-
-
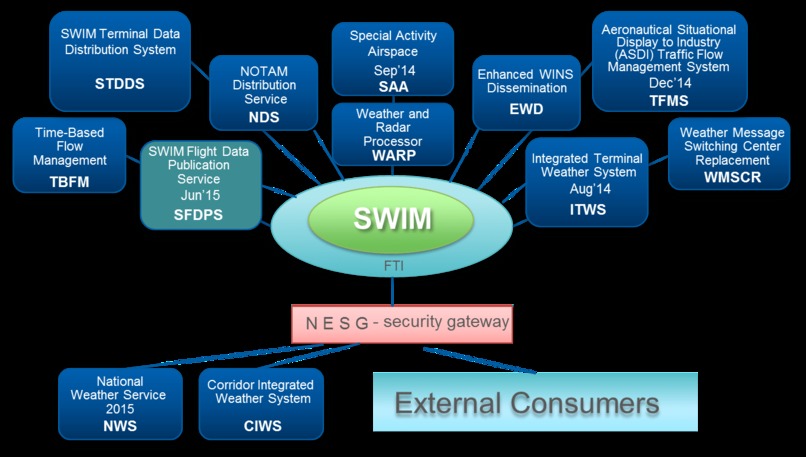
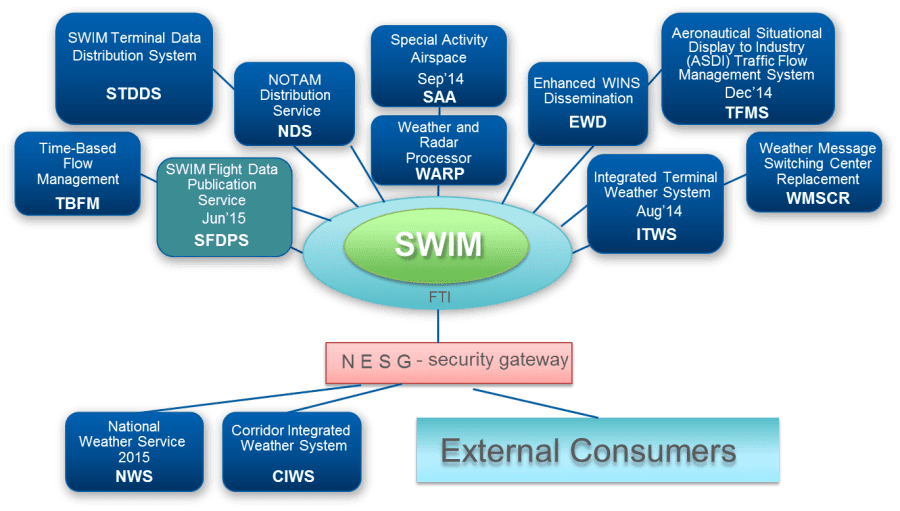
FAA's concept of operations for SWIM
-

