We are two ninth graders from Southern California
Colab Project Link
PDF Report
https://drive.google.com/file/d/1z2rFRhylF226jwmo8sg7ommsbH6F9joo/view?usp=sharing
Inspiration
Alzheimer’s Disease is often diagnosed only after cognitive decline has already become severe. Current clinical pipelines rely heavily on behavioral assessments and late‑stage symptoms, limiting opportunities for early intervention. We were motivated to explore whether AI could detect subtle neurological and cognitive patterns earlier, before diagnosis typically occurs.
Recent research suggests that structural brain changes and language use both reflect early neurodegeneration but these signals are rarely combined in a practical way. Our goal was to bridge that gap.
How We Built It
MRI Representation Learning
We trained a 3D convolutional autoencoder on raw structural MRI scans. This self‑supervised model compresses high‑dimensional brain volumes into compact embeddings that preserve key neuroanatomical structure while removing noise. These embeddings power both classification and regression tasks efficiently.
Language Modeling
Speech transcripts from the Pitt Corpus were cleaned and embedded using a pretrained SentenceTransformer (MiniLM), producing fixed‑length semantic vectors that reflect fluency, coherence, and lexical choice.
Unimodal Models
Each modality is processed independently using a lightweight feedforward neural network optimized for:
- Speed
- Reproducibility
- Interpretability
Confidence‑Weighted Late Fusion
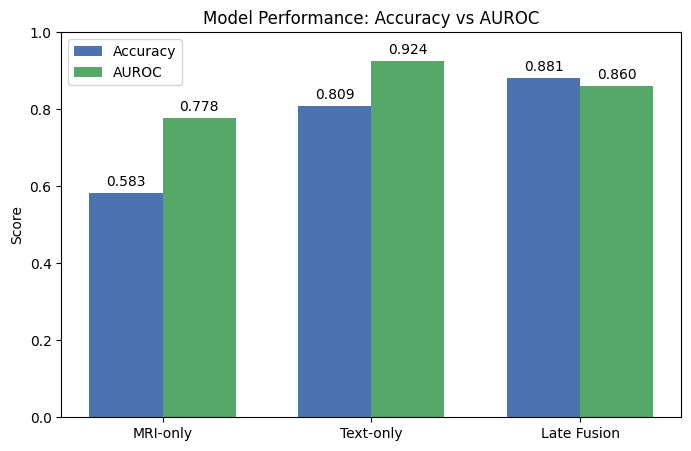
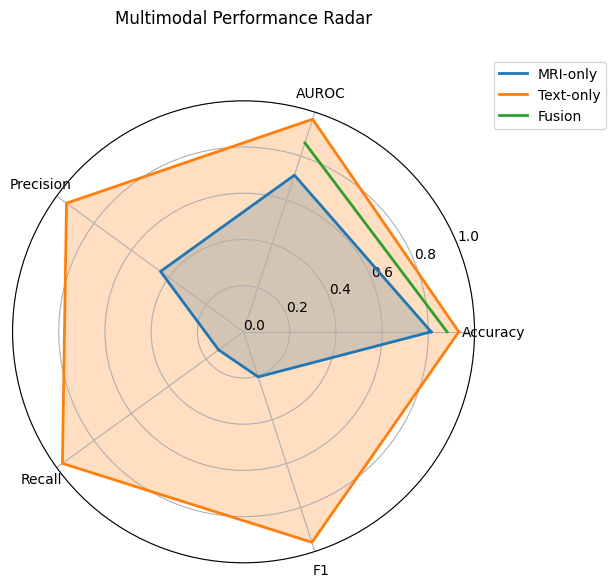
Because MRI and speech data come from different populations, we implemented dataset‑level late fusion. Each model’s AUROC determines its contribution, allowing higher‑confidence modalities to influence final performance more strongly — without forcing subject alignment.
CDR Severity Assessor
We trained three regression models to identify CDR scores for different subjects. CDR is determined by the following system:
- 0: Control patient - not demented
- 0.5: Mild Cognitive Impairment (MCI)
- ≥ 1: Dementia
Challenges We Faced
- MRI and speech datasets lacked shared subjects, preventing per‑sample multimodal inference.
- MRI scanner variability and language model bias required careful normalization and evaluation.
- First AIML project for both of us.
What's Next
While this project has been submitted to the hackathon, it is far from finished. Some of our future plans include: mapping language data to parts of the brain being deteriorated, finding and applying a dataset that has both language and MRI data, and refining and experimenting with the code to improve AUROC and accuracy metrics.



Log in or sign up for Devpost to join the conversation.