-
Overview/ Landing page
-
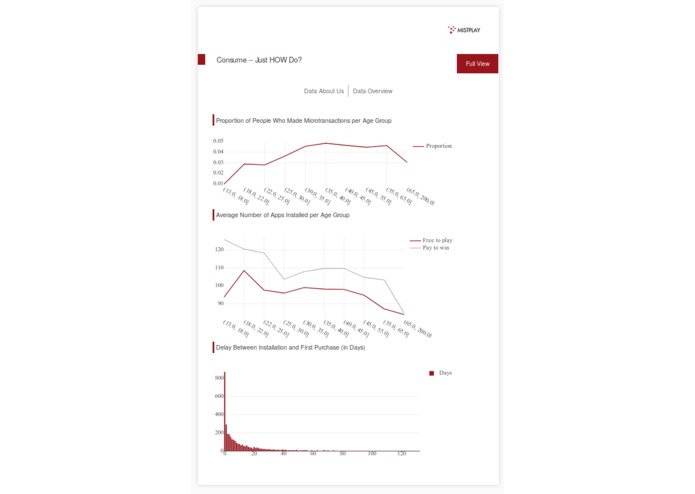
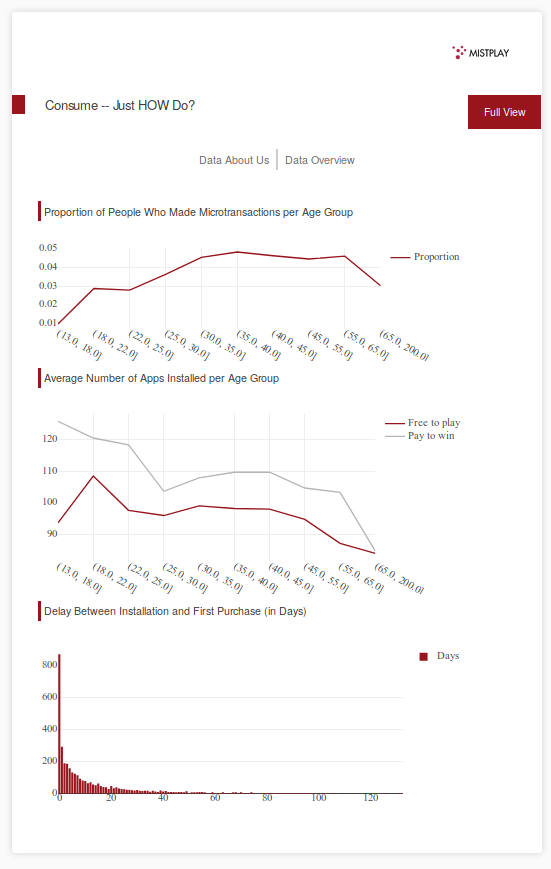
Interactive dashboard
-
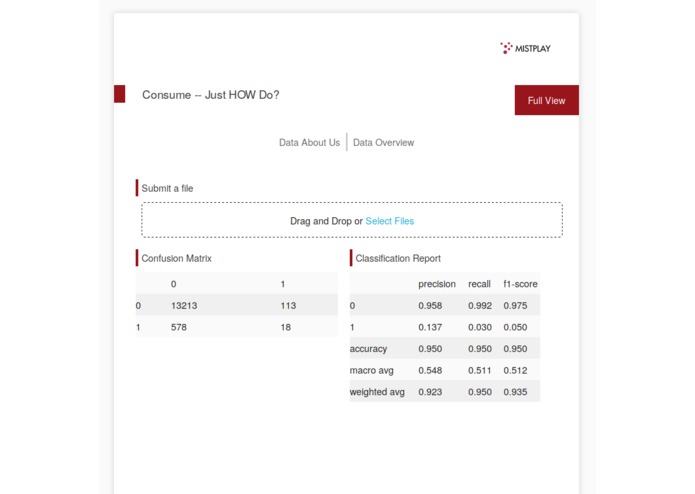
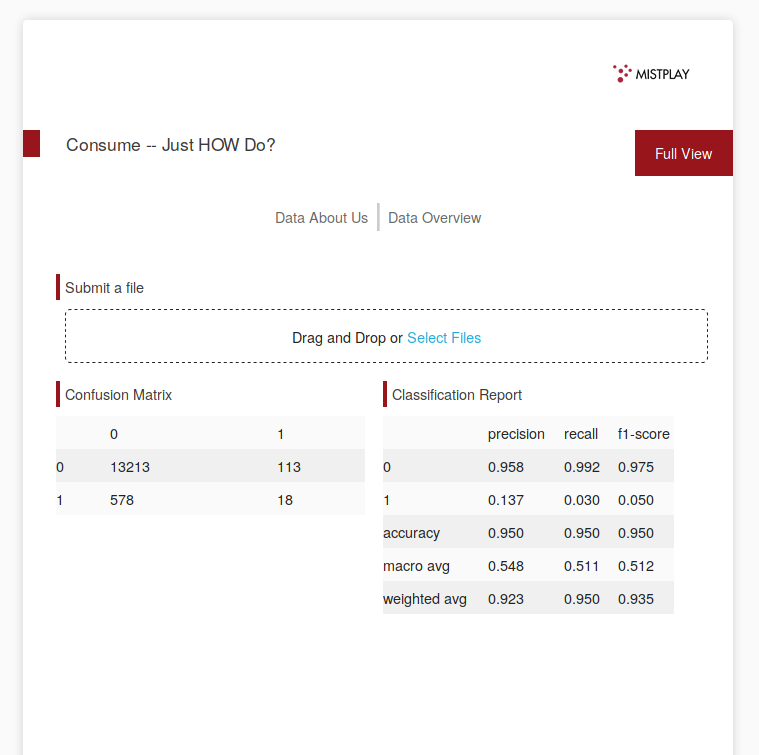
Submission page with model metrics
Inspiration
We were inspired by the use of big data in consumer advertisements. Companies use usage data to identify their consumer base and in particular for mobile gaming, customers that are more likely to spend on games in a market where many games are freemium. We seek to visualize data to make it easier to identify demographics and personality types that are more receptacle to supporting the games they play.
What it does
Our website takes a csv of various demographic and app purchasing data, attempts an analysis of the data through predicting which customers are likely to make in app purchases and displays the given data in a variety of graphs.
How we built it
The frontend and graphs are displayed using plotly via dash, and the backend uses a random forest model to predict labels. We used scikit-learn and keras to make the models we trained on, as well as Google Colab to train our models on their GPUs.
Challenges we ran into
The data was not very in depth, and the machine learning models we used had difficulty with correct predictions. Our best model was a deep neural net made using keras, which had a top f1-score of 0.09 against the validation set. Our team had never used plotly, and the idea of callback was especially foreign, so we had to learn during this past weekend. We considered on occasions to use redis and Celery to communicate between the front and back end, but had to settle on a simpler and less sophisticated approach in order to meet the submission deadline. There were missing parameters in the data, that we filled in using Naive Bayes. The data was also extremely unbalanced -- only 5% of gathered users had spent on the apps. We used SMOTE to expand the data and give a more balanced class set, but this approach made the model predict many false positives.
Accomplishments that we're proud of
We trained many data models, and learned many how many different models worked, as well as the effect of tweaking hyperparameters on the models. We're extremely proud of the plots and design on our website.
What's next for Consume -- just HOW do?
We used a random forest model for the predictions, but the deep neural net had slightly better performance. We had also tried out so many models that allowing a selection of different models to use would be our next step. There's also much more graphs we could create if we had more time to analyze the data and identify the more useful parameters.








Log in or sign up for Devpost to join the conversation.