-

Interview Buddy
-
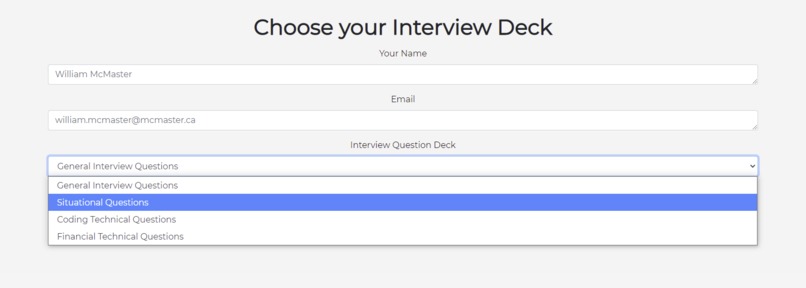
Choose your Interview Deck
-
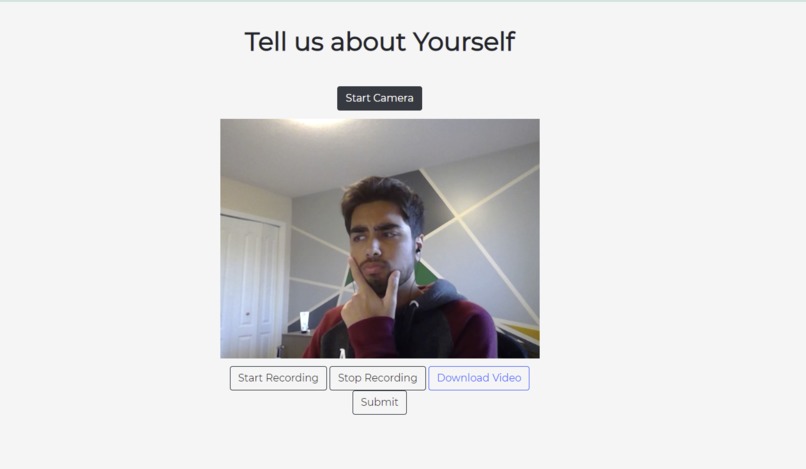
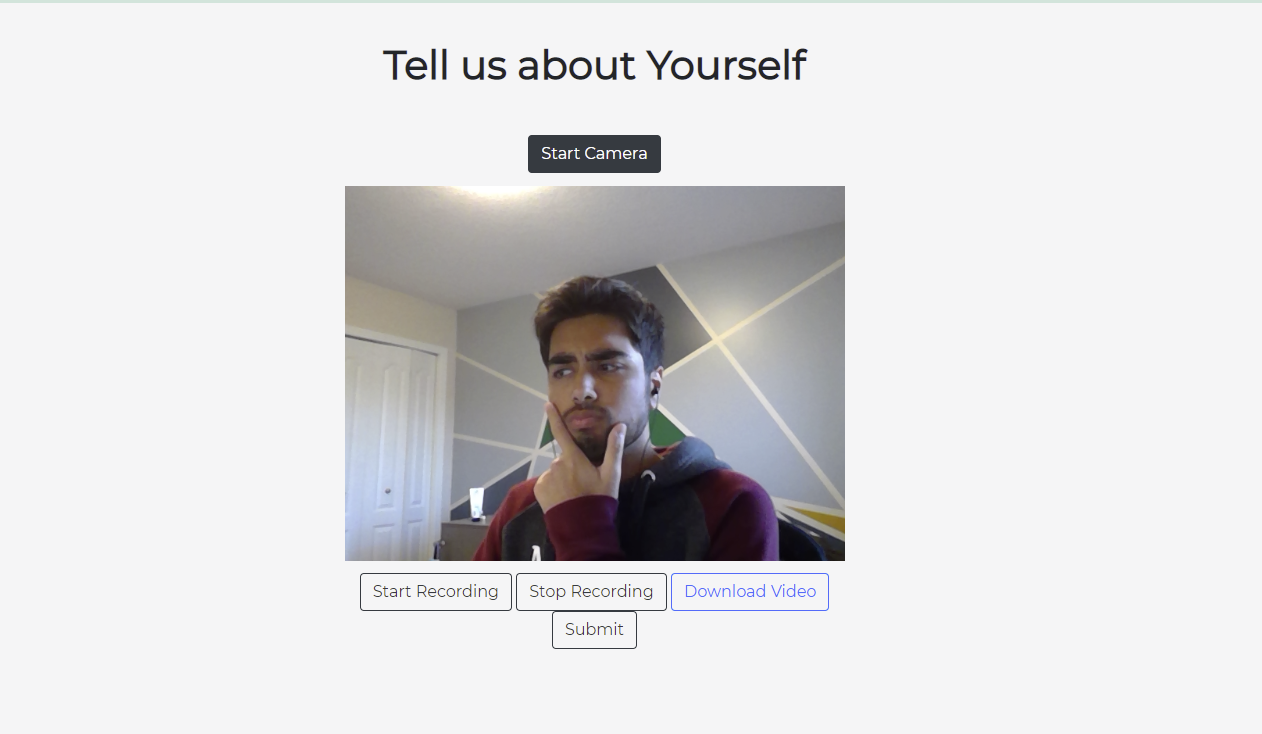
Record your Practice Interview
-
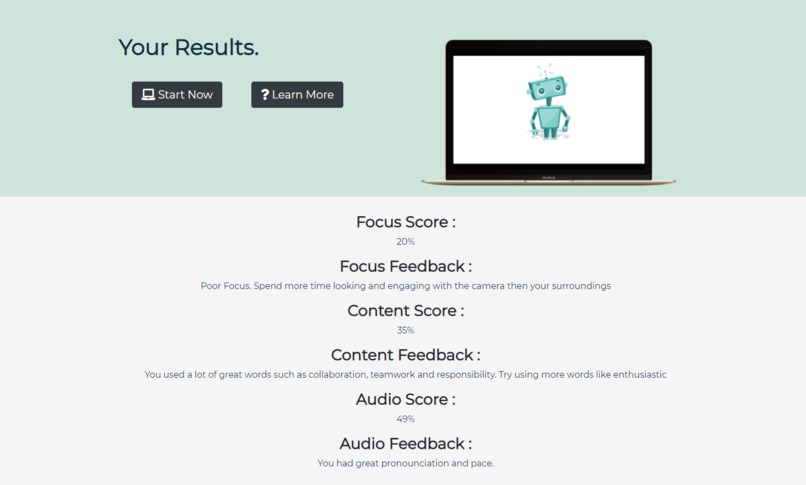
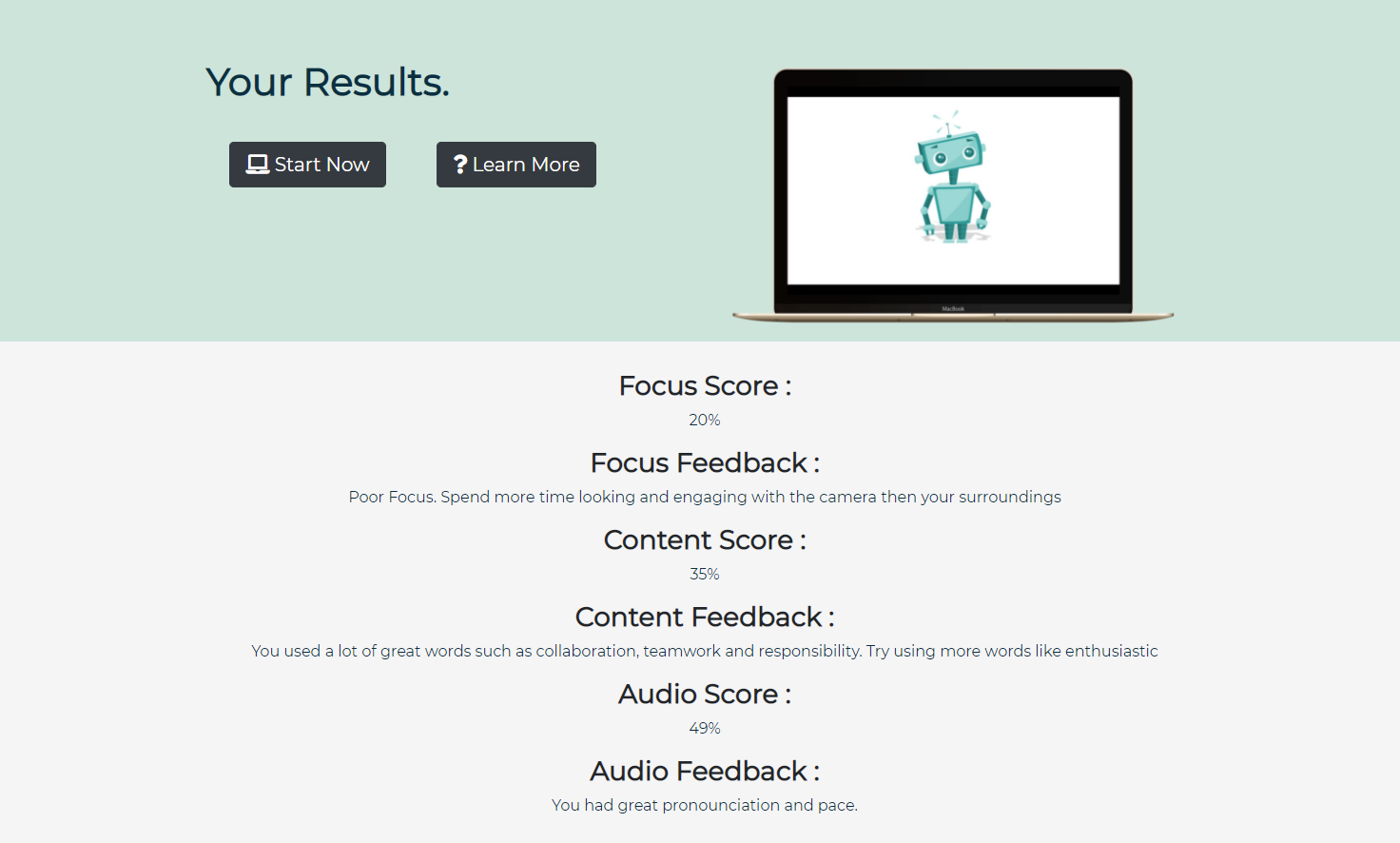
Interview Results

Inspiration
Does the prospect of interviews make you nervous? Do you freeze up when it comes time to answer a specific type of interview question? Do you lack confidence in your professional interactions? If you answered yes to any of those questions, we understand. That's why we designed Interview Buddy! Interview Buddy is a virtual interview assistant trained to notice the small details that matter. Buddy has a large repertoire of relevant interview questions in different categories to choose from. Our goal is to provide valuable feedback for students and young professionals so that they can build confidence and ace their next interview.
