
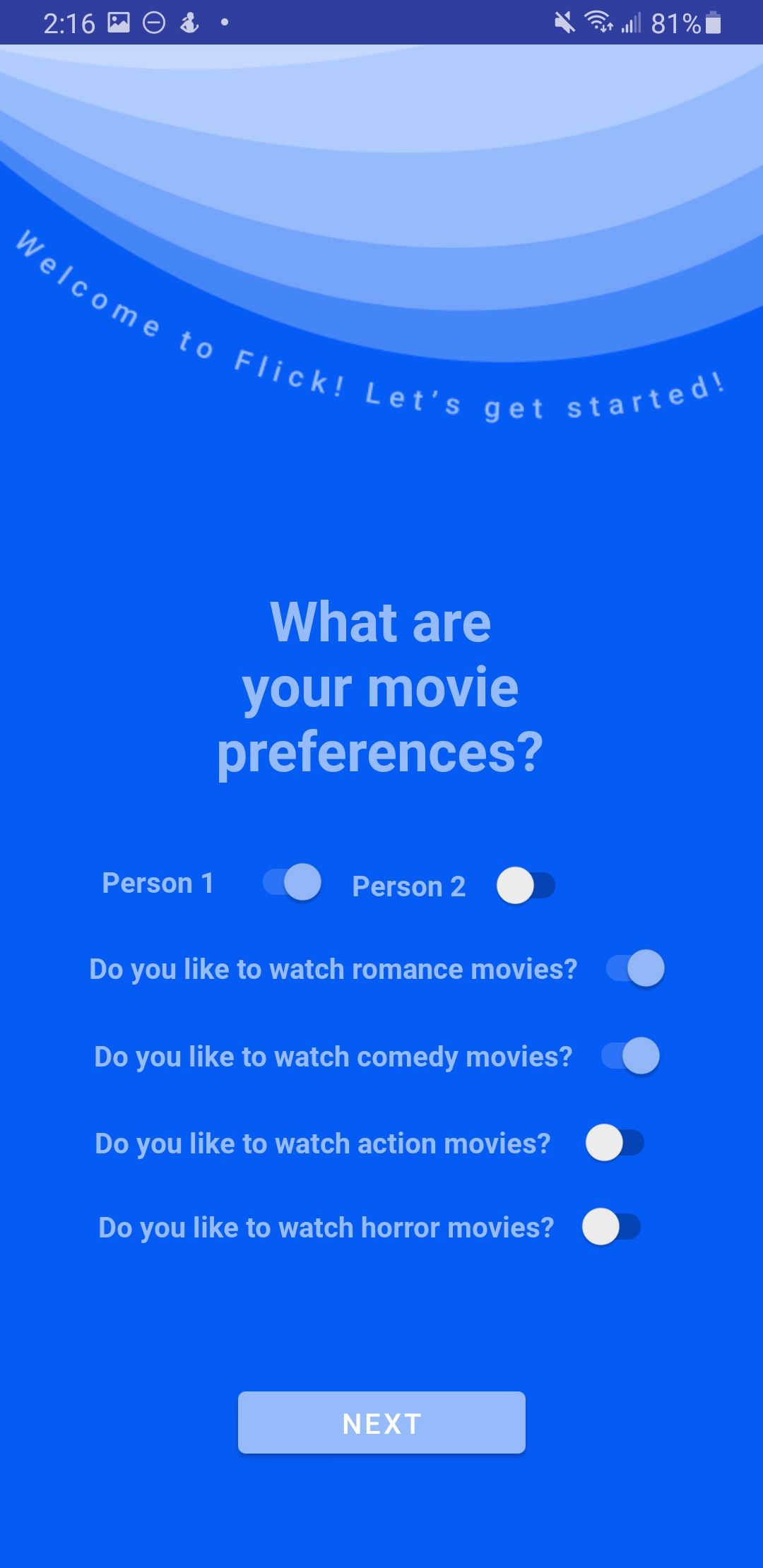


Inspiration
So often, each of us have the universal human experiences of struggling to agree. This experience manifests itself in many ways, but almost any time a group is involved, it is difficult to make everyone happy. We chose to zone in on one manifestation of this issue - picking a movie to watch, but a solution to this specific problem is a footstep forward in solving the grander issue of consistent and fair compromise.
We took a page out of the book of dating apps because the swipe action is frankly the quickest and easiest way to give at-a-glance feedback, but these apps have major issues. For one thing, they require you to swipe for ages to find someone that you're actually interested in. To prevent this same issue from cropping up in our solution, we introduced machine learning.
The idea was that a model would learn from the swiping activity of each member of the group and curate the recommendations accordingly - that is, each subsequent recommendation is powered by the last swipe [and all prior swipes] and brings you closer and closer to a central point in between everyone's interests.
What it does
Flick is an Android app that uses ML to suggest movies that are closer and closer to something everyone in a group will be happy watching. Friends that want to find a movie join a group account and enter their individual profiles and preferences (general conditions like if they want the movie to be rated at least 6/10 on IMDB or they want to exclude rated R movies). Next, the application retrieves a random movie within everyone's constraints and displays it to each user. Based on their swipes, it runs an algorithm optimizing the satisfaction of everyone in the group, and it uses this algorithm to choose the next movie to recommend. As they swipe, they're teaching the machine what precisely interests each of them in a movie, so the machine is able to more and more precisely compute the most interesting movie to all. The process ends when everyone swipes right on the same flick, indicating that the machine has zoned in on a movie that meets everyone's criteria and piques everyone's interest.
How we built it
Initially, to gather our data, we used a public dataset of IMDB ids that we read out of a CSV using a Python script and made requests to an IMDB API that returned information about the film. We reformatted all this data into a JSON file.
