-
-

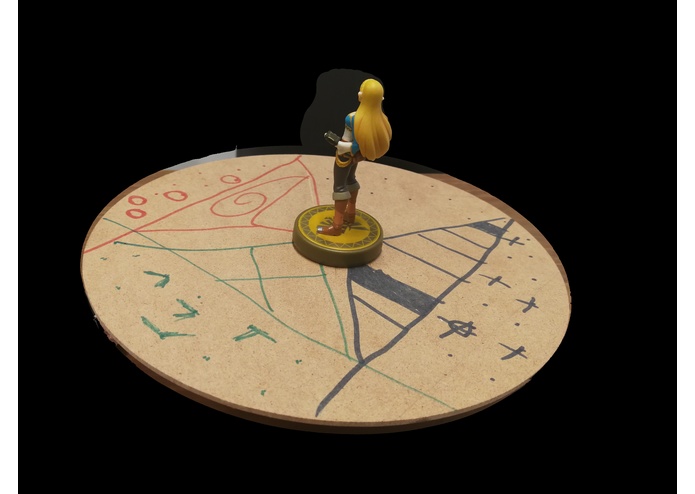
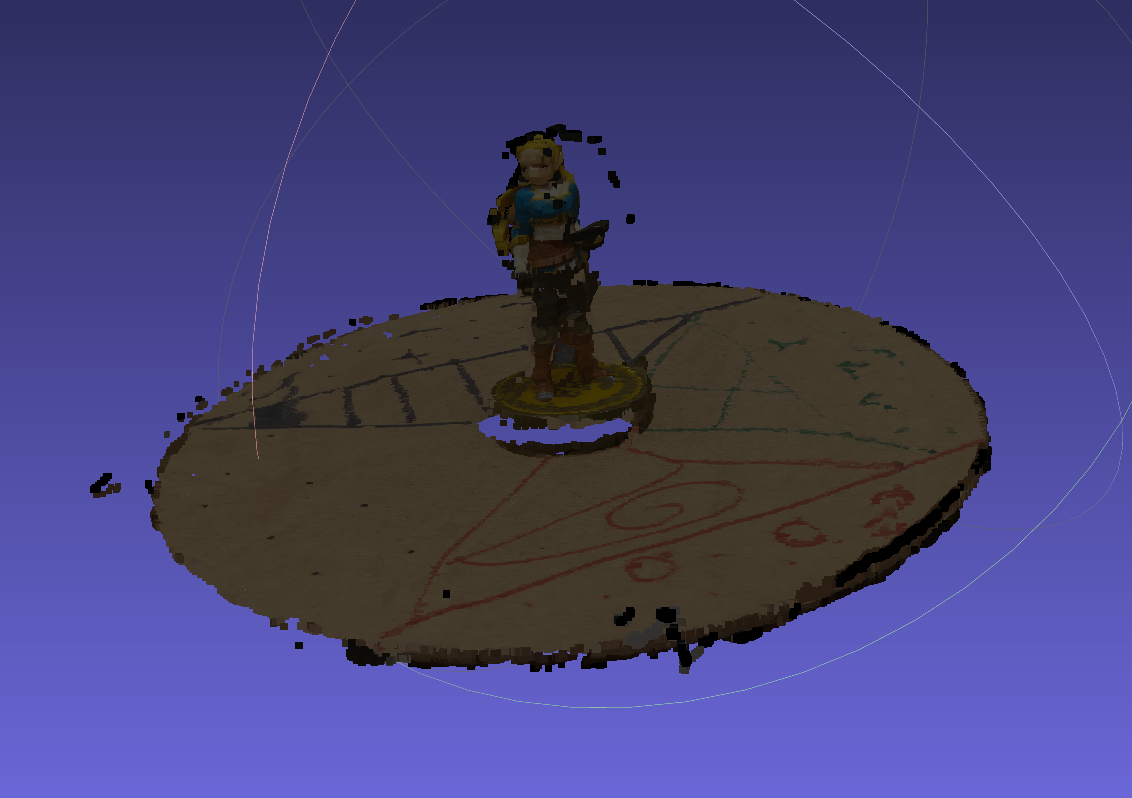
3D scan result
-

