-
-
-
-
-
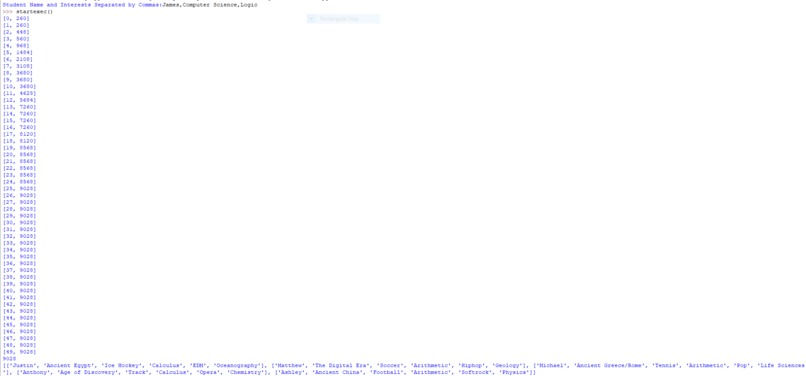
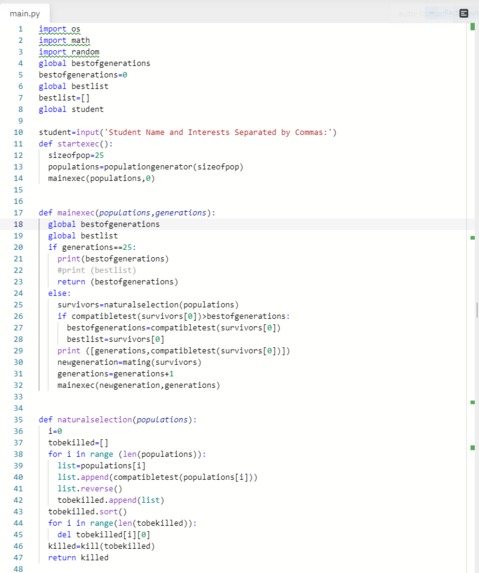
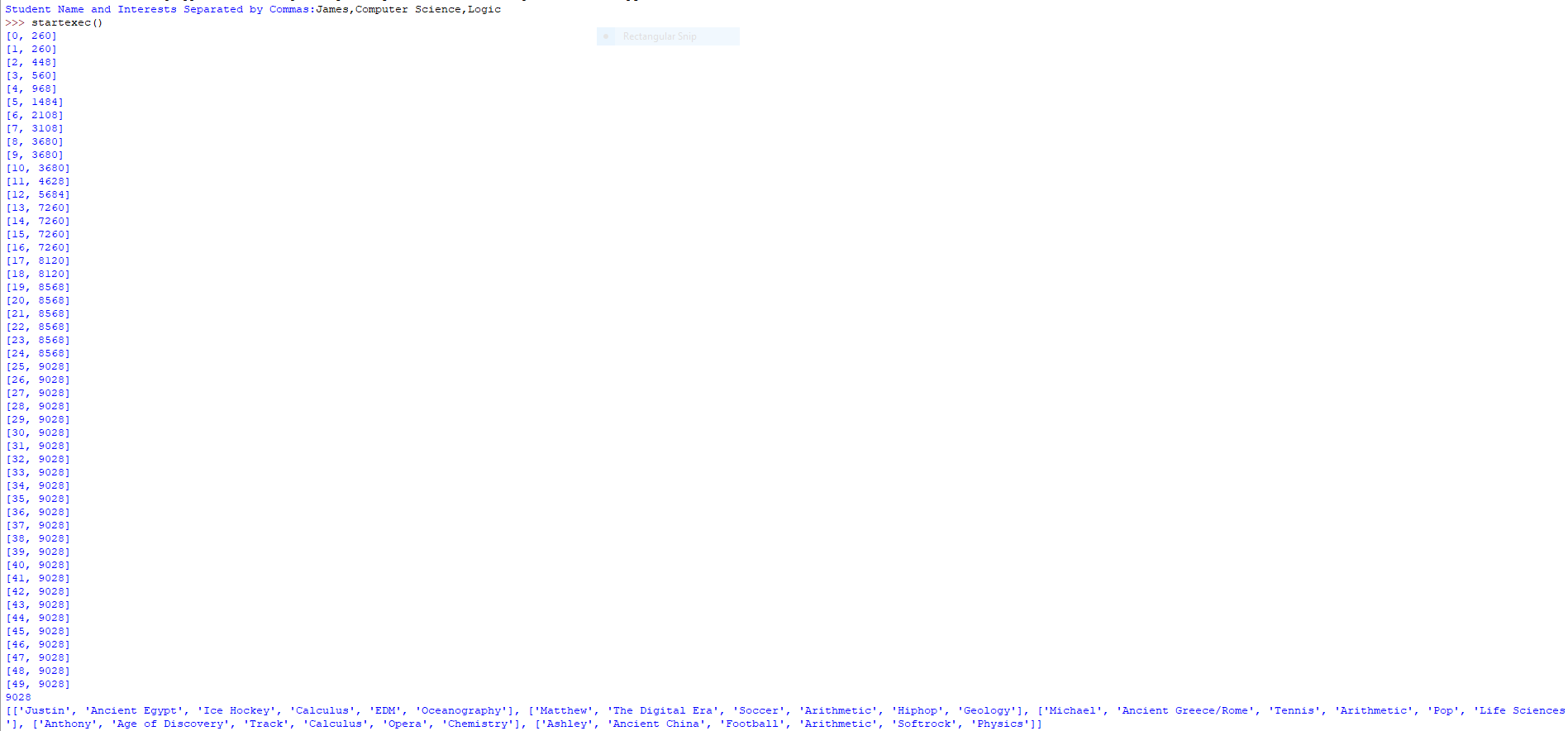
The numbers on the left are the compatibility score, and the list at the bottom is the group

Inspiration
When we went into our hackathon groups, we were expecting to have a not so great ones. This depressing mindset is a major problem in groupwork and academic success. This inspired us to create a software that matches people with similar interests together so people can feel more comfortable in their groups, and improve group dynamic.
What it does
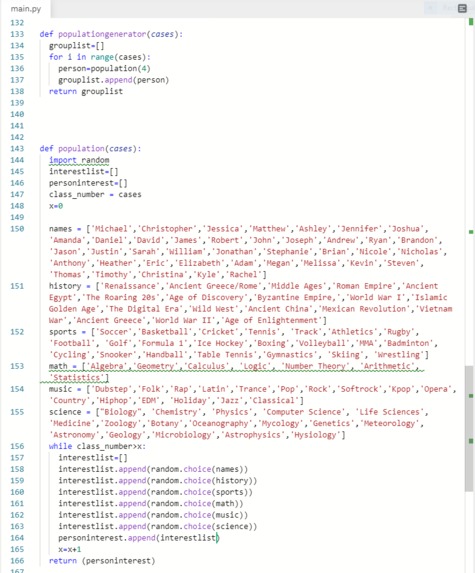
