-
-

Pre-trained model metadata being extended with regular expression rules for data validation
-
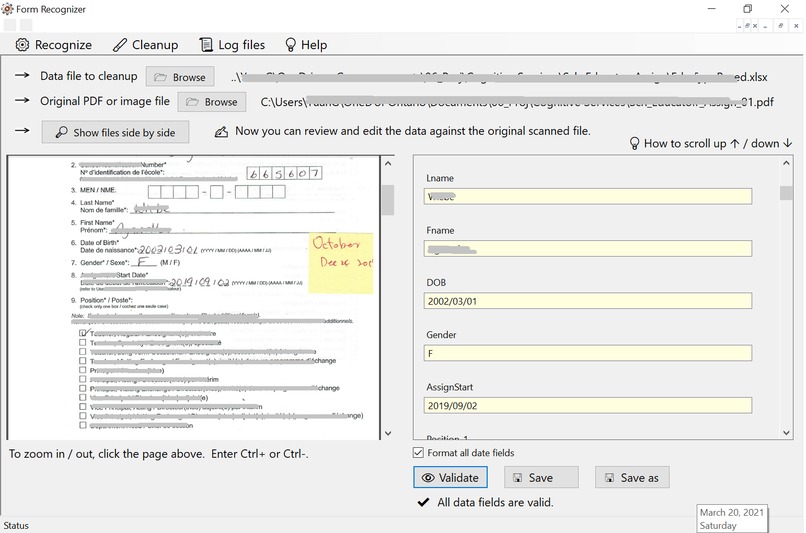
UI to cleanup and validate extracted data

Inspiration
Two questions were raised after a quick demo of Azure Cognitive Service Form Recognizer was given to my client:
- How easily can business users operate the process of using Form Recognizer?
- Can the data extracted from handwritten form PDF by Form Recognizer be more satisfactory?
What it does
My client collects paper forms from rural schools 3 times a year. So far it has been a pure manual process to enter data from paper to computers, validate the data, and import it to data warehouse systems.
My client wants to explore the opportunity of using Form Recognizer to extract key-value pairs from handwritten paper form scanned PDF files. They need an automated solution, so that an average business user can do the job with ease, productivity and quality.
How we built it
I chose to use a WinForm app which I believe is more end user friendly.
For one set of paper form scanned PDF files, I used FOTT labelling tool to define data fields, and generate a custom model. I had 2 observations. (1) Extracted data results by Form Recognizer would display the data fields in a very random order, causing considerable difficulty to the user who would be running the Form Recognizer job; (2) Some extracted data values may not be satisfactory because of the handwritten nature of the original forms.
To overcome these 2 problems, I added an Excel file to contain and extend the metadata from the model. The metadata are in two pieces (1) all the data field names in a "sorted" order (2) Regular expressions (in Json) as rules to validate appropriate date fields.
My WinForm makes requests to Form Recognizer to process multiple PDF files. When extracted data are returned, the 1st piece metadata is used to re-arrange the data field order so that it conforms to the order in the original form. The data results are saved into an Excel file.
The 2nd piece metadata is used to (semi)automate data cleanup and validation against the extracted data. On my WinForm "Cleanup" child form, users click "Validate" button to easily identify invalid data items, check the log files and make corrections accordingly. After validation, the data is saved again, and ready for being imported to other database systems.
Challenges we ran into
The Form Recognizer code samples from Microsoft are mostly for console apps. But for WinForm apps, when a Form Recognizer request is sent to Azure, it is an asynchronous background process, and will no longer communicate with WinForm main process. If the console based sample code is directly applied to my WinForm, the app simply hangs without showing any progress. It was very hard to debug. Fortunately, a WinForm BackgroundWorker object can be used as a delegate to marshal asynchronous tasks with the main WinForm thread.
On BackgroundWorker on-complete event, recursive calls are made to send multiple requests to Form Recognizer, so the WinForm app can handle as many PDF files as the user wishes, without freezing the UI.
Accomplishments that we're proud of
- Once Form Recognizer is fully automated, users of no technical background can use my tool with ease, productivity and quality.
- Post data extract validation is also (semi)automated to enhance the value of Form Recognizer.
- Good scalability for large number of PDF files, thanks to BackgroundWorker processes in handling the asynchronous tasks.
What we learned
It's important to understand the strength and weakness of a tool, and come up with our own ideas and approaches to overcome the weakness.
My project might take shorter time to finish if I didn't work alone. I wish I can team up with others next time, so that we can leverage each other's skills, and deliver the project faster and even better.
What's next for Form Recognizer Automated
For current version of Form Recognizer (version 3.1.0 beta.1), extracted data value from a checkbox field may occasionally be a random value as opposed to Selected-Unselected. I hope this will not occur with Microsoft next version of Form Recognizer.
Built With
- api
- azure
- c#
- cognitive
- expression
- regular
- visual-studio

Log in or sign up for Devpost to join the conversation.