-
description
-

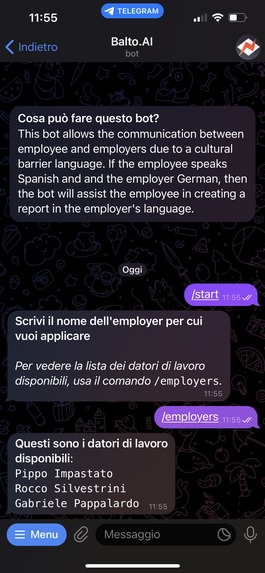
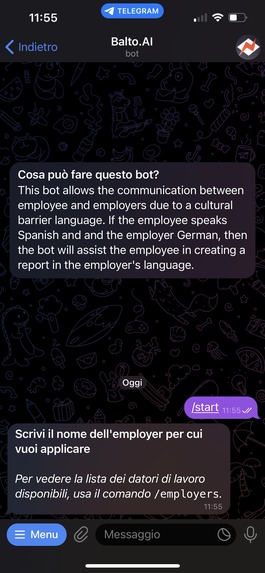
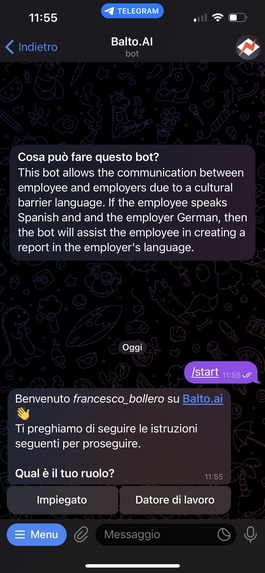
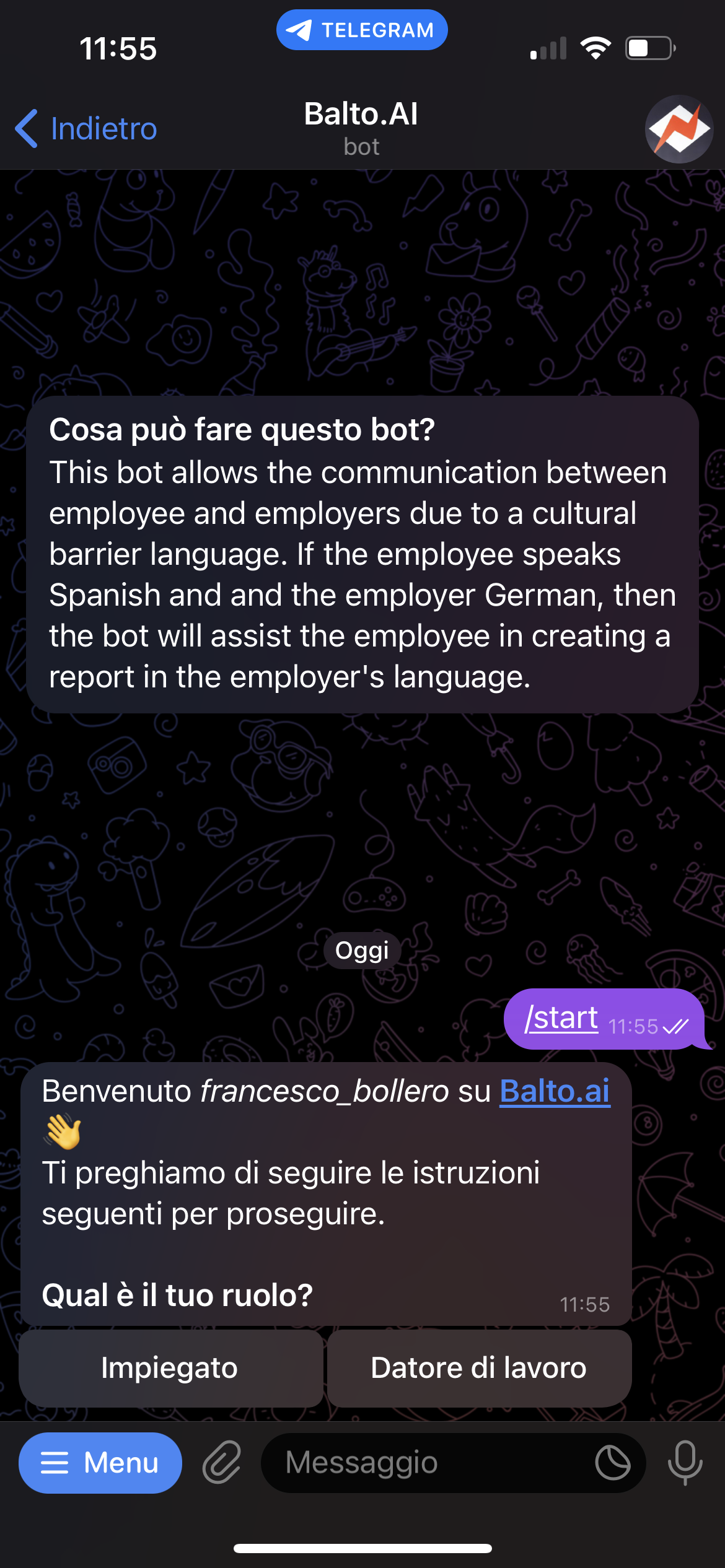
start interface
-
interaction1
-
interaction2
-
-

-
-
-



Inspiration
As foreigners in Germany, the language barrier is an everyday challenge we have to face. That is the reason why, when we heard the problem statement by Knowron, we decided to go for it. We think technology and AI should be helpful for all of us, and this solution we developed makes the integration of foreigners in a new society way easier.
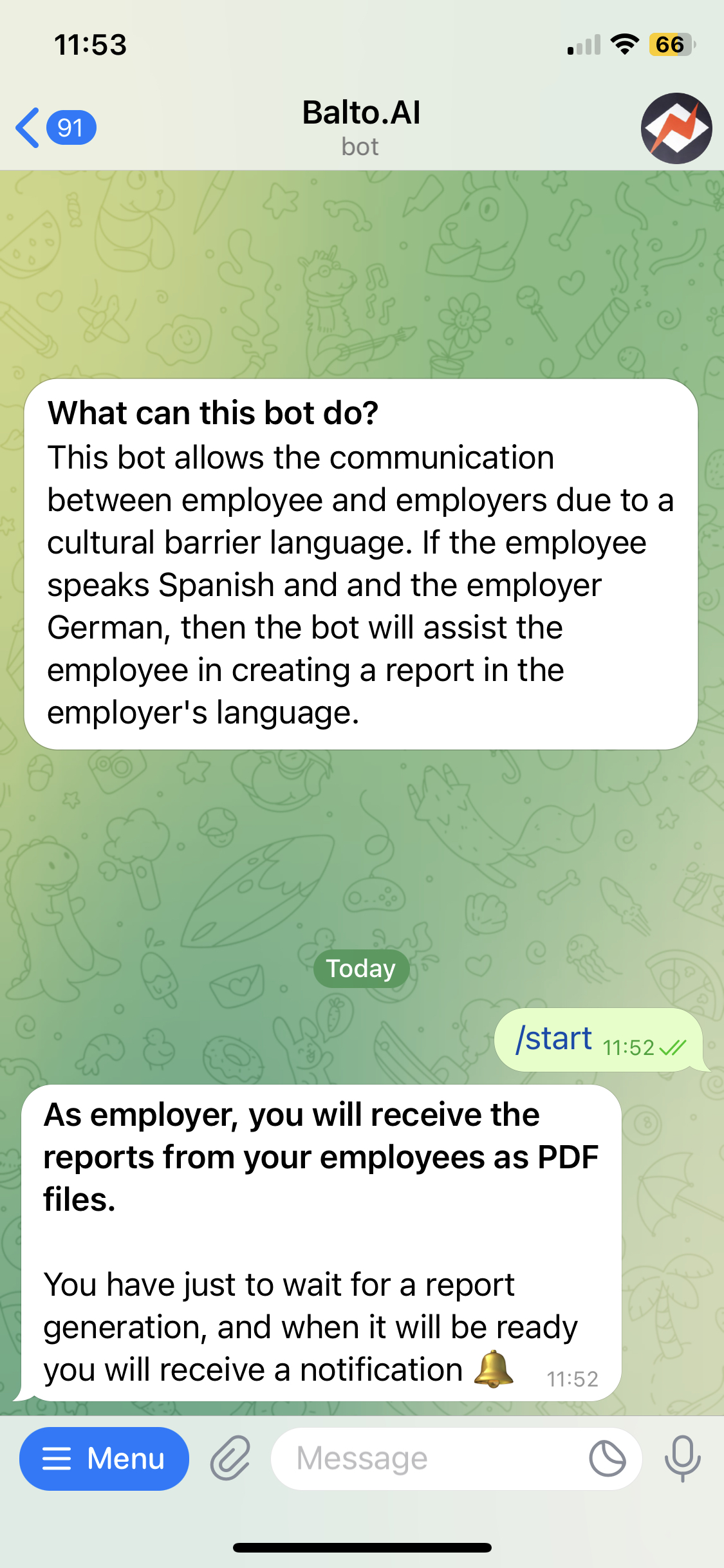
What it does
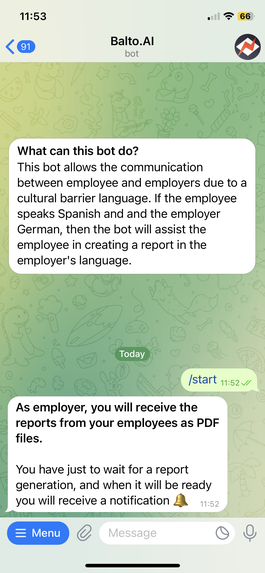
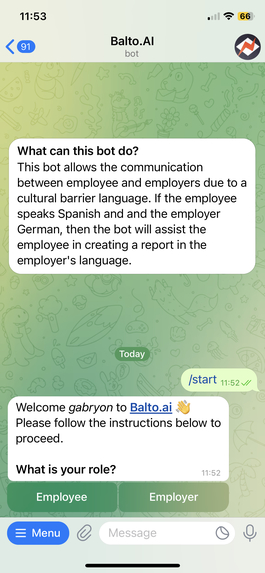
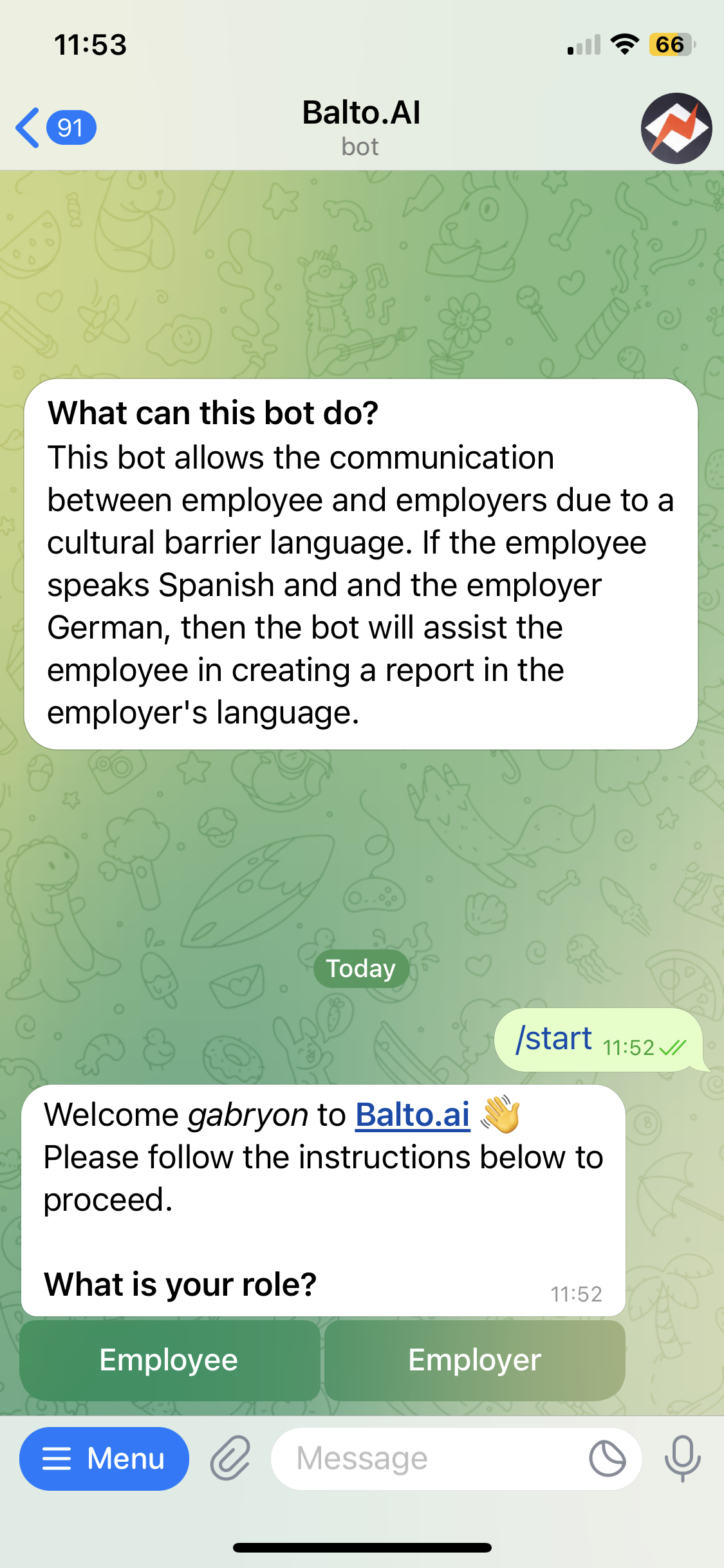
