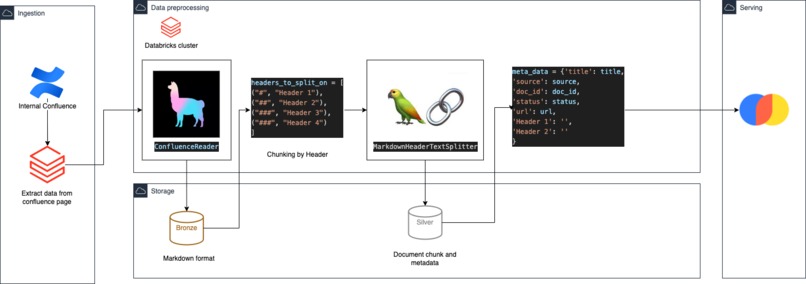
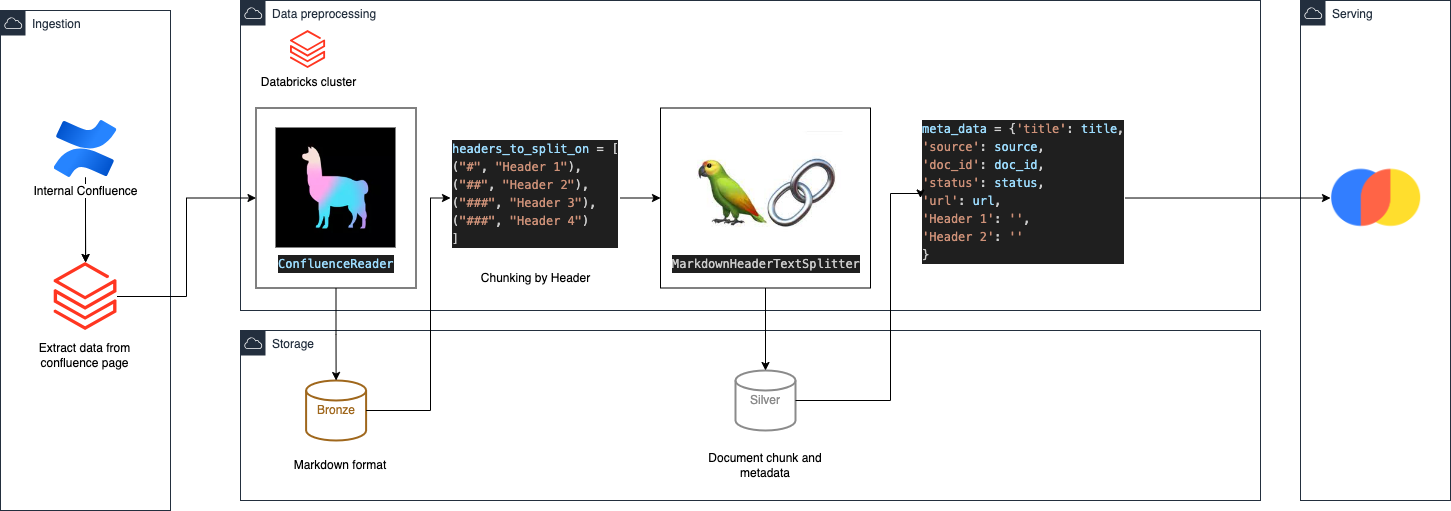
For data preparation, we use Databricks to pull data from our confluence. To build a data pipeline, we first need to understand the documentation structure and decide how to chunk the data. We can achieve this by using "Content-aware Chunking" in markdown format. Thanks to Llamaindex ConfluenceReader, loading the data in markdown format becomes easier. After obtaining the data, we separate it by header and sub-header. We also build metadata for each document, including the document title, source URL, header, and subheader. Finally, we have processed data ready for embedding. We chose Chromadb to store the vector data.