Our program takes a person with interests, and groups them into a group which has similar interests with the person.
How we built it
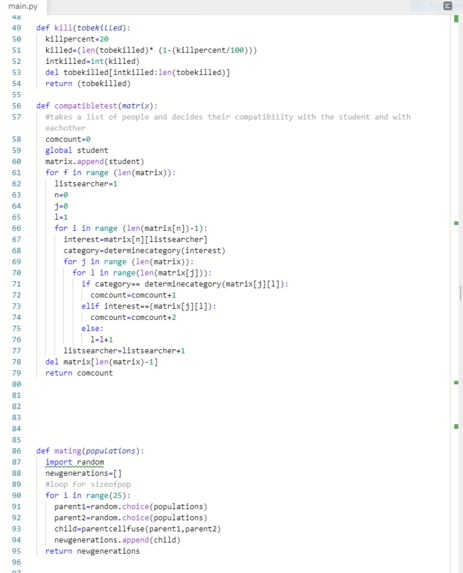
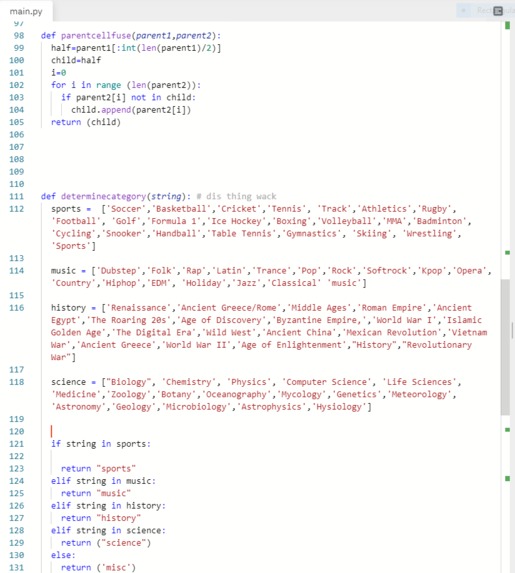
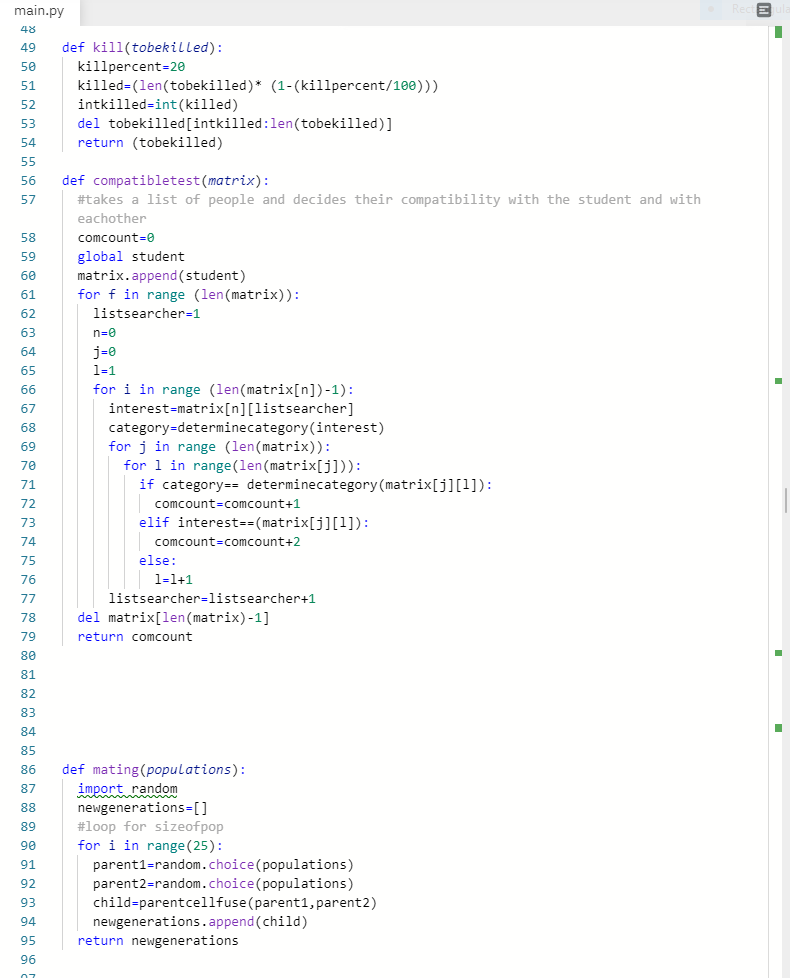
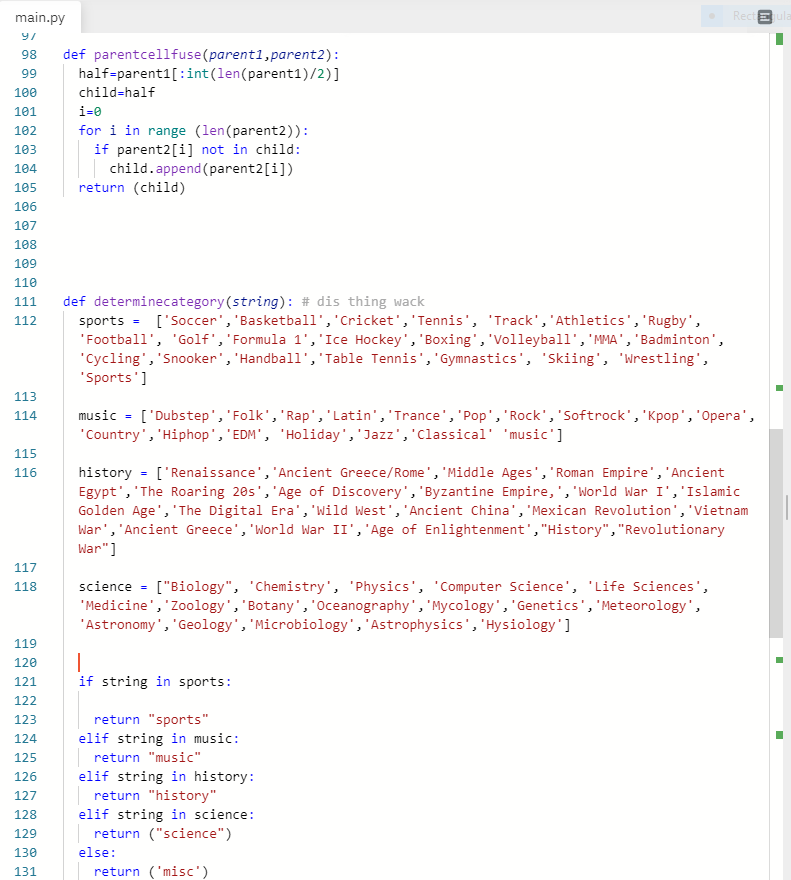
In a key determining factor for our compatibility test, we identified that shared interests between group will better the work dynamic and flow, and make it easier for groups to work together. Therefore, we created several categories regarding academic and extracurricular life. Then, by determining the interests we created a compatibility function which checks whether a group is compatible or not by checking how many similar categories they had. The function also gave “bonus points” to those that had the exact same interests. It is great to have both of these functions, but there needs to be a base function that feeds a large amount of groups into these functions, and also improve the functions over time. We decided to use a genetic algorithm to both feed the compatibility functions a large amount of groups and to improve the group’s compatibility over time. The main determinant for how “fit” a function was to survive, was the size of the compatibility score. Those that had the greatest compatibility score were the most fit, and therefore the most compatible.
