-
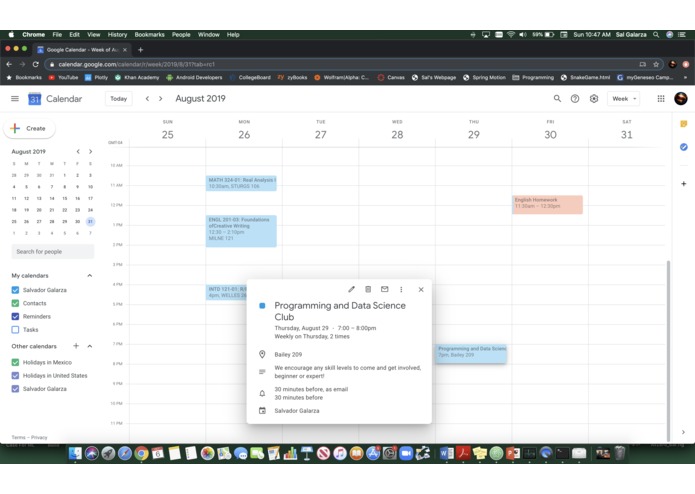
Programming and Data Science Club Event
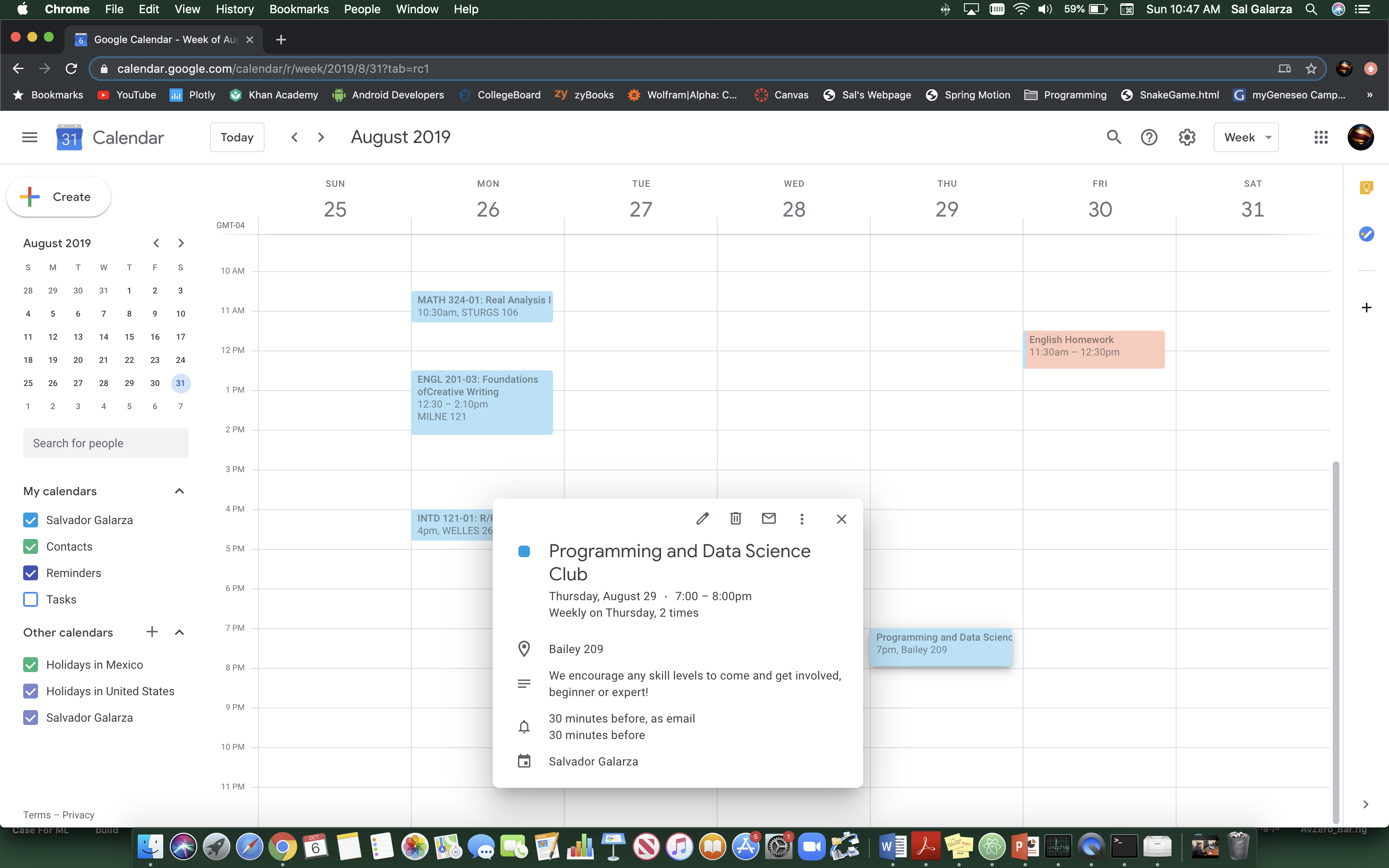
Inspiration
The main inspiration behind this project was the idea to translate information between senses to help people who might be impaired of any. In specific, the idea behind our application is for it to translate visual information to auditory information and for the user to solely use their voice to interact with the gathered information.