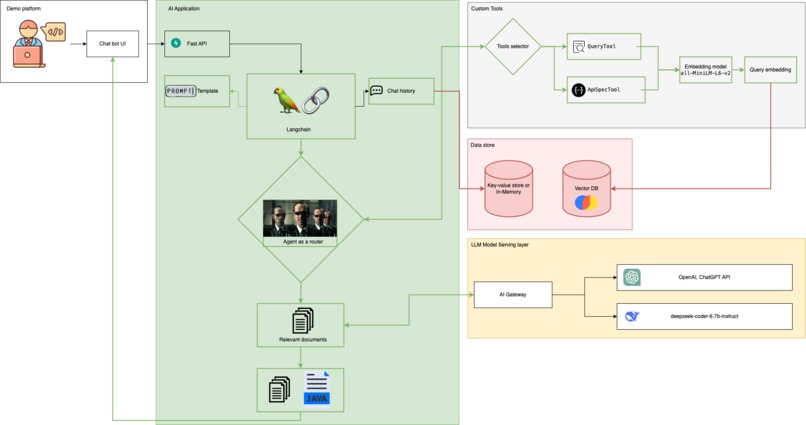
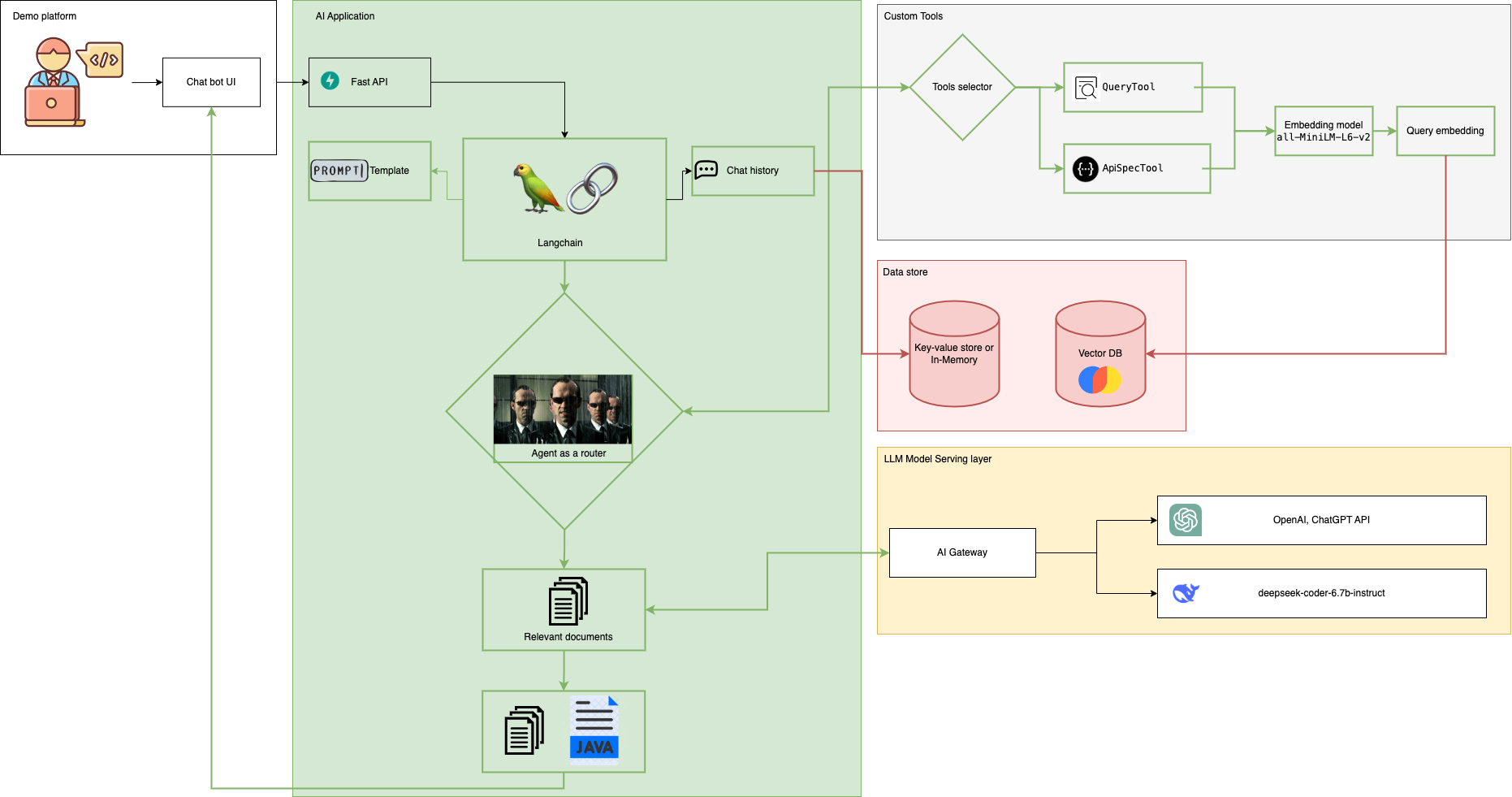
Moving on to our LLM application, we have built our chat UI and backend LLM application using FastAPI and Langchain. When users interact with the Chat UI, it calls the LLM backend. Langchain is the main part of the backend service, handling the chat logic, including the chat history and prompt template. We have defined the tools for Langchain, allowing the agent to select the best tool for each query. The query tool provides an overview of the API, while the API spec tool focuses on the input/output of the API. These tools are called the vector database to retrieve relevant documents. For the LLM model, we use both the CHATGPT API and the open-source model. We have also explored deep seek-coder for code-related tasks, as well as llama2.
Challenges we ran into
- Chunking is crucial for providing quality answers.
- Hosting a custom model can be challenging.
Accomplishments that we're proud of
We showed this demo to our software engineering team and they love it!
What we learned
Langchain is a powerful library, but it requires a deep understanding of its components to build an application.
What's next for JoiningJoy Virtual Buddy
- Finetune deep-seek coder model to make it understand our internal coding standard.
- Add software engineering functionality.
Built With
- amazon-web-services
- chatgpt
- chromadb
- databricks
- deep-seek-coder
- fastapi
- langchain

Log in or sign up for Devpost to join the conversation.