Employees get to use an interface they are very familiar with, a text messaging app. They upload there the data regarding a problem they solved, and after, the bot generates a report that contains both the original language of the employee and a translation to the employer's language. An accuracy metric for the translation is calculated, and also included in the report.
How we built it
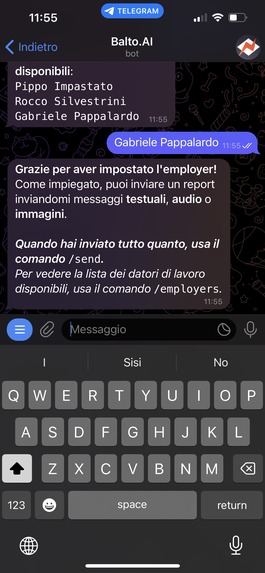
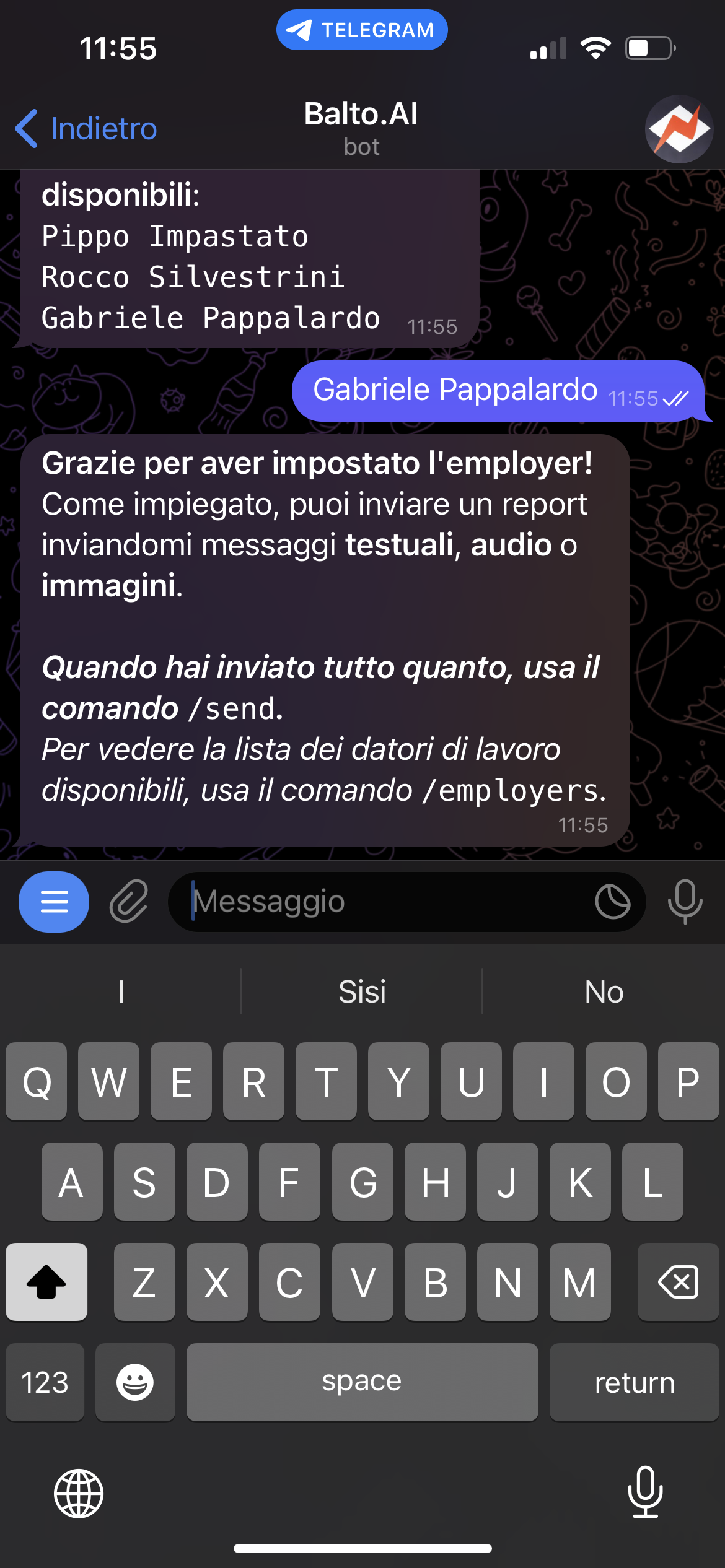
We developed a Telegram bot where the employees upload the data for a problem they solved for the company. The report may be some text or audio, and it can also include some pictures the employee might have taken. Once the bot receives the data, it is forwarded to our backend. In the backend, we used the OpenAI API to first summarize the report into bullet points, as it is easier for the employer to have a clear idea of what the employee did. Then, all the report text and bullet points are translated from the language of the employee to the language of the employer.