Challenges we ran into
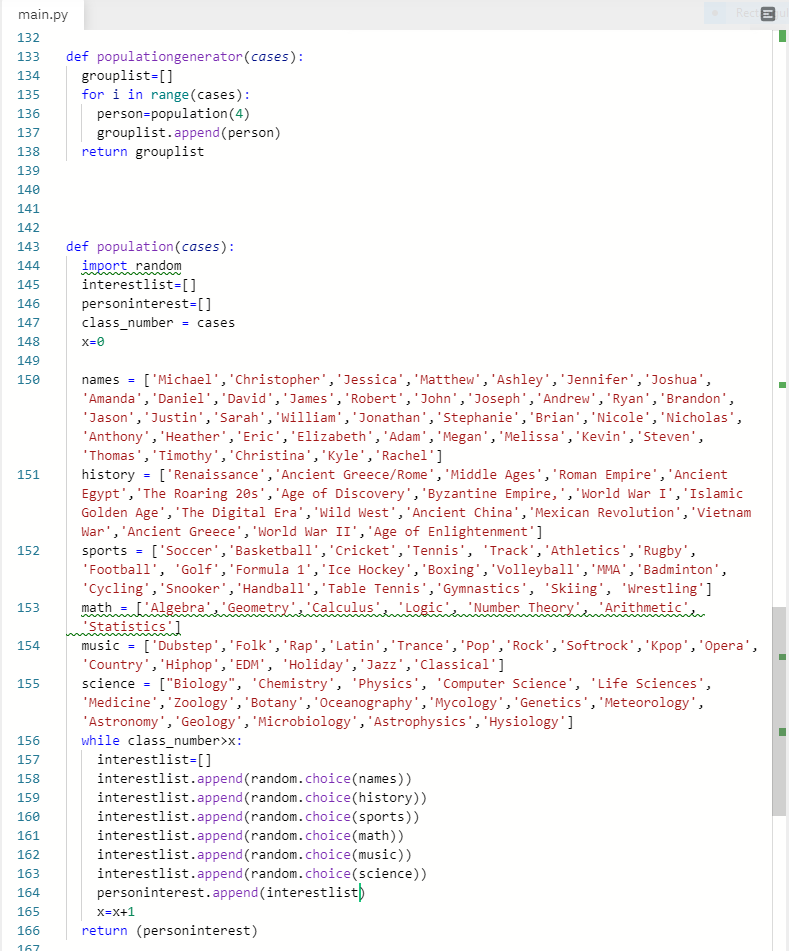
We ran into many challenges on the rough road to success. One of them was creating a program that generates people in a classroom to test the program. This part of the code was bug-ridden and hard to make judging that there were so many interests. Another challenge was to create the genetic algorithm by itself. Though most of our group were comfortable with knowing what a genetic algorithm did, only one of us had written a program using it before, and it was a much more simpler problem than we had now. This was a huge leap for us.
Accomplishments that we're proud of
To determine the success of our algorithm, we made a simple, naïve, shuffle program which shuffles a student into a group. This simulates what educators usually use. Then, we tested this under a compatibility function. Using our genetic algorithm program, we created what the computer saw to be the best fit group in 10 generations. Analyzing both results under a compatibility function, there was a whopping 3686 point difference between our program and a random shuffle program. This means our program could find a group that is about 15 times more compatible than a regular “shuffle” group in less than 30 seconds. This, by far is the best thing that we are proud of.
What we learned
We learned how to more effectively apply a genetic algorithm and make it usable for the future. We also learned how to select out of random lists more optimally.
What's next for Genetic Algorithm for Grouping Students of Similar Interests?
Since we have a generally low amount of categories, we would like to create more sub-categories or more categories. If possible, we would also like to create an AI that processes words and sorts them into categories. This would all optimize the code.
Built With
- python
- tkinter





Log in or sign up for Devpost to join the conversation.