
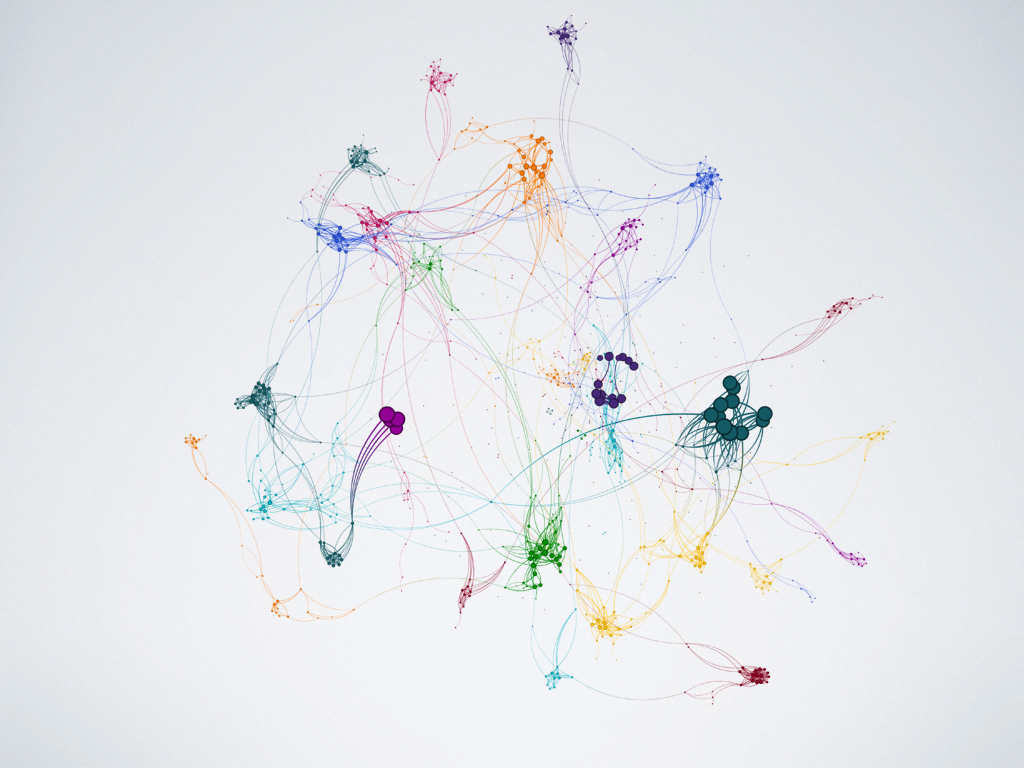




INTRO Using language similarity algorithm to identify patterns between offenders in the felony space. We used Quid to compute the language similarity for the criminal behavior of the parties:
(Figure 1)
In the graph each node represent an offender and it is clustered according to the type of criminal behavior that person has engaged in. The clusters are determined by features from their case charges. Connection between nodes depict similar criminal behavior between two individuals.
Removing the nodes with only one criminal case we remove three large clusters in our network; in particular clusters relating to minor assault, battery assault and assault on females. (We can visually demonstrate the HPPD's policies to warn offenders seems to be working as minor incidents don't show a high likelihood of a repeat offense.)
(Figure 2)
Insight: The fact that entire clusters relative to a minor offenses disappears when we identify single perpetrators does not mean that those behaviors are the not likely to be perpetrated multiple times by an individual. Instead, we can see that to identify serial criminal behavior we have to look for criminals that commit other kinds of felonies. (DV seems to be pervasive across the population but unrelated criminal behavior is a good signal for higher probability of DV.) This signal can help officers gauge/identify high-risk households from other criminal records.
GENDER By plotting the previous network with nodes colored according to gender (of offender) we note that females have high betweenness centrality. The betweenness centrality in network science represents the capability of a node to act as a bridge that connect two or more clusters. We infer here that males seem to specialize (repeat crimes) females are prone to commit crimes without an apparent pattern.
(Figure 3 & 4)
CALCULATOR It would be extremely useful for the police to have the ability to identify recidivism according to some metadata like gender, sex or nature of the first crime committed by a person. In order to provide this competence we used Bayesian inference to calculate the probability that a certain person is likely to be a serial criminal.
(Note: At the moment, for the sake of simplicity, we calculate probabilities based on boolean and not categorical variables. E.g. we do not account the kinds of crime events in all the ones identified by our clusters, but we distinguish just severe offenders (A and B on the DV list) and non-severe crimes (C and D on the DV list), weekday vs. weekend, etc.)
CASE SIMILARITY METRICS Using the same rationale as before we can create a network topology where nodes are single criminal cases and group them according to environmental metadata not present in the dataset (like price of the house where the crime happened) and characteristics of the perpetrator (age, race, priors). Here the network heuristics have been computed using simple cosine similarity without Quid to show that the method can be implemented with open-source software:
(See Figure 5)
A TOOL FOR THE FIELD We want to give officers in the field the opportunity to understand with a certain probability the scenario they may encounter in the field. For this purpose we developed the Crime Scene calculator that, using as input historical data, like the occurrence of crime at a certain day of the week or the ethnicity of the perpetrator, provides the likelihood that the person will be involved in severe DV (category A and B).
http://daniel.cartodb.com/viz/2cdcf5f2-6d56-11e4-b6e2-0e9d821ea90d/embed_map
FUTURE IMPROVEMENTS Include different pieces of datasets to explore more efficiently hidden patterns: GDP per zipcode area Sports outcomes (local basketball/football, etc.) Real estate prices Weather conditions


Log in or sign up for Devpost to join the conversation.