What it does
EventVision reads aloud the contents of a detected poster in the cameras sight to someone who is visually impaired and could otherwise not read it themselves. If our application detects an event mentioned on the poster it then extracts the data required to schedule an event on Google Calendar. EventVision also detects if the user has any time conflicts with the event, including if the event is already on their calendar, and asks them to confirm whether they want to add the event. If the user responds in the affirmative, the Google Calendar event is then added to their calendar. All of the reading and prompts are text-to-speech or speech-to-text, meaning the user does not need to interact with the program in any other than their voice.
How we built it
EventVision was made with Python and various Google Cloud APIs.
The text extraction of the poster from live video was made with Python and utilized Google Clouds Video Intelligence to obtain all relevant content. From this live video, EventVision extracts all the text on the poster and uses Googles Text to Speech API to read aloud all content found on the detected poster. At the same time EventVision also solely extracts the relevant information to make a Google Calendar event such as, Title, Time, Location, and Description, and Recurrence.
The Video Intelligence API reads the poster and stores the relevant Google Calendar information it gathered inside of a JSON file. This JSON is then sent through the Python script to the Google Calendar API.
Here the event on the poster is validated against existing events in the users calendar and EventVision uses the Text-to-Speech API to ask the user if they would like to add the event. If the user approves the event, then the event is added to the users Google Calendar.
We used the Text-to-Speech API to create our own Voice Assistant to schedule the event extracted from the video. This worked by reading off prompts for the user to add the event, and approve adding an event despite a time overlap, and to notify the user that the event had been added successfully. The Speech-to-Text API took the users response for approving the event and sent it to the script for validation.
Challenges we ran into
*Using the Google Cloud APIs for the first time was pretty confusing to get up and running, we definitely learned a lot as time went on.
Creating our own Voice Assistant was the most challenging part of this project. We had a hard time integrating the Speech-to-Text API into the program at first. The APIs were all a bit of a challenge to work with at first as we hadn’t used them before, but Speech-to-Text proved to be the most challenging. Getting the Video Intelligence API to create the values needed for the event JSON was also somewhat of a problem as was figuring out how to validate overlapping events properly. Successfully parsing through the poster text to obtain solely the relevant data to create an event was a challenge and a great success.
Accomplishments that we're proud of
Successfully creating and integrating our own Voice Assistant using the Speech-to-Text API was very rewarding. We also managed integrate our phone camera into project, this allowed us to scan posters live more easily and at higher quality than with our computer webcams. Successfully parsing through the poster text to obtain all relevant data to create an event was a challenge and a great success. Integrating the Speech-to-Text API was challenging but very satisfying when it finally worked the way we intended. Getting the Calendar API to work well with this project was also a notable achievement.
What we learned
Working with APIs is a lot of work but a lot of fun. Once reading in posters and accepting user voice input gets involved, things get far more difficult. We learned a lot about using APIs to take in various inputs, whether it be images or voice, and converting that to text usable by the computer.
What's next for EventVision
We plan on training a machine learning model on how to better recognize and read posters, we where unable to do this here due to a lack of accessible posters to use for training and time to train the model successfully.
We have very ambitious ideas for EventVision, we believe that with the right hardware and implementation of machine learning we can make a real product that could make the world a better place for those who are visually impaired. We envision to begin training our model so that anyone anywhere can hear a poster and tell their phone to schedule an event.
Built With
- google-calendar-api
- googlecloudspeechtotext
- googlecloudtexttospeech
- googlecloudvideointelligence
- python



Log in or sign up for Devpost to join the conversation.