What it does
Interviewees are able to generate questions on our webpage, record their video responses, and receive a scored report on their attempts. Interview Buddy uses machine learning and computer vision to analyze a person's tone, eye contact, speech patterns, and the quality of their answer. After each response users have the option to download the video and view their interview scores. Their scores are calculated on a variety of factors and the quality of their answers is determined by our machine learning algorithm.
How we built it
The front-end of the application was built using HTML/CSS/JavaScript. The website was built to prioritize client usability. This was highlighted by implementing easy-to-navigate pages and a calming colour scheme. HTML provided the structure of the website while CSS created the cohesive theme. Bootstrap allowed us to rapidly prototype our product and build an interactive website. Videos were recorded from a webcam using Media Capture and Streams API integrated with Javascript. Javascript was also used to create a connection from the web page in the frontend to the server in the back-end. JQuery Ajax was used to send the videos as blob data to the Django server.
The backend was built using python and encompassed numerous open-source libraries. A pipeline was created which could intake a video from the website and evaluate the interview performance based on three metrics; the video, the audio, and the speech. The video portion of the pipeline first converted a .webm file to a .mp4 file, which was subsequently inputted to a pupil-tracking algorithm. This allowed us to evaluate an individual's focus by recording how frequently they were looking directly at the camera as opposed to looking at off-screen distractions. Following the video analysis, the .mp4 was converted to a .wav file, which was then inputted into an open-source library that evaluated the characteristics of speech. We were able to obtain metrics for speech and articulation speed, pronunciation, pauses, and the overall mood of the sample, which we could then use to grade the interview. Finally, the .wav file was transformed into a text transcript through the use of Google's Cloud Speech API. We compared the transcript to employer-approved answers to the provided interview question, using a TfidfVectorizer and Cosine Similarities to compare how much the provided sample aligned with the approved responses. The algorithm can also provide insight on what terminology was well implemented, and which terminology could be included in future attempts to improve one's score. These three analyses can be used to provide a comprehensive result allowing users to improve on all aspects of their interview skills.
Due to the virtual nature of the hackathon and for ease of collaboration, Git was utilized to maximize efficiency and accessibility.
Challenges we ran into
We ran into a roadblock when attempting to submit a POST request to send the video capture to our server for processing and analysis. Most online documentation was for uploading videos to send to a server, but this would not work for our purposes since our video file was locally generated by the Media Capture and Streams API. With the help of an EngHack mentor, we were able to successfully implement JQuery Ajax to upload blob data to the Django server. We faced an additional challenge because only one teammate was able to host a local server to test the functionality of the program. This limited our testing and prototyping capabilities. As well, due to the time constraints of this project, we were unable to host our final project on google cloud services, leading this to be a part of our next steps.
Accomplishments that we're proud of
This was all of our first time using Javascript, Media Capture API, and Computer Vision. As well, one of our teammates had never been to a hackathon before. Taking these circumstances into consideration, we are very pleased with how much we were able to learn. We are proud of the way Interview Buddy incorporates Computer Vision, Machine Learning, and RestAPIs with a fully functional HTML/CSS/JS webpage, bringing together a final product we are all very proud of. Our perseverance through countless errors at every stage of the process is also an accomplishment we value as we took roadblocks in stride and worked together to resolve them.
What we learned
Through this hackathon, we learned a lot of new skills and strengthened our collaborative abilities. We gained experience working with different APIs and aspects of Machine Learning. As well, we have familiarized ourselves with how front-end and back-end aspects of the project come together. We also discovered how far we could increase our ability to overcome the challenges we faced when working with new materials and different backgrounds. It was also a valuable learning experience to prep ourselves for project submission and demo.
What's next for Interview Buddy
In the future, we would like to expand our interview deck to expand past our current selection. And as mentioned previously, we aim to host our project on a cloud service instead of only on a local host. We are also considering adding a feature in the future that allows users to input their career field and a job description to generate more personalized questions with greater relevance to upcoming interviews.



Log in or sign up for Devpost to join the conversation.