After that, we perform some statistical analysis to check how accurate the translation was. The method we chose was back translating the report text to the original language and comparing the two texts. We use again the OpenAI API to create embeddings for every sentence in both of the texts. These embeddings are then paired to its nearest neighbor by performing KNN analysis. Once they are paired like that, we get rid of outliers. This is because the translators do not respect the punctuation marks, so sometimes a sentence like 'Hello boss' may be back translated as 'Hello, boss' and then split into 'Hello' and 'boss'. Having this sentence split would be decreasing the score, but actually the meaning of the original text has not been lost. Once we have the pairs, we used a deep learning model (BLEURT) to compare how close two sentence embeddings are and generate a score (0 to 1) for every pair. We get rid of non-representative data (the algorithm we used sometimes gives results below 0 or over 1), and after calculate the mean score for all sentences, obtaining a final value for the text accuracy.
Once the score is calculated, the report is built in PDF, and then forwarded to the telegram chat of both the employee and the employer.
Challenges we ran into
We had to think how to make the gpt-model provide standard responses every time. Also making it translate from one language to another was an issue, as if you asked in English to translate a text in Spanish to Italian, it may translate it to English instead, but we solved that issue by first asking to translate the prompts.
Moreover, the communication between the telegram bot and the backend was a challenge, as we had to code some data transmission protocol between the two, which was not an easy task.
Coming up with some metric for the accuracy of the translation was a real challenge. We did some research on how it could be done and developed an algorithm for it using mathematical models and analysis.
Accomplishments that we're proud of
Having a minimum viable product in only one day, using API's we were not comfortable with before.
What we learned
How to make GPT models build standard outputs, how to create a metric for translation, how to build a telegram bot that uses a python backend.
What's next for Balto-ai
Scalability of the platform. Business and financial analysis in detail, as we only spent $0.30 doing the whole project and consider it is a great opportunity for both people looking for a job and companies attempting to increase their workforce

Log in or sign up for Devpost to join the conversation.