With Android Studio we were able to build the front-end of the app in Java. In order to display GET requests from the Python Flask for every card representing a movie, we created a card and card adapter. We then used an HTTP framework after the initial swiping to make a POST request to a backend endpoint we have built with Flask in Python. If all users swipe right on the same movie, it stops the users from swiping to alert them that they have matched on a movie. As for the UX/UI of the app, we used a simple UI design to create an interactive interface that is responsive to all intents and actions of the user. This way, we could create a very intuitive experience for the user while also being able to easily parse the user's initial movie interests as well as their then tailored recommendations according to their friend's interests as well.
On starting up, the Flask application connects to our Cockroach DB Cloud Cluster (hosted on Google Cloud Platform) and runs a dynamic SQL UPSERT function by iterating over all the data in the JSON file mentioned earlier. It also opens routes to access a starter point movie and to access the next recommendation based on prior swipes. These routes run SQL SELECT queries using user-specified conditions to identify appropriate sample data, and in the second case, this data is passed to our Python recommend function. This function runs a custom ML algorithm that evaluates genre similarity and synopsis similarity as well as the cosine between the multidimensional quantitative feature vectors to narrow down the perfect match. Finally, the function (and in turn the Flask route) returns the next movie to be recommended to the user.
Challenges we ran into
Our original plan was to allow the user to set the streaming services that they own so they would only get suggestions for movies available on those platforms. This was completely viable, but the issue was that every API with this feature either had too low of a monthly request limit or required paid access, so unfortunately we had to do away with this feature, and it would be something that would be implemented as the application was scaled to a wider audience and could support costs.
Setting up Cockroach DB connections through Flask was also very tricky because it was our first time working with the service. For example, we did not know that the connection should be initialized before starting up the application, and we were doing so in one of the routes, which was invalid. This took quite a while to debug, even though it was such a simple fix.
Another problem we ran into was that the data, especially movie titles and descriptions, contained apostrophes that clashed with the apostrophe wrappers of the elements in the value of the SQL command. We were very confused when the problem occurred because we couldn't identify why only some movies were throwing errors when UPSERT was called on them and tried to debug it for over an hour before contacting a mentor. His fresh pair of eyes was able to spot the apostrophes within the title and description, and we quickly came up with the solution of using the .replace function to change these apostrophes to a special code that we could decrypt on the frontend.
On the frontend side, we had major trouble when we initially were attempting to make GET and POST HTTP requests from the Android application. We tried multiple request frameworks and none of them worked, so we reached out to a mentor that sent some relevant documentation. This led us down the right path to discovering that one of our methods was correct, but one of the tools we used in that method had been deprecated and replaced, so once we replaced this, we were able to make requests smoothly from the Android app.
Accomplishments that we're proud of
We're really happy to have gotten the swiping mechanism working so quickly, and we're very pleased with how clean and pretty the UI came out. What we're most proud of on the Android application side, perhaps because it was the newest and most difficult to tackle part of that end of the project, was making HTTP GET and POST requests from the application itself and calling these functions whenever the user took action. Without this part working, there would no way to supply movies to the frontend, and the whole point of the app interacting with a backend model would be lost.
We're also very proud of setting up the Cockroach DB Cloud Cluster, since it was our first time working with that technology. We also had no SQL experience, so writing up the queries, running them through the Python script, and watching the table update were some of the most satisfying parts of the project. Furthermore, we're very happy with the success of the ML algorithm at generally pointing users toward movies that were more fitting for their whole group.
What we learned
One of the members (Rishabh) had no knowledge of Python going into the project, and he had to work on setting up a Flask application to connect with Cockroach DB, which he also had no experience with, so it was a huge learning curve for him. He had to learn 2 new languages: Python and SQL, and he had to figure out to build a web application using the Flask framework. Though on the whole, he was very inexperienced when it came to backend work at the beginning of the hackathon, he feels much more confident now that he has been able to set up this functional backend interfacing between two technologies that were previously foreign to him.
Arnav, who worked on the machine learning part of the project, helped Rishabh with Python and SQL, and showed him how to create routes and process requests in Flask, also learned some significant things despite having worked with machine learning in the past. Because this system could not rely on the typical idea of supervised regression or classification, he had to do a lot of research to find the best way for an ML algorithm to draw conclusions from the data on-hand. Ultimately, he had to design and implement a multi-step algorithm curated to the data that dissected SQL query returns and performed genre analysis followed by semantic similarity analysis on synopses and ended with optimizing cosine vector similarities for the quantitative features. As this was Arnav's first time working with data like synopses in generating an ML model, that part was a learning experience as well.
Vennela has been working on developing the front end of the Android Studio application in Java and implementing the GET and POST request-related functionality. This was a learning curve for her when it came down to using okhttp3, but the hackathon allowed her to explore new technologies like Postman to learn how to use it to do http requests. Vennela is also proficent in developing Java UX/UI, so she created the movie cards and implemented the swiping feature. To do this, however, she had to use supporting APIs with she read more on to apply in the project. Vennela also used animations from Lottie. This technology enabled her to animate the corresponding page, which she again explored through mentor suggestions and additional research
What's next for Flick!
One thing we want to add, as mentioned earlier, is the ability to choose what streaming services you have access to, so results would be tailored to exclude any movies not available on those streaming services. We were fully capable of implementing this: the only problem was the fee associated with the API. On the same thread, we want to add a feature that allows you to click on a link for each movie card to go directly to the streaming service (and perhaps even open something like a Netflix Party for your whole group).
Built With
- android-studio
- cockroach
- cockroach-db
- flask
- java
- python
- sklearn
- sql











Log in or sign up for Devpost to join the conversation.