3D scan result
-

Platform with Aduino
-

Stand
-
Masked sample input
-

Sample input
-

Sparse point cloud
-

3D model without textures
-

Dense point cloud








Product description
With the increasing graphical computational power, there are more interactions between real life and the digitised world built by machines. The world has experienced this through the introduction of AR & VR, 3D printing, video games, all of which bridge real life with a virtual environment. However, the creation of 3D models act as an obstable, which is often expensive and time comsuming (requiring years of experience and expensive working environment), preventing everyday users participating directly in the creation process of the above activities.
However, during this hackathon we have proposed a complete and automated pipeline for 3D scanning. Contrary to most commercial solutions, which often require multiple depth cameras and/or lasers, our solution only needs one camera (the prototyped used a cellphone camear). This greatly reduced the cost of the pipeline. Furthermore, their software components are often covoluted and lack documentation, as they are designed for technical purposes. However, we have automated this process, and the model is automatically constructed with a click of a button. The only required user input is placement of the camera at our designated position.
Combining the above 2 factors, we have made 3D scanning accessible to a wider audience. This can may be integrated in existing 3D model creation workflows to increase the speed of prototyping. Alternatively, small museums may use this technology to digitise art with a greatly reduced expense. Individuals who desperatly need to replace a niche broken part may no longer need to waste time searching for it; they can simply scan it and 3D print it. The advantages this bring is immeasurable, and we are proud to showcase our solution today.
How to use it
A rotating platform with a designated calibration pattern is setup, and a camera (phone) is placed on a fixed stand. The position of the stand is adjusted such that the entire platform is in the field of view. The web frontend is loaded up, and a calibration image is automatically taken with a click of a button. If satisfied, the object is placed in the center of the platform, and another button is pressed to begin the process. Depending on the object, it may take up to 10 minutes to create the model. However, the user is constanting updated, with photoes or models constantly updating to reflect the current progress. At the end, a .obj file is created, which can be imported into 3D design softwares for further refinement.
How it works
Hardware
Rotating platform and stand: wood, pins, and the occasional glue to stabilise the structure; the platform is connected to a step motor, which is connected to the driver board and an aduino. The aduino is connected to the computer and loaded with a custom firmware for data transfer and control. On the rotating platform, a calibration image is drawn. It is designed to be non-symmetric, different colors, and have a high contrast with the background. This allows easy identification later.
Camera: An android phone is used as the camera. It is connected to the computer with debugging mode enabled, allowing fulling control over the phone using adb.
When the scan begins, the platform is rotated 360/n degrees each time, where n is the number of photos required. The photos are received by sending an unlocking command to the phone, opening the camera app, focusing it to to the middle of the field of view, taking a photo, and finally transfering it to the working directory on the computer for further processing.
Image processing
Each photo taken is compared to the reference image, and the difference mask is taken. The mask for all the images are added together and the contour with the largest area is taken. This is assumed to be the outline of the platform + object. The contour is then filled in to create a mask. The mask is then applied to all the images, as it can filter out a lot of background, which may influence results downsteam and increase computation complexity.
With the image preprocessed, it is then processed. Features from images were first extracted, and images were matched to see find overlaps in features. This allows creation of a sparse point cloud using the algorithm from the 2013 paper "Global Fusion of Relative Motionsfor Robust, Accurate and Scalable Structure from Motion" from Moulon et al. The sparse point cloud can then be used to created a mesh, which is then textured using the images. This algorithm is known for a long time and widely used.
Fortunately, there exists implementations of the above algorithms, and we used the libraries openMVG and openMVS library. openMVG is used to create a sparse point cloud, and openMVS converts a sparse point cloud into a 3D mesh. As both these pipelines are independent from each other, a bridging program was written.
However, we modified openMVG as it was not suitable for our use case. OpenMVG was designed for scanning large historical buildings, and lacked the the resolution for small objects. We modified the library to increase resolution with the comprimise of noise. Furthremore, their solution involved rotation of the viewer rather than the object. Thus, the program was modified to reduce the effect of it. The functions in the library required many different parameters, and we calculated the best value for our use case.
The resultant file was a custom .mvs file, and we converted it to the more universal .obj format for easier further processing and portability. This concludes the back-end component of the processing. During the entire back-end computation process, data at each stage is transfered to the front end using websockets to update the users the current progress.
Front-end
The intuitive front-end UI is powered by React and @Material-UI and WebSocket is used to communicate with the backend. It is elegantly designed to display all the intermediate steps so that user don't need to deal with annoying command lines. User will first need to capture a reference image by clicking a button. This reference image can be retaken if desired. Then it will display all the image while they are being captured. Then all sorts of fancy processing will take place and there will be comments displayed on the right. Finally, once all computations are complete, the model is rendered using OpenGL and the user can view and interact with the model in real-time.
Log in or sign up for Devpost to join the conversation.