CICD Pipeline

Inspiration
One of most difficult parts for Data Scientists to start their job is to build their environment. Most of them do not know or do not care how the underlying infrastructure to host all these cloud resources and/or services they require, like Databricks Workspaces, clusters, storage, etc. are built. And that means that somebody else would have to build the initial environment for them or they would be forced to learn and create it by themselves.
The first reaction is to build it manually using whatever portal the cloud provider has. But creating these complex environments manually leads to future problems. One misconfiguration could lead to a cascade of errors that ultimately would impact the results you are expecting from analyzing the data you are ingesting.
Initially it would take weeks or sometimes even months before you could get a properly configured and ready to use environment where you could ingest, analyze, and visualize the information you want.
It takes multiple iterations to get to that point and in my experience once the initial environment is created, nobody wants to touch it for fear of breaking it, especially if you are doing it manually.
The goal here is to reproduce these environments regardless of the stage in the development cycle. We want that level of consistency, so you never heard that bugs in production are not able to reproduce in Dev/Test. And let’s not forget about efficiency, these complex environments are not cheap they usually have multiple cloud resources involved in their architecture. That if left idle can easily cost you a lot!
So, there is a big opportunity here to help Data Scientists do their work faster and apply some best practices along the way.
What it does
We are going to use the System Wide Information Management (SWIM) Cloud Distribution Service (SCDS) which is a Federal Aviation Administration (FAA) cloud-based service that provides publicly available FAA SWIM content to FAA approved consumers via Solace JMS messaging. This project will allow us to have a clean Data Analytics environment connected to the System Wide Information Management (SWIM) Program which would allow us to analyze flight data in almost real time.
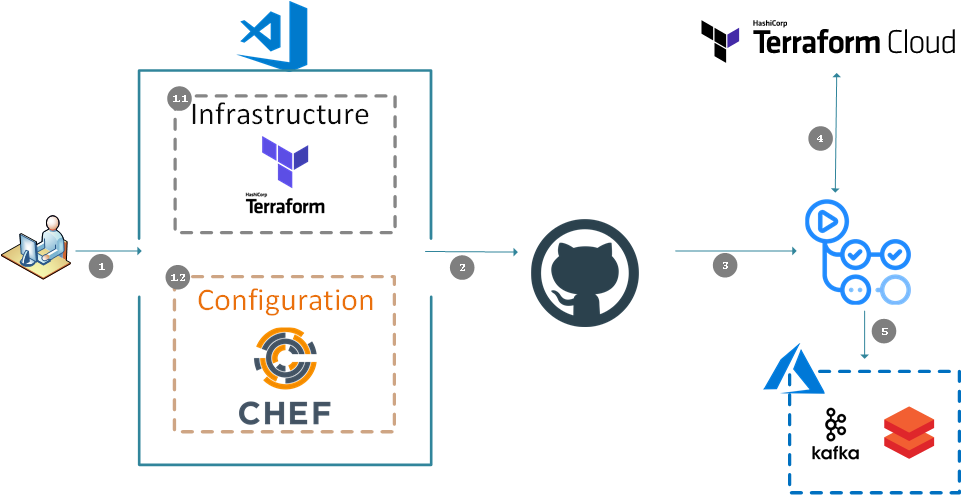
How we built it
This project shows how easy is to build Data Analytics environments using Chef Infra, Chef InSpec, Terraform, GitHub and the brand new Databricks resource provider.
Everything is done using Chef Manage, GitHub Actions, Terraform Cloud and GitHub Code Spaces so we can have all our development environment in the cloud, and we do not have to manage any of it.
We focused on automating these 3 categories:
Infrastructure itself - which includes all the initial networking, subnets, security groups, VMs, Databricks Workspace, Storage, everything.
Kafka - Now we are on the post provisioning configurations which includes Kafka installation, configuration along with its software requirements. SWIM required configuration to access specific data sources like TFMS. You know, having the right configuration files and in the right place. The solace connector to ingest the data and its required dependencies.
and finally, DataBricks - Which involves Cluster creation and configuration, required libraries like sparkXML to parse and analyze the data and import initial notebooks.
Challenges we ran into
The initial setup might take some good time. Even though we have a devcontainer having your tools Terraform, Chef, etc. properly configured with proper permissions and access takes some time. You need to have some sort of service account with right permissions to create, modify or delete cloud resources.
There is also some learning curve specially if you are not used to having infrastructure and configuration as code and the github flow.
Accomplishments that we're proud of
We were able to reduce the time to have these complex environments fully operational from weeks to minutes which is amazing! and since everything is code, we could replicate it basically anywhere.
We could even create disposable environments for quick testing/research you name it and if successful, integrate it with our production or main environment. We also get built in documentation for faster onboarding.
What we learned
It is fair to say that automation is key here. It is amazing the things you can achieve when you integrate all these tools together.
On the tooling part I know DevOps is not about tooling, but tooling is so much fun! especially when it works, and you see the results.
What's next for Automating Data Analytics Environments
- Integrate with other managed data services like HDInsights, Data Lake, etc.
- Extend the project to ingest other types of data like weather and others.
- Incorporate Hashicorp Vault for better secret management.







Log in or sign up for Devpost to join the conversation.