-
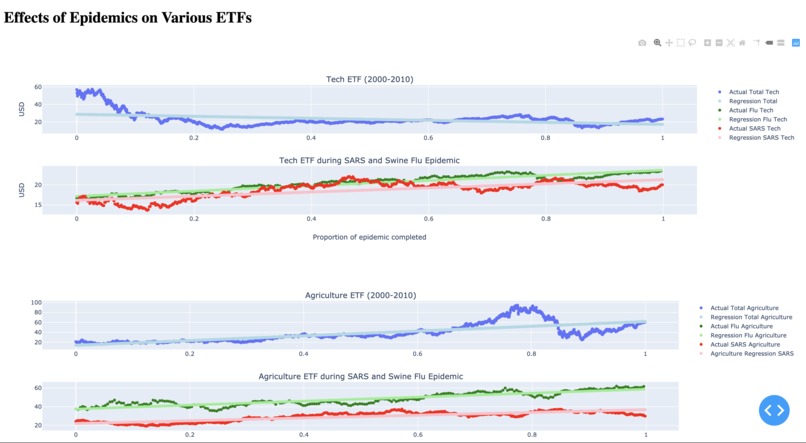
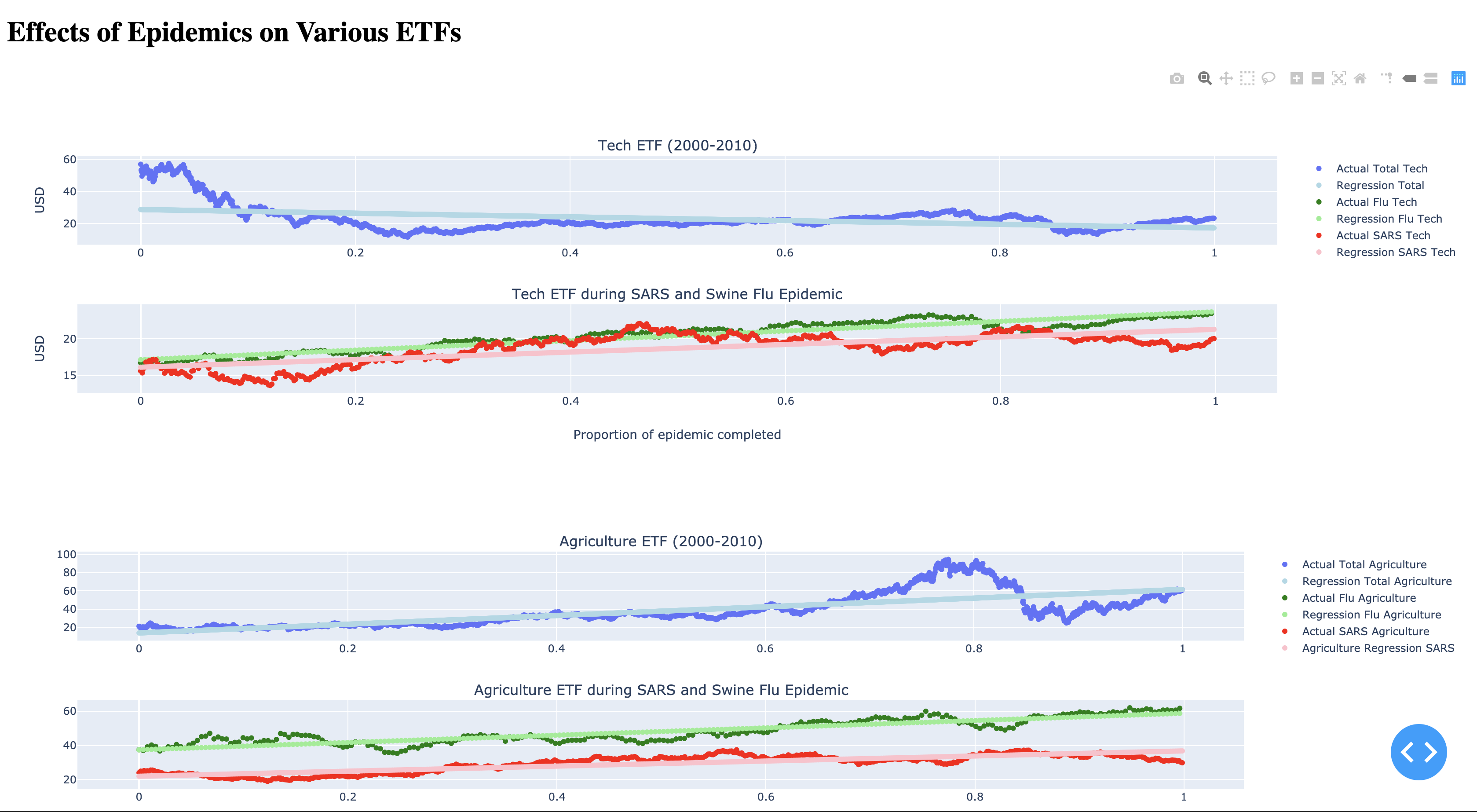
Plotly Web app: ETF visualization via plotly/matplotlib
-
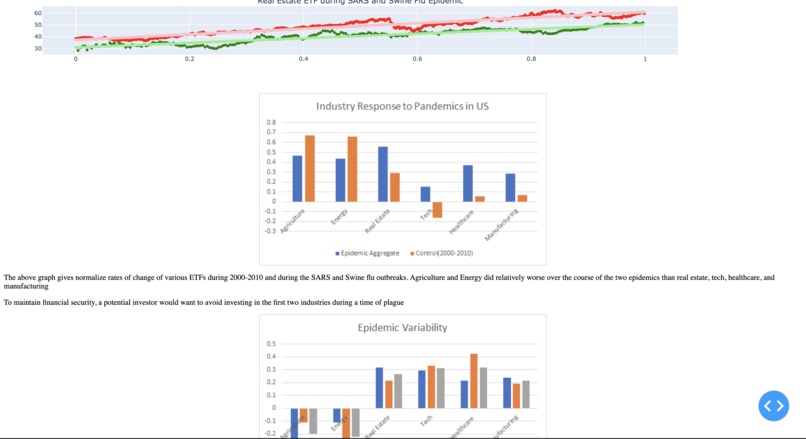
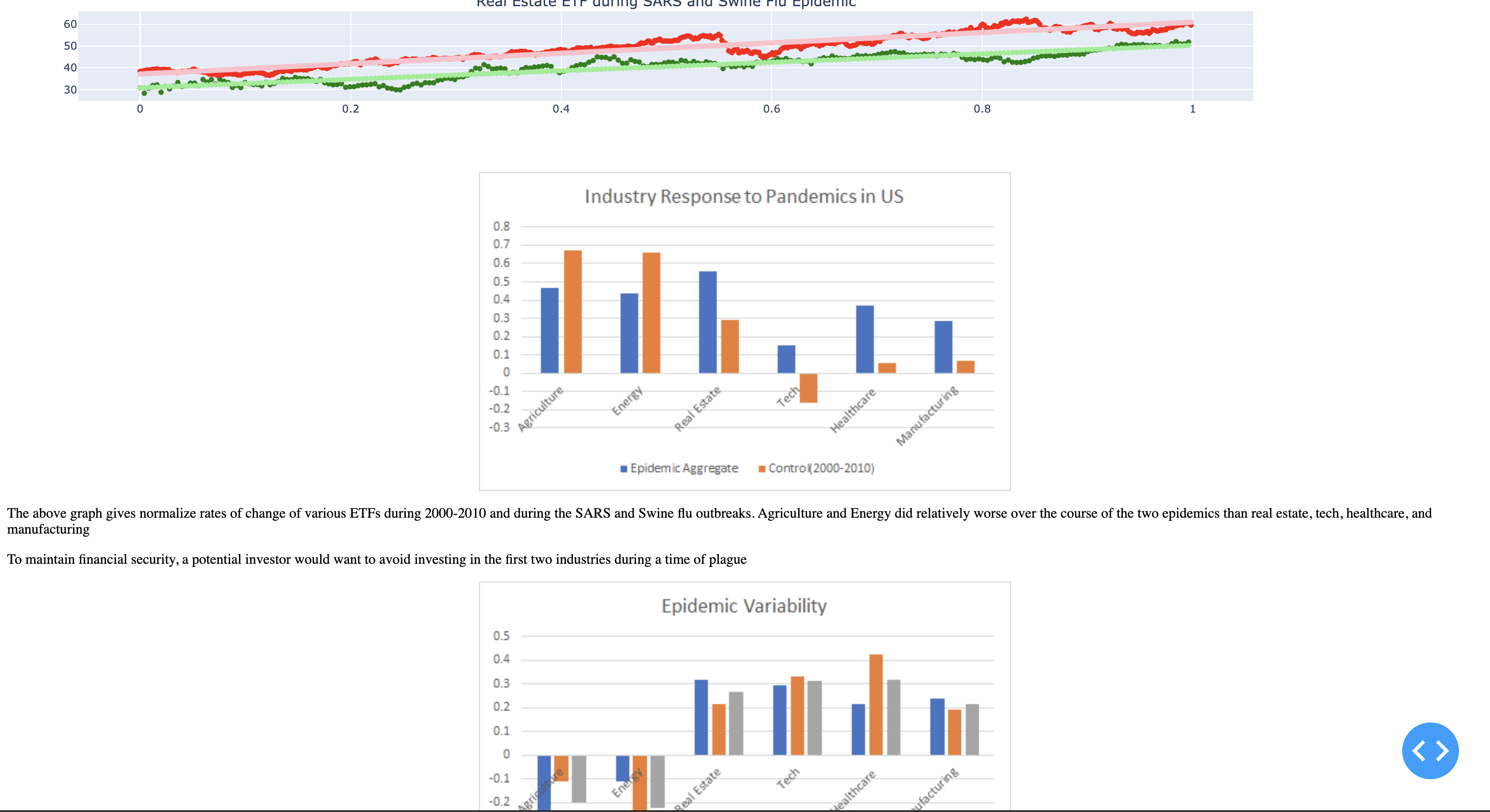
Plotly Web app: excel visualization comparing rates of growth, conclusions
Inspiration
With the recent emergence of coronavirus, we wanted to understand the impact previous epidemics (such as SARS and swine flu) have had on the economy, including the stock market. We wished to see to what degree each industry was affected by epidemics. In simple terms, we wanted to see what industry to invest in during an epidemic. Through our findings, we hope to better educate the public about making smart financial decisions during an period of disease.
What it does
Our project takes closing prices of various ETFs corresponding to various industries, plotting them over the course of the SARS and swine flu epidemic time periods. ETFs is an index fund that can be used as a metric to gauge relative performance of industries in the economy. We stored the relevant json and csv files pertaining to the ETF's on a database in mongoDB. We used linear regression with the sklearn library in Python to determine a line of best fit to obtain an average rate of change of ETFs over the course of the epidemics. We also computed the average change of the ETF's during time period 2000 to 2010 as a control. These slopes were then normalized to be able to make simple comparisons of which ETFs grew more/less than expected.
How we built it
We used pandas to read and organize data from csvs of closing prices of industry-specific ETFs. MongoDB was used to store the CSV and JSON data pertaining to the ETFs. We then used sci-kit learn to perform linear regression on the data to obtain the rates of change of the ETFs. Next, we used the sklearn library to normalize these values so that the rates of changes could be compared across epidemics. These visualizations were made via matplotlib, plotly, and MS Excel, and these visualizations were displayed via a plotly dash based web application.
Challenges we ran into
The sheer amount of data we needed, the statistical analysis we needed to compare rates of change, and the direction we would take to create conclusions from the data we obtained. We wanted to find a way to compare the performance of certain industries across the different epidemics (time periods). Because market conditions were different at the start of the different epidemics, we had to figure out the best way to normalize the data. This required a rigorous cost-benefit analysis of the various normalization techniques. There were roughly 144,000 rows of data so the high processing time was an issue. MongoDB helped to smooth working with the data. We also had no prior experience with HMTL and front-end development in general, so creating a local server to host our visualizations on a website was a definite challenge.
Accomplishments that we're proud of
In general, we only had basic Python and Java experience coming into Hacklytics 2020. We learned many technologies on the spot, including sklearn, matplotlib, MongoDB, plotly, and various other concepts. However, we are most proud of changing the world with our project Using sklearn to be able to conduct the appropriate analysis to come to insightful conclusions and being able to host these visualizations on a local web page was the most impactful of what we learned.
What we learned
Linear regression and normalization techniques in sklearn Data visualization in plotly Web application hosting via plotly dash Hosting data on MongoDB
What's next for Epidemic Economic Impact
Cloud hosted web app, using data from previous epidemics to predict how ETF growth will change due to the current coronavirus epidemic, obtaining more data on specific companies rather than ETFS for more specific investment advice. Implement machine learning algorithms to predict future data.



Log in or sign up for Devpost